Cloud Architecture & Design
Security, Governance & Compliance
Cost Optimization & FinOps
Networking & Connectivity
Infrastructure as Code & Automation
CI/CD, Testing & Release Engineering
Containers, Kubernetes & Serverless
Observability, Monitoring & Incident Response
Reliability Engineering & Performance
Leadership, Mentoring & Stakeholder Management
100
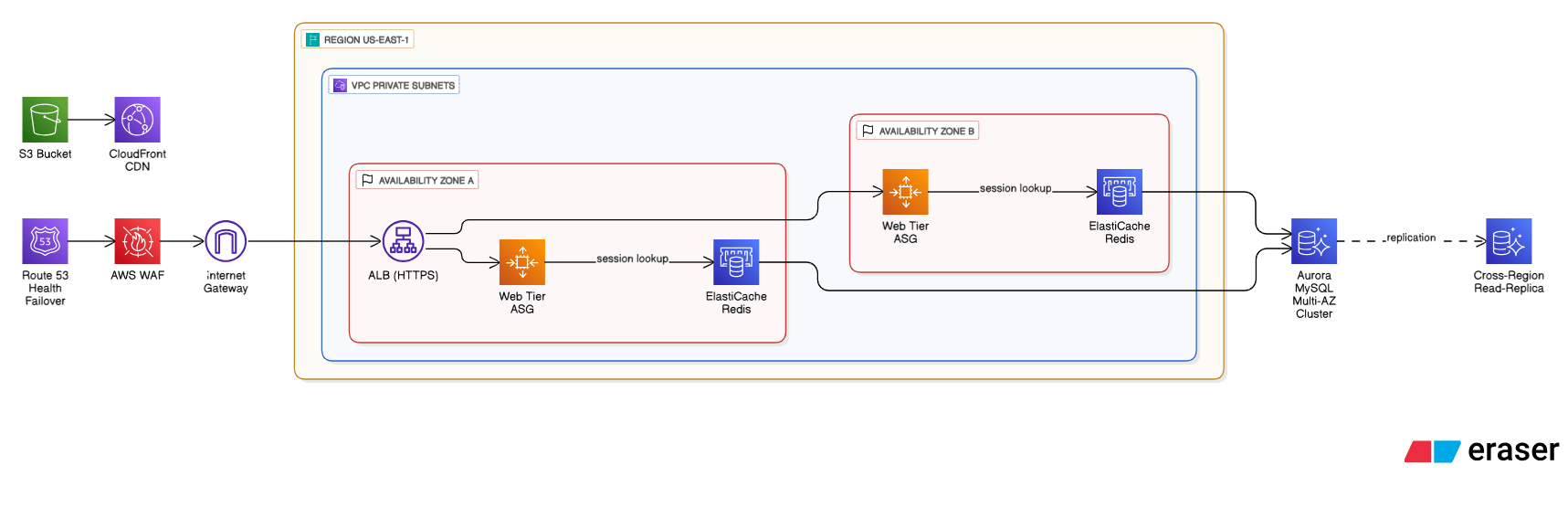
Describe a reference architecture you’ve used for a multi-tier, highly available web app in AWS.
I place a stateless web tier in private subnets behind an ALB that spans at least two AZs, back it with Auto Scaling groups, add an ElastiCache Redis layer for sessions, store objects on S3 + CloudFront, and run Aurora MySQL Multi‑AZ for data plus a cross‑Region read‑replica. Route 53 health‑based failover and WAF round out security and DR.
100
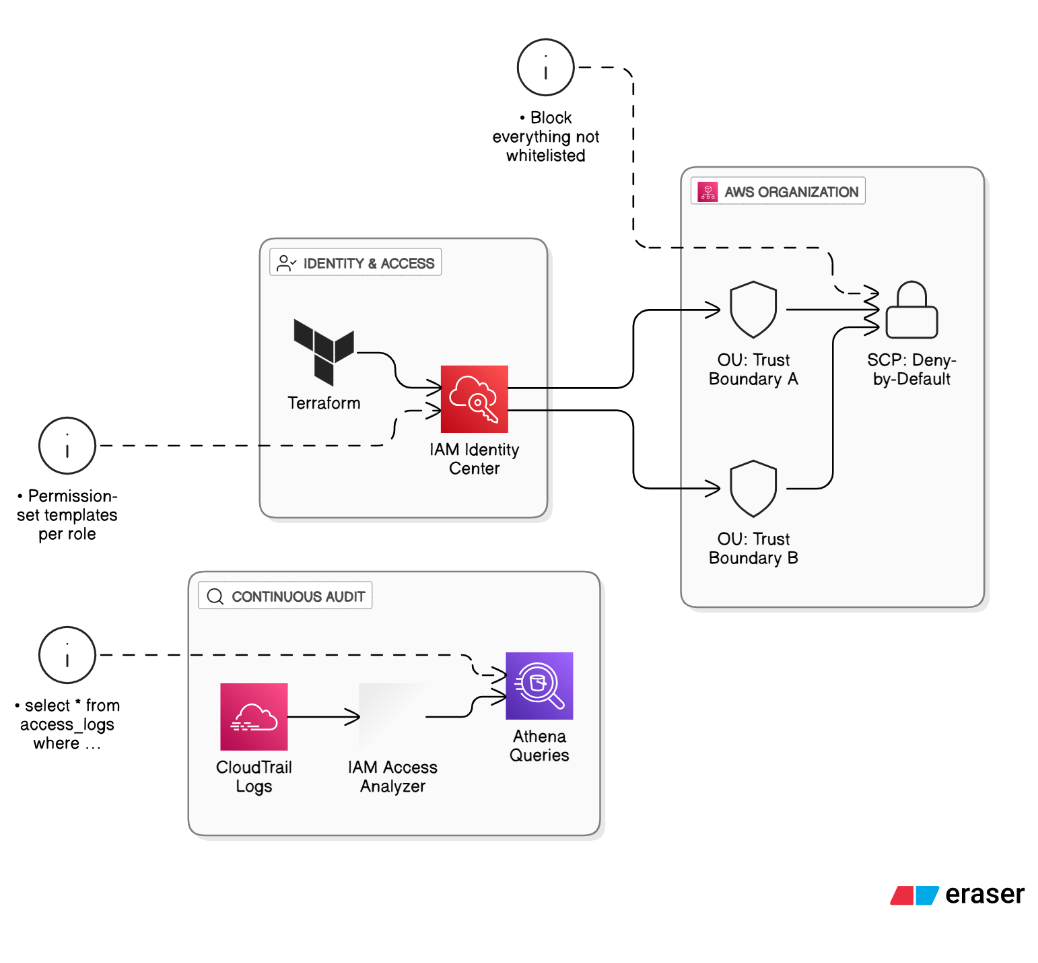
How do you enforce least‑privilege access at scale in an AWS Organization with hundreds of accounts?
Structure OUs by trust boundary, attach deny‑by‑default SCPs that whitelist actions, use AWS IAM Identity Center with permission‑set templates rolled out via Terraform, and continuously audit access with IAM Access Analyzer + CloudTrail Athena queries.
100
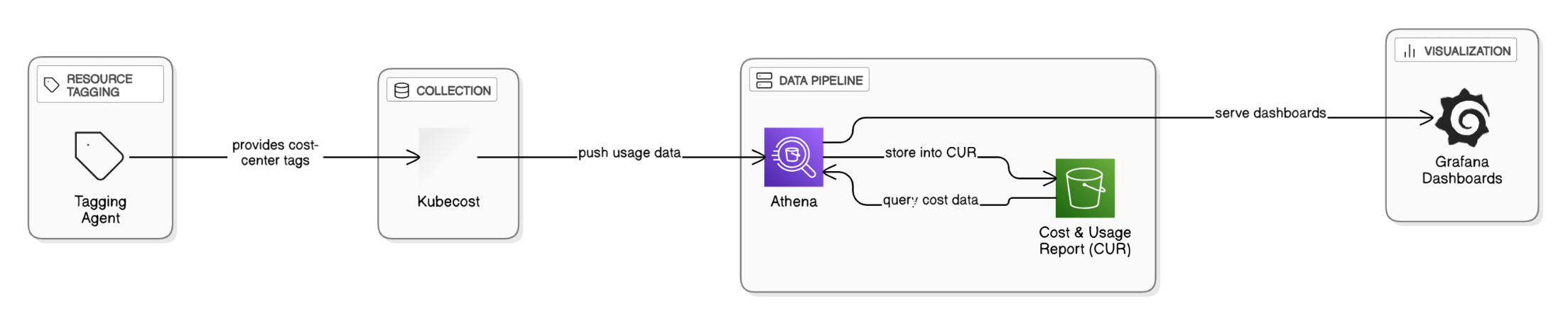
How do you build a cost‑allocation model for shared EKS clusters?
Deploy Kubecost to collect namespace & label usage, push data to CUR via Athena, tag shared cluster resources with cost‑center, and expose Grafana dashboards for show/charge‑back.
100
Detail the packet flow from an on‑prem client to an AWS‑hosted private ALB across Direct Connect plus Transit Gateway.
The client routes over DX to a VGW, BGP advertises on‑prem prefixes, traffic enters TGW core, TGW route‑table sends to VPC subnet, SG permits 443 to ALB ENI, ALB forwards to targets; responses take the reverse path. DX BFD gives sub‑second failover.
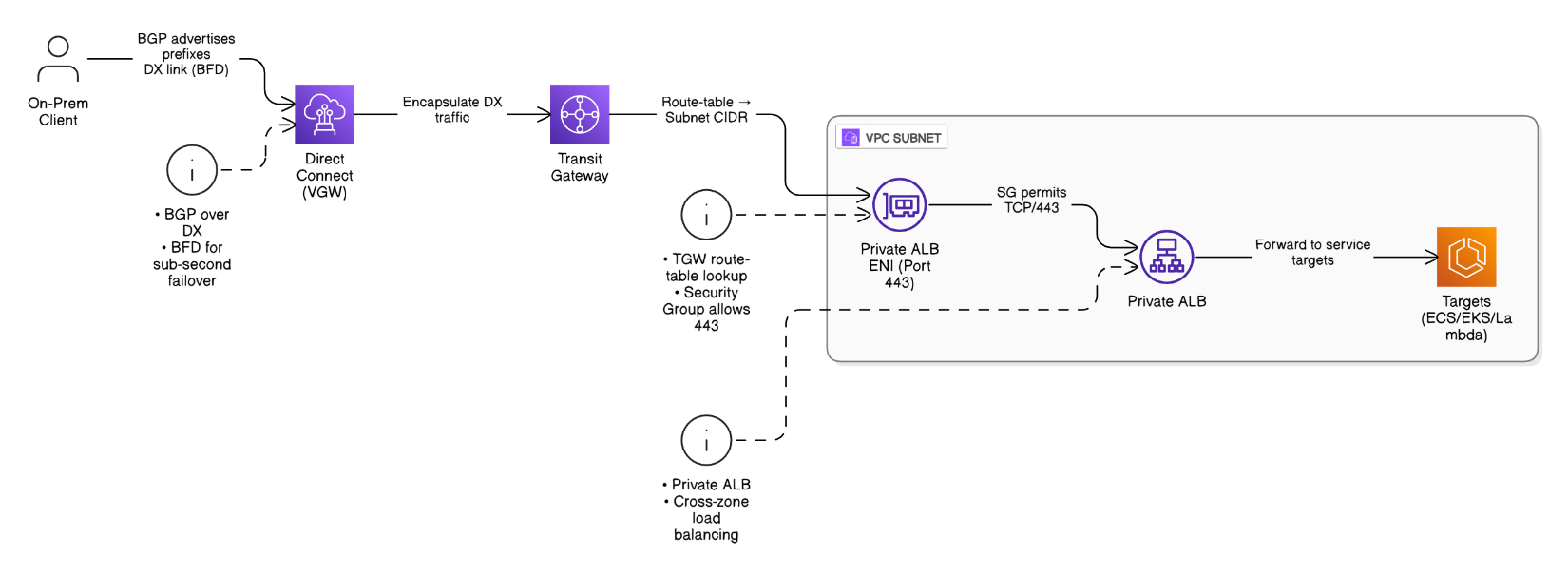
100
Contrast Terraform, AWS CDK, and CloudFormation for enterprise adoption.
Terraform is cloud‑agnostic with a rich module registry; CDK offers imperative constructs in TypeScript/Python that synthesize to CloudFormation; CloudFormation is native, mature, and integrates with StackSets. Choose by portability needs and developer skill set.
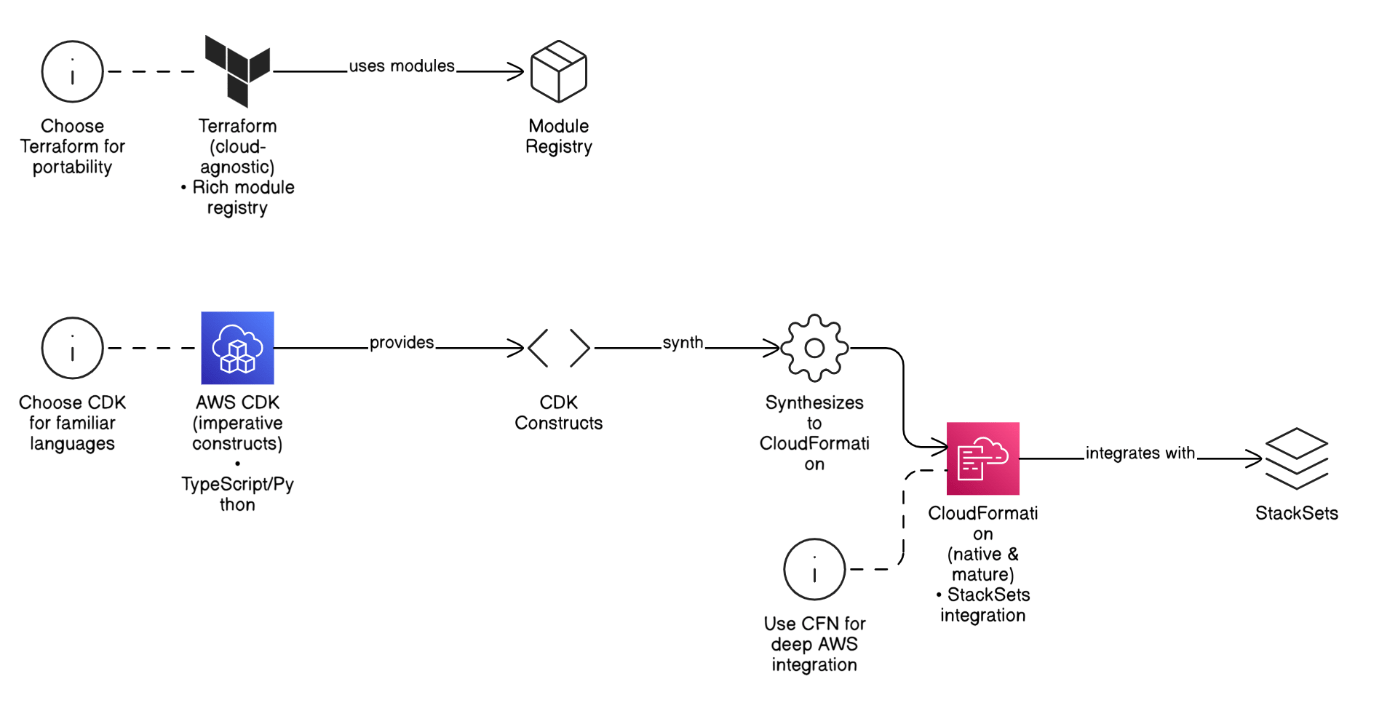
100
Compare Spinnaker, Argo Rollouts, and CodePipeline for progressive delivery in AWS.
Spinnaker is multicloud, heavy but feature‑rich, built‑in canary analysis; Argo Rollouts is lightweight K8s‑native with CRDs; CodePipeline is managed, low‑code, limited deployment strategies. Choose by platform breadth and team skill.
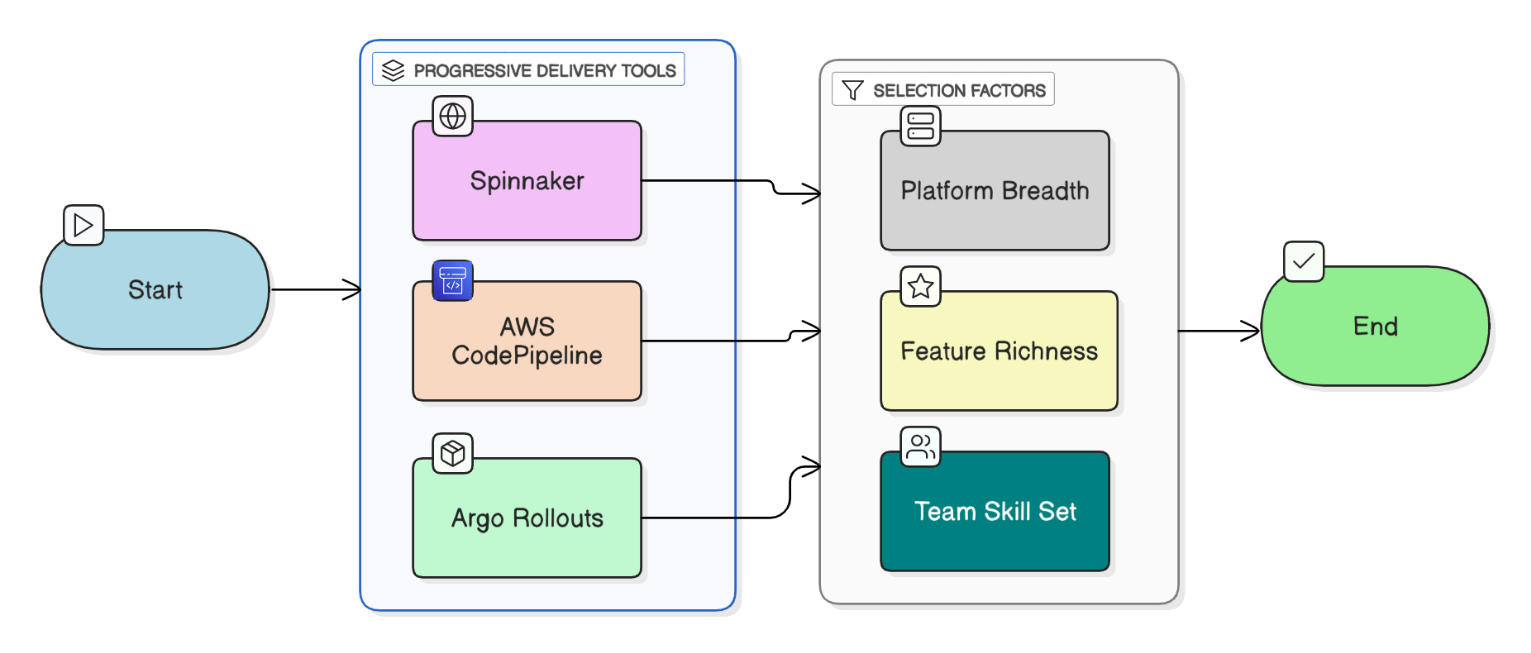
100
Describe the control‑plane high‑availability model for EKS and its SLA implications.
EKS runs three masters across AZs, etcd encrypted, AWS manages patching; SLA 99.95 %, but worker‑node and application HA remain customer responsibility.
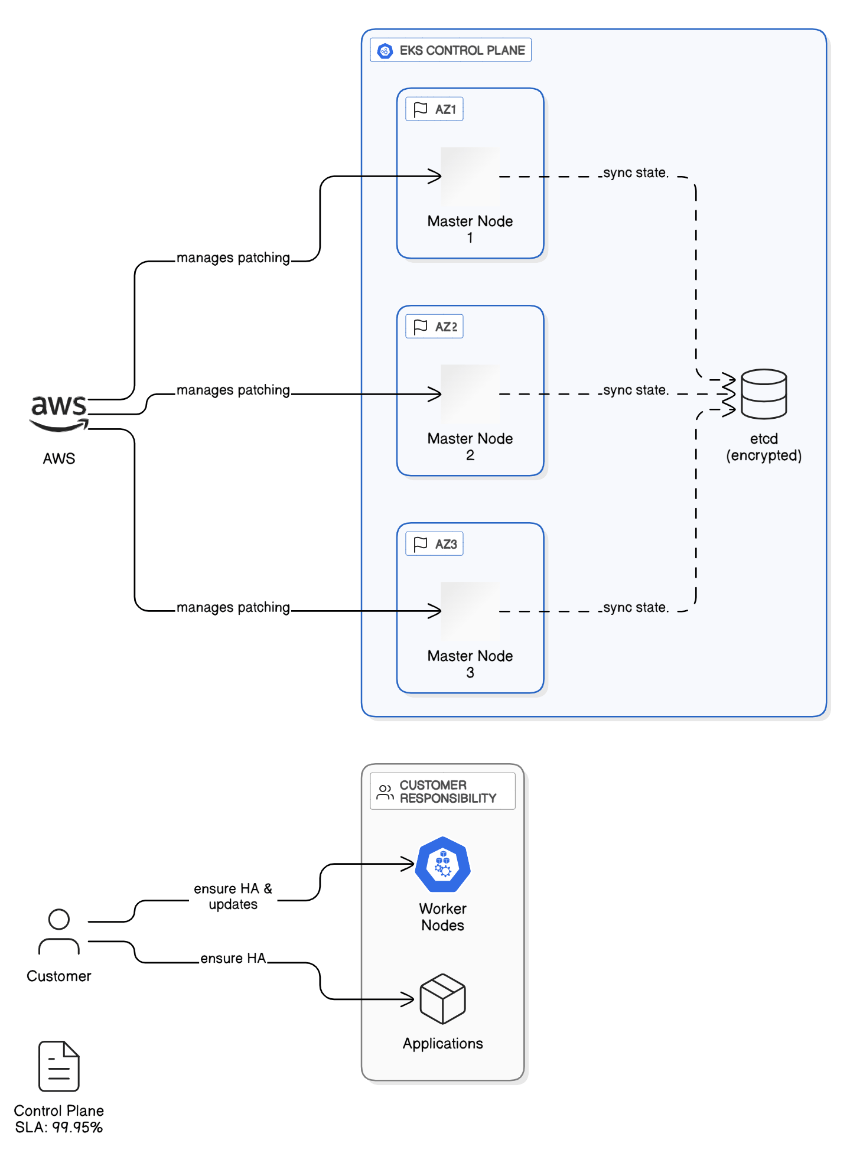
100
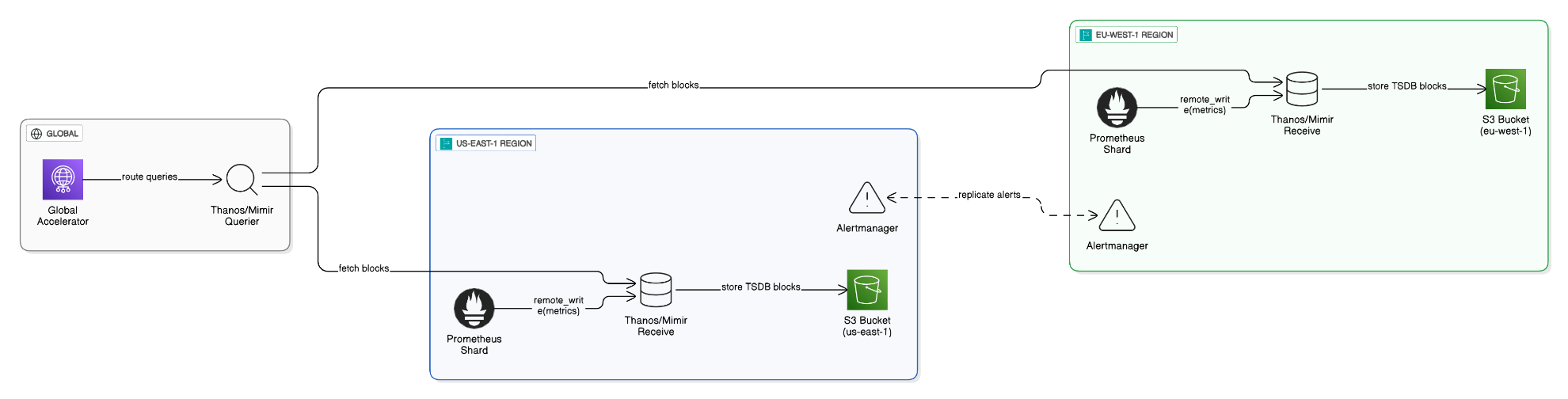
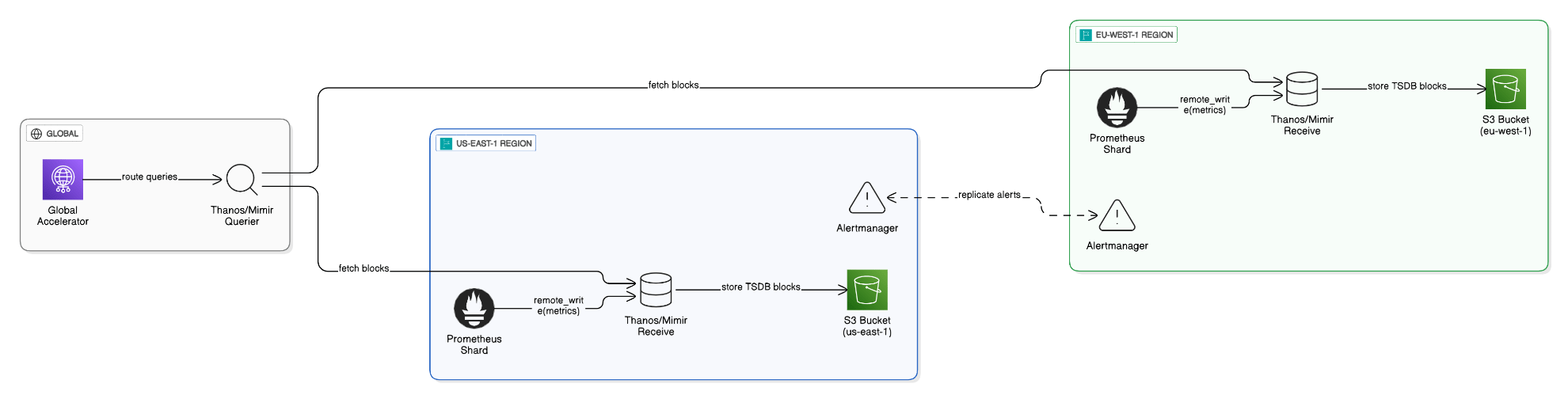
How do you design a multi‑Region metrics pipeline with sharded Prometheus and Thanos or Mimir?
Deploy regional Prometheus shards, remote‑write to Mimir/Thanos Receive, store blocks in S3, query via Thanos Querier behind Global Accelerator, and replicate alerts per Region.
100
How do you model and test for cascading failure scenarios in micro‑services?
Build dependency graph, use Gremlin to inject latency faults, validate circuit‑breakers open, and adjust retry budgets.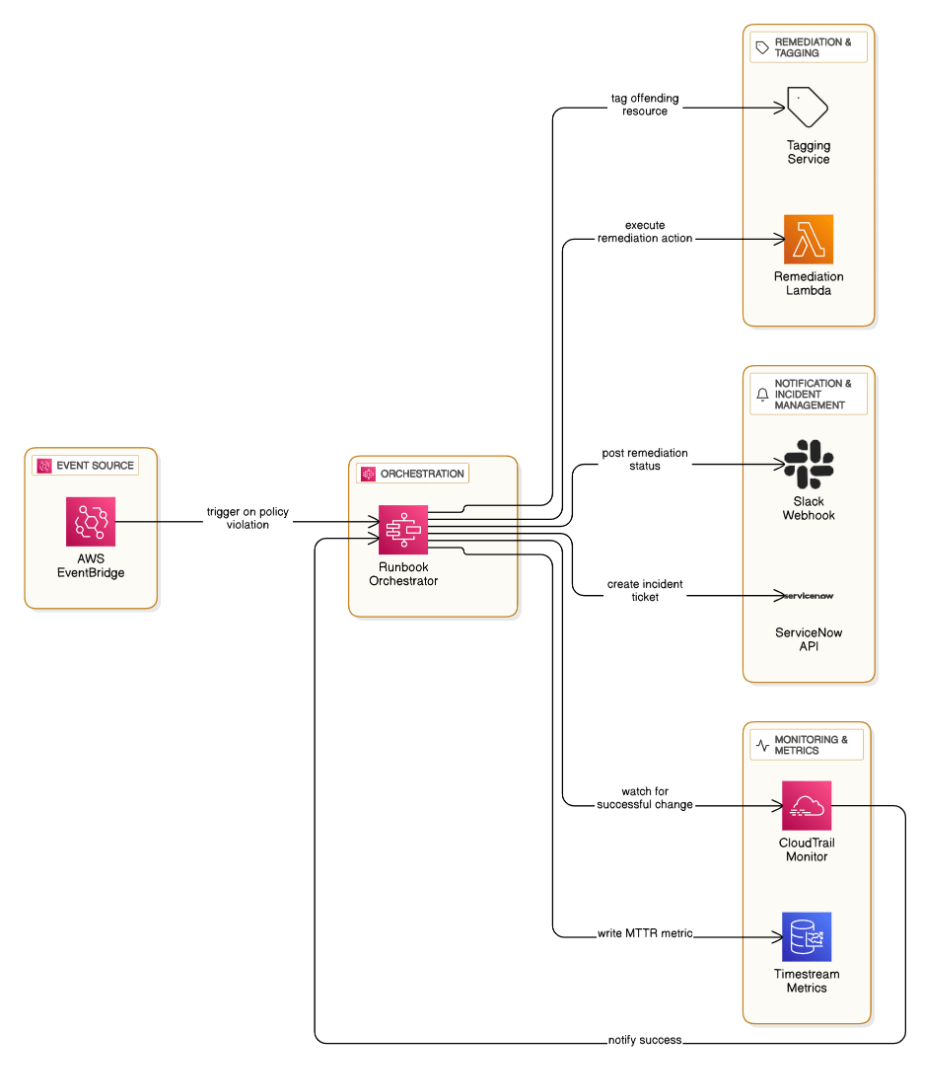
100
How do you bridge the gap between platform engineering and application teams with differing priorities?
Form a platform guild, provide paved‑road templates, hold office hours, and measure adoption KPIs to show value.
200
How do you decide between multi‑account, multi‑Region, and multi‑VPC isolation models?
Use threat‑model and compliance to set boundaries: separate accounts for differing trust or billing domains enforced by SCPs, multi‑Region only when latency/sovereignty demands it, and multiple VPCs for network segmentation when a shared account’s guardrails suffice. Connect with TGW or PrivateLink.
200
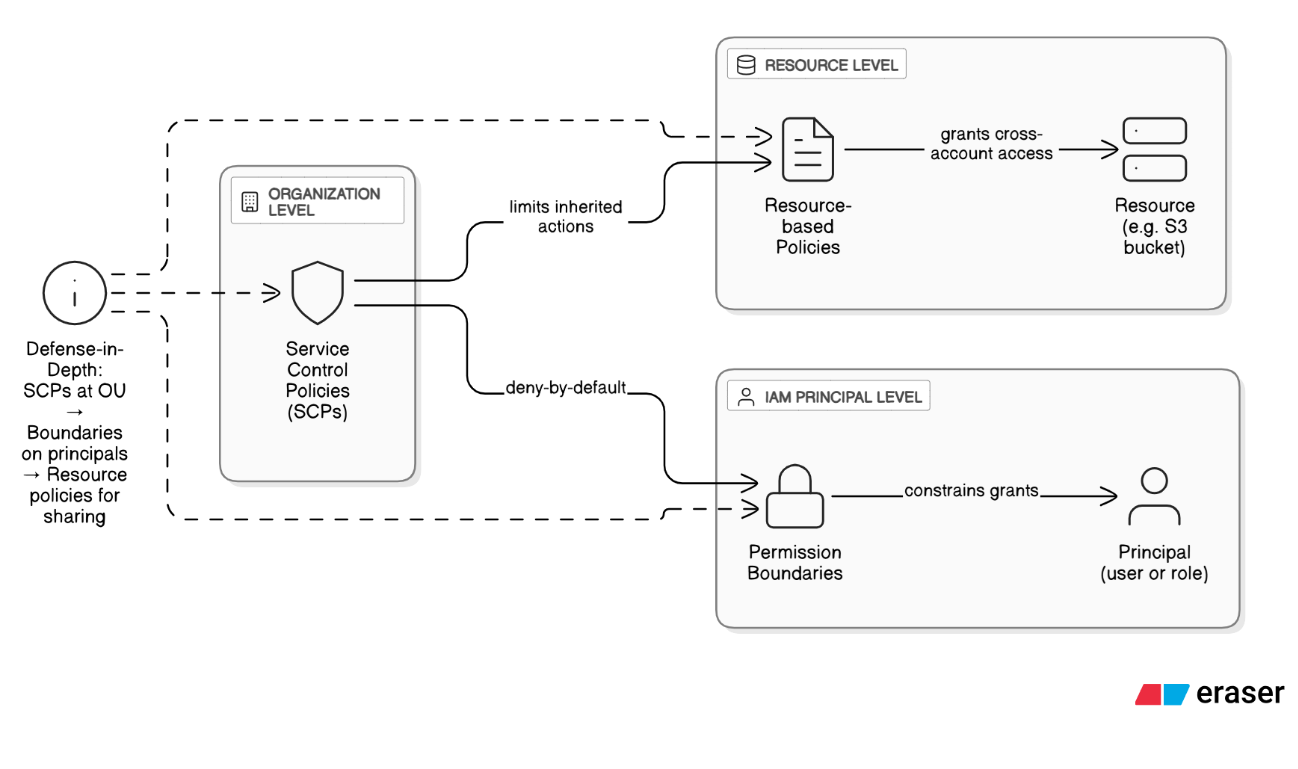
Contrast Service Control Policies (SCPs) with permission boundaries and resource‑based policies.
SCPs set the outer-most guardrail at the account/OU level; permission boundaries limit what a principal can self‑grant; resource policies control cross‑account sharing. Combine them for defense‑in‑depth: SCP for org mandates, boundaries for delegated IAM, resource policies for sharing data.
200
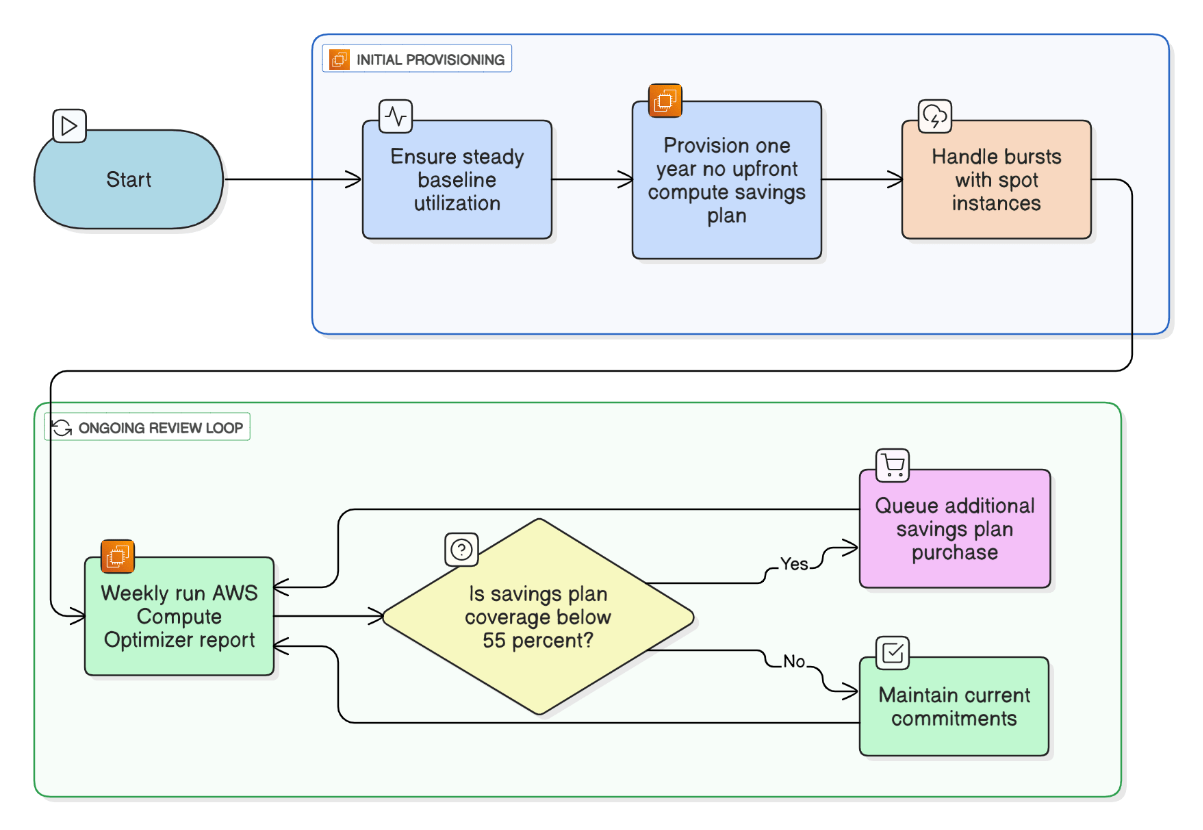
Walk me through an RI/Savings Plan purchasing strategy for a dynamically scaling workload.
Baseline 60 % steady utilization with 1‑yr no‑upfront Compute SP, burst on Spot, review weekly with Compute Optimizer, and queue SP purchases when coverage <55 %.
200
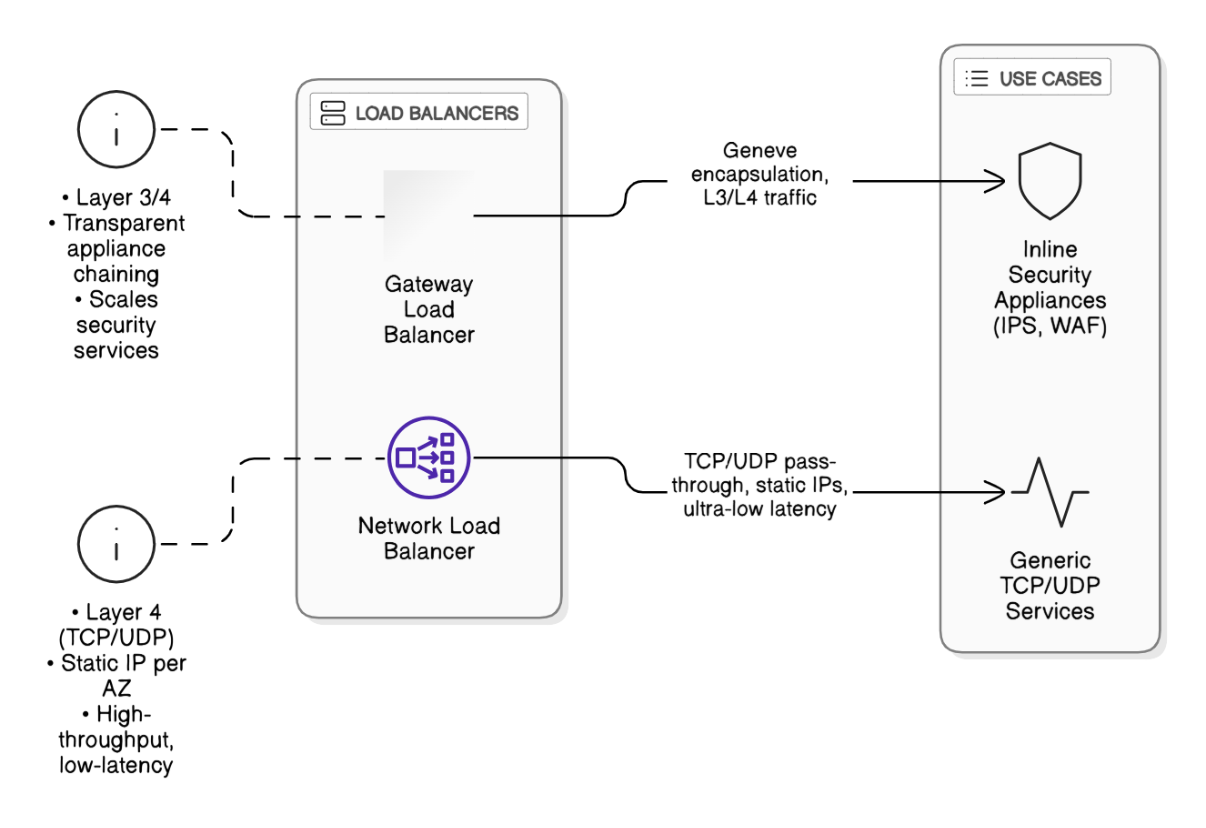
Explain how Gateway Load Balancer differs from NLB and when to use each.
GWLB sits at L3/L4, encapsulates traffic in Geneve for inline appliances (IPS, WAF), supports transparent insertion. NLB offers ultra‑low latency TCP/UDP L4 with static IPs. Choose GWLB to scale security appliances, NLB for generic high‑throughput pass‑through.
200
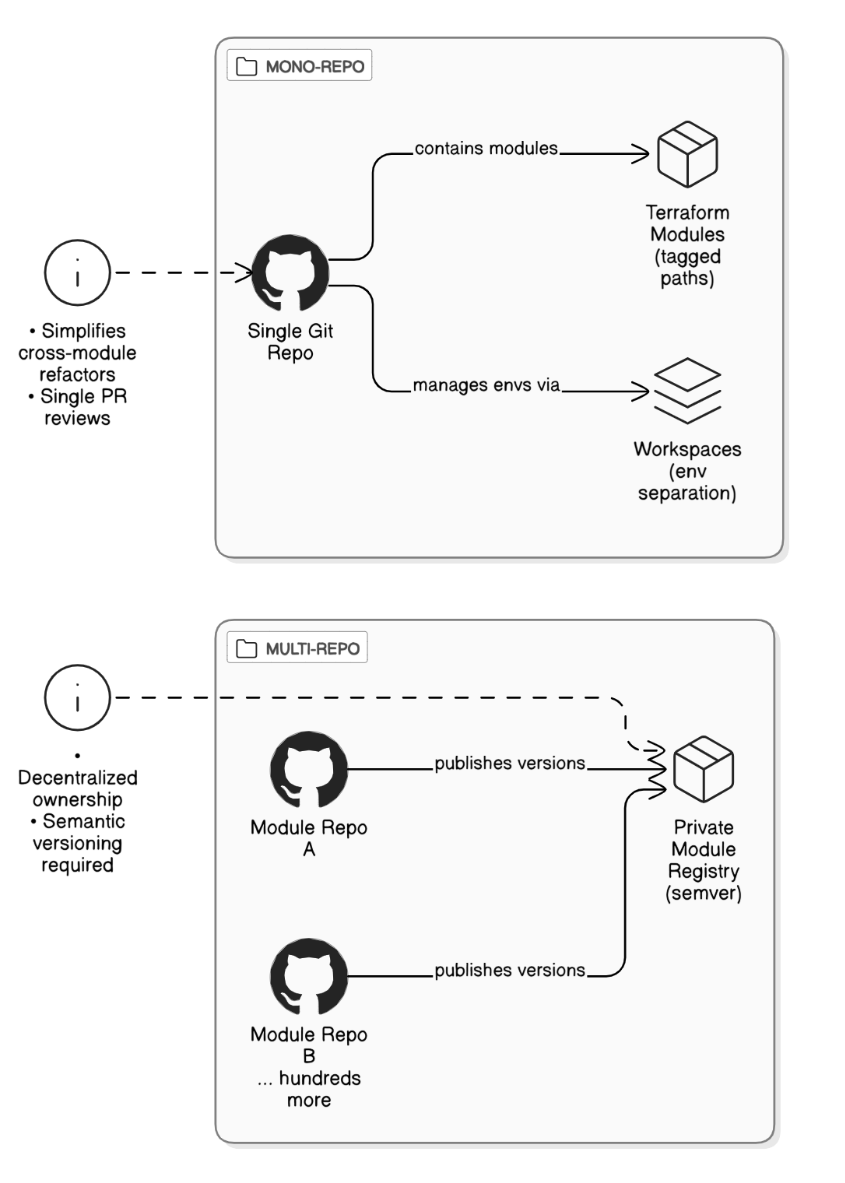
How do you structure a mono‑repo versus multi‑repo setup for hundreds of Terraform modules?
Mono‑repo simplifies cross‑module refactors and single PR reviews; tag modules and use workspaces for env separation. Multi‑repo suits decentralized ownership; use semantic versioned modules in a private registry.
200
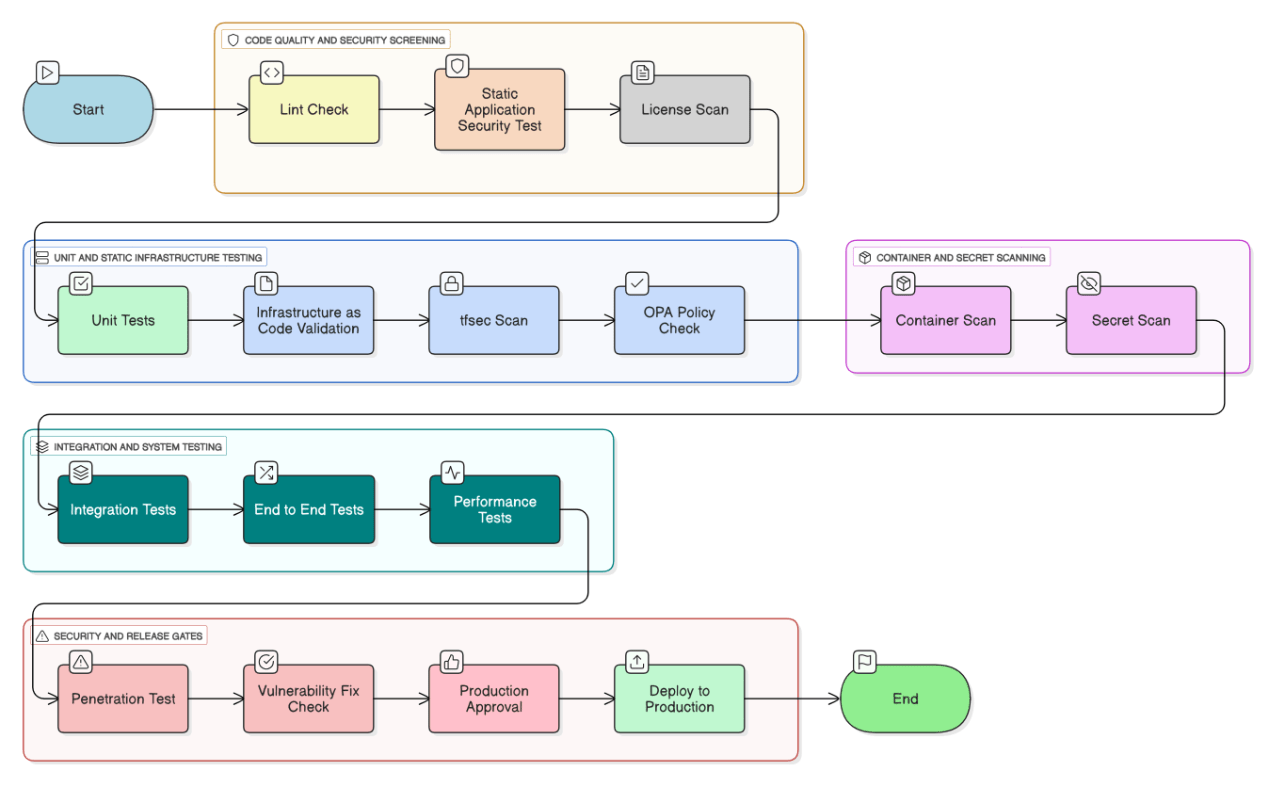
How do you design a pipeline that enforces the “16 security gates” from commit to production?
Stage sequence: lint → SAST → license scan → unit tests → IaC validate → tfsec → OPA policy → container scan → secret scan → integration tests → e2e → performance → pen‑test → vulnerability fix check → prod approve → deploy.
200
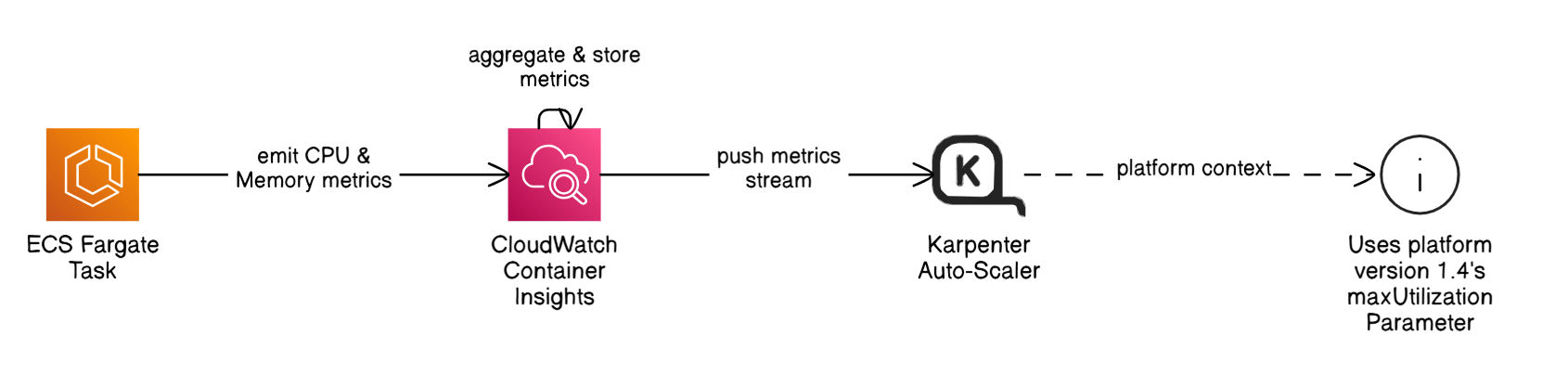
How do you right‑size Fargate tasks automatically?
Enable CloudWatch Container Insights, feed metrics into Karpenter to adjust CPU/memory, use platform version 1.4 maxUtilizationParameter, and set `--memory-swap` to zero for security.
200
Explain the difference between SLOs, SLIs, and error budgets with a concrete example.
SLI: p99 request latency. SLO: 99.9 % of requests <300 ms per 30 days. Error budget: 43 m per 30 days. Burn alerts trigger at 10 % budget used per hour.
200
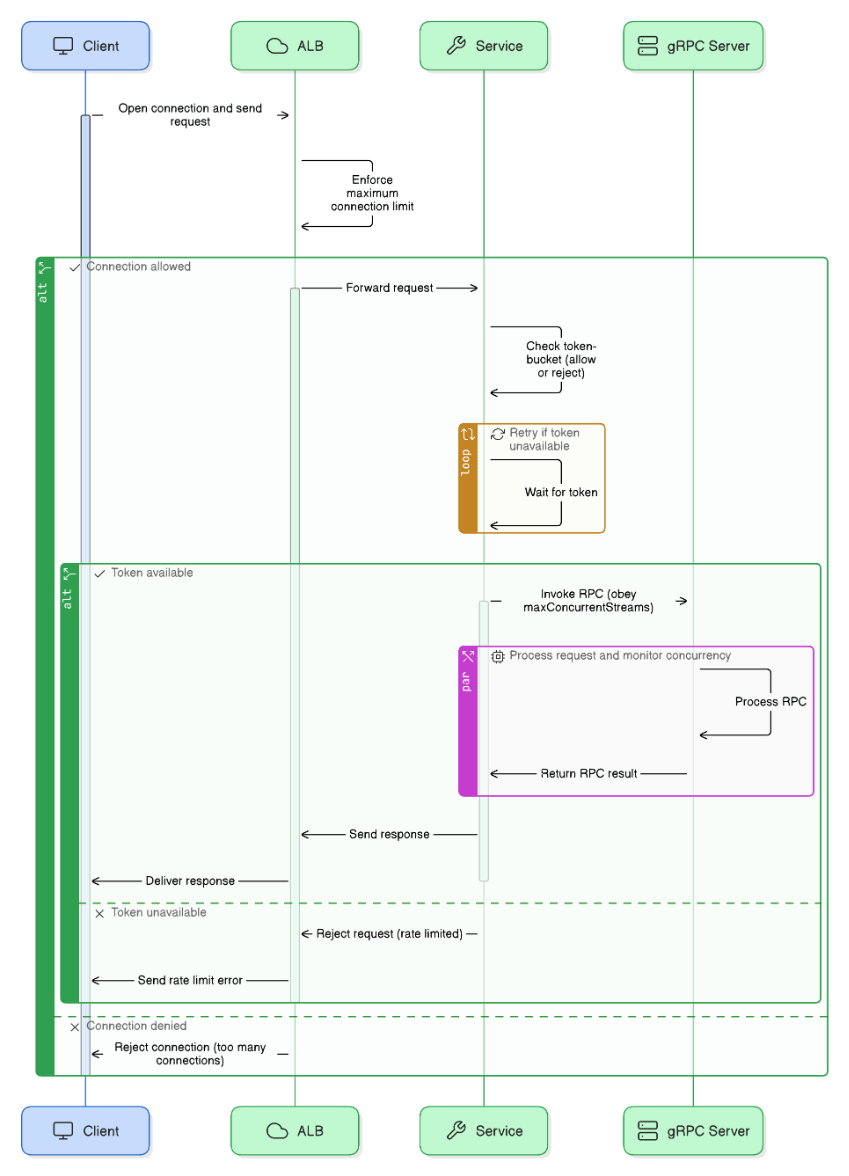
Discuss adaptive concurrency control techniques in high‑throughput APIs.
Implement token buckets, shed load via ALB max‑connection settings, and use gRPC `maxConcurrentStreams`.
200
Describe an architectural decision you reversed after receiving new data. How did you manage stakeholder expectations?
Switched from Kafka to Kinesis after cost study; wrote a decision record, presented benchmarks, gained consensus, and managed migration roadmap.
300
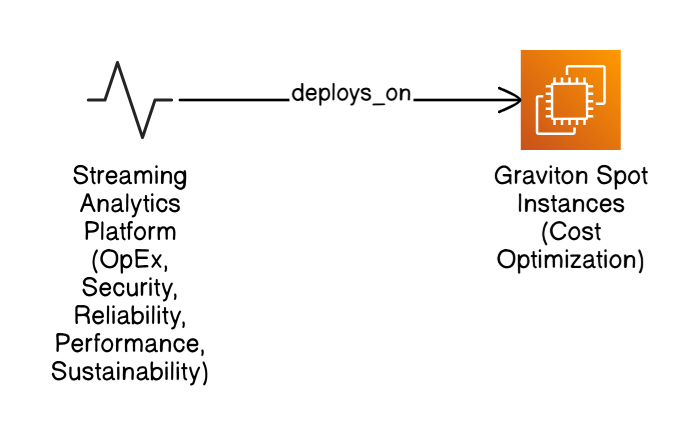
Walk me through the well‑architected pillars and give a recent example where you knowingly traded off one pillar for another.
Pillars: Operational Excellence, Security, Reliability, Performance Efficiency, Cost Optimization, Sustainability. In a streaming analytics platform I chose Graviton Spot instances (cost pillar) knowing p95 latency rose slightly, a conscious Performance‑vs‑Cost trade that still met SLOs.
300
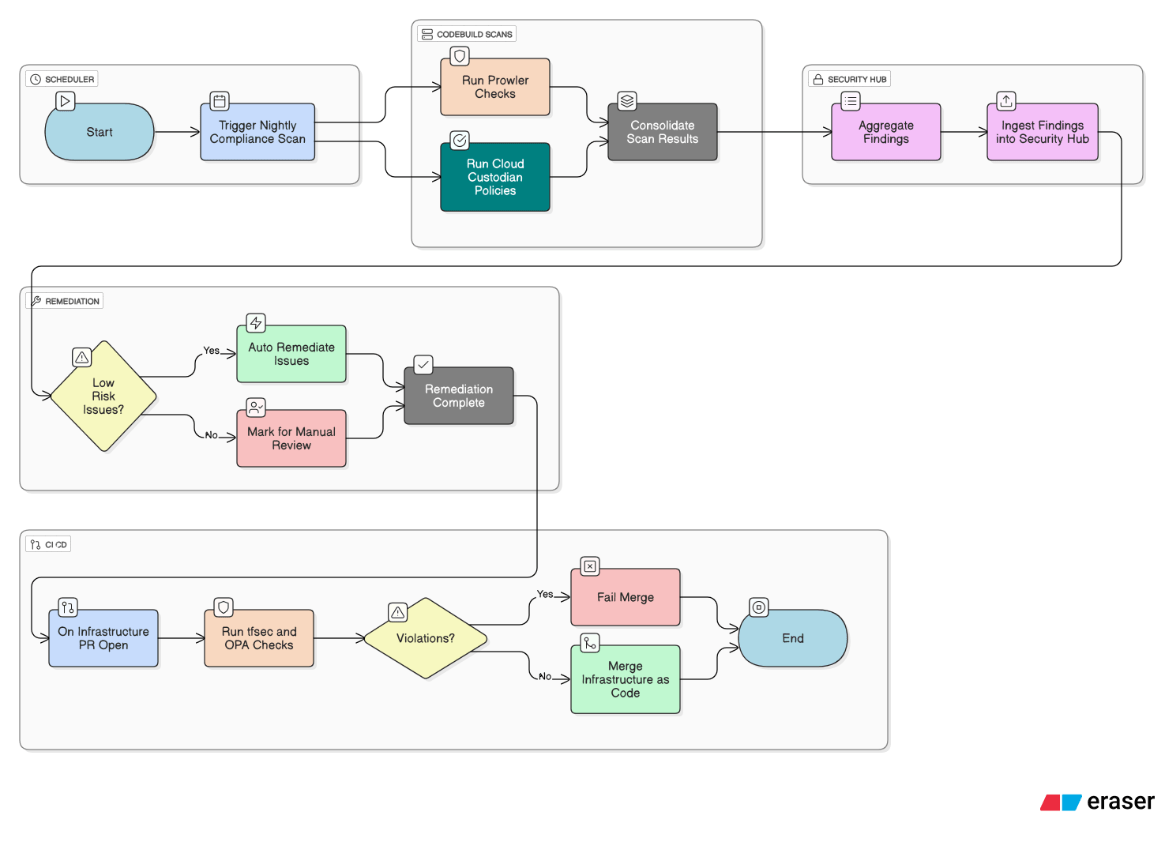
Explain how you would implement continuous compliance scanning against CIS Benchmarks using open‑source tooling.
Run Prowler and Cloud Custodian nightly via CodeBuild in each account, push findings to Security Hub, auto‑remediate low‑risk issues with Lambda, and gate all IaC merges with tfsec/OPA checks to prevent drift.
300
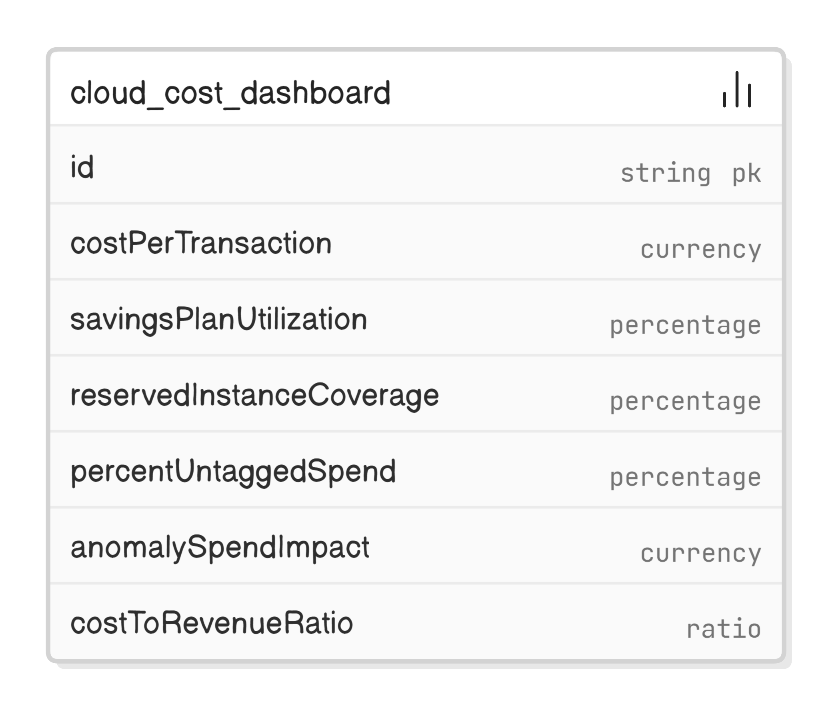
What KPIs would you expose to the business to drive cloud cost accountability?
Cost per transaction, Savings Plan utilization, Reserved Instance coverage, % untagged spend, anomaly spend impact, and cost‑to‑revenue ratio.
300
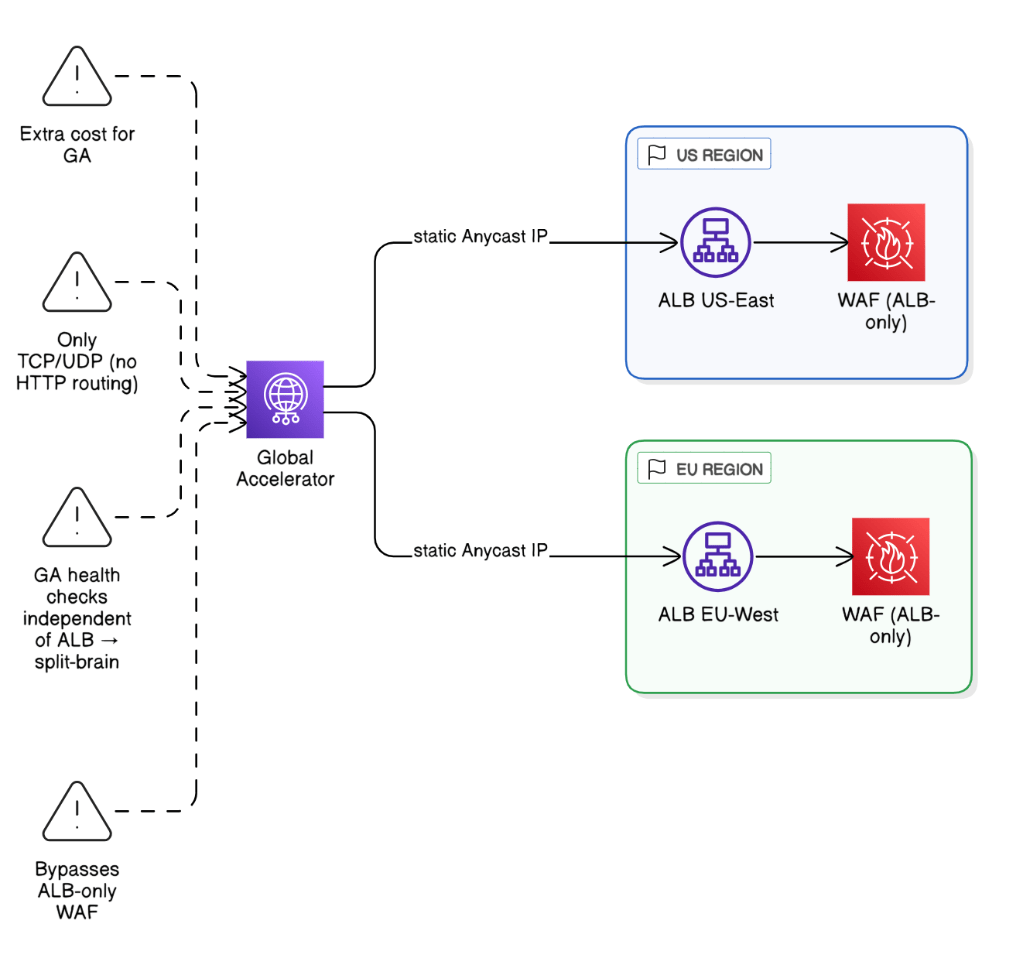
What are the pitfalls of using AWS Global Accelerator in front of multi‑Region APIs?
Extra cost, only TCP/UDP not HTTP routing rules, GA health checks independent of ALB checks can create split brain, and GA bypasses regional WAF if WAF is ALB‑only.
300
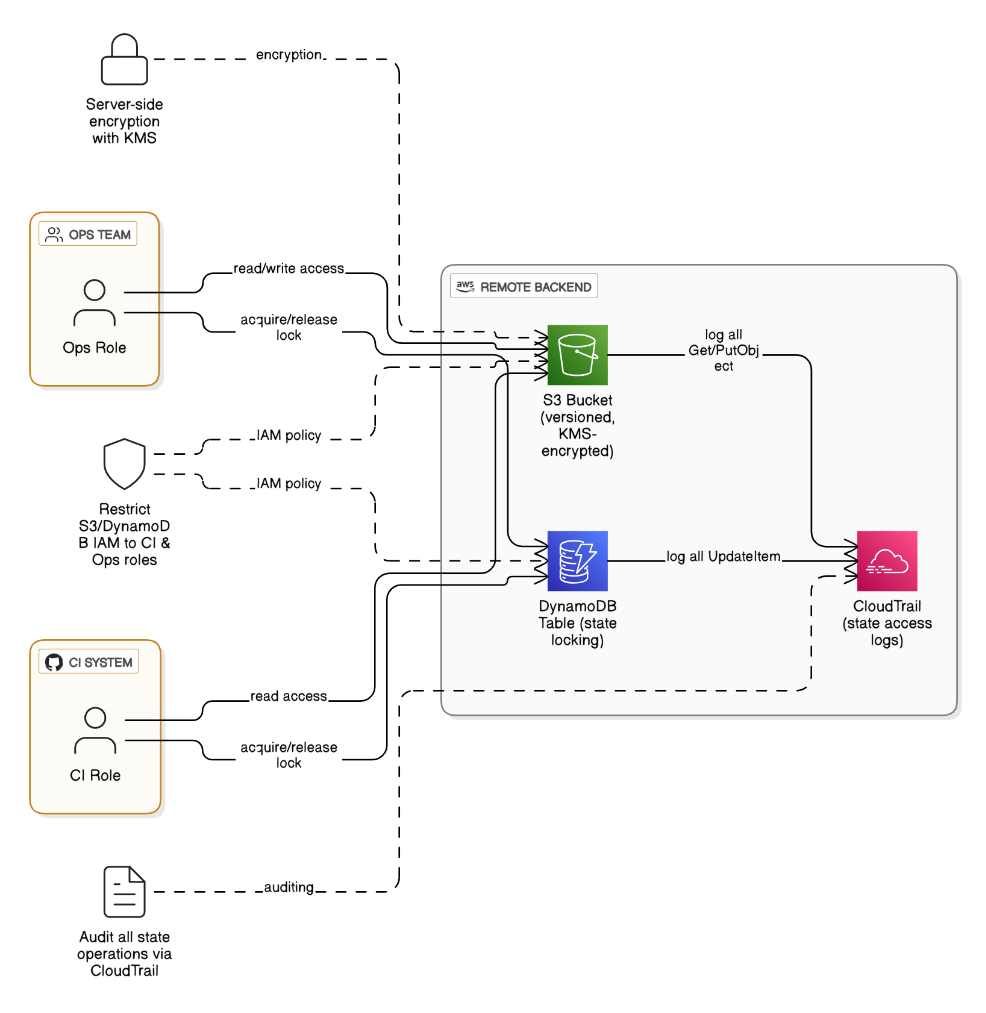
Explain a secure workflow for managing Terraform state in an org with strict segregation of duties.
Store state in versioned, KMS‑encrypted S3, DynamoDB locking, restrict bucket IAM to CI role, enable server‑side encryption, and audit with CloudTrail. Developers only run `terraform plan` via remote backend, ops role executes `apply`.
300
Explain strategies for running integration tests on ephemeral environments provisioned per PR.
Spin up short‑lived namespaces via Terraform, run tests with pytest hitting service endpoints, snapshot DBs, and auto‑destroy resources post‑run to save cost.
300
Explain how Karpenter differs from Cluster Autoscaler and what trade‑offs it introduces.
Karpenter launches nodes directly via EC2 API, choosing optimal types, converges in <60 s, offers consolidation; but lacks multi‑cluster support and fewer years of production hardening compared to Cluster Autoscaler.

300
Walk through building a distributed trace for a high‑latency checkout request in an e‑commerce app.
Inject OpenTelemetry headers, export spans to X‑Ray, visualize waterfall in ServiceLens, identify 200 ms Dynamo scan, index item, optimize query.
300
Explain the trade‑offs between read replicas, sharding, and caching for scaling relational databases.
Replicas scale reads but add lag; sharding scales writes but complicates joins; caching offloads hot reads yet risks staleness. Combine patterns to match access profile.
300
Give an example where you mentored a mid‑level engineer through an on‑call incident.
Co‑triaged a high‑CPU alert, walked through SSM debugging, guided comms, let them draft post‑mortem, and provided feedback.
400
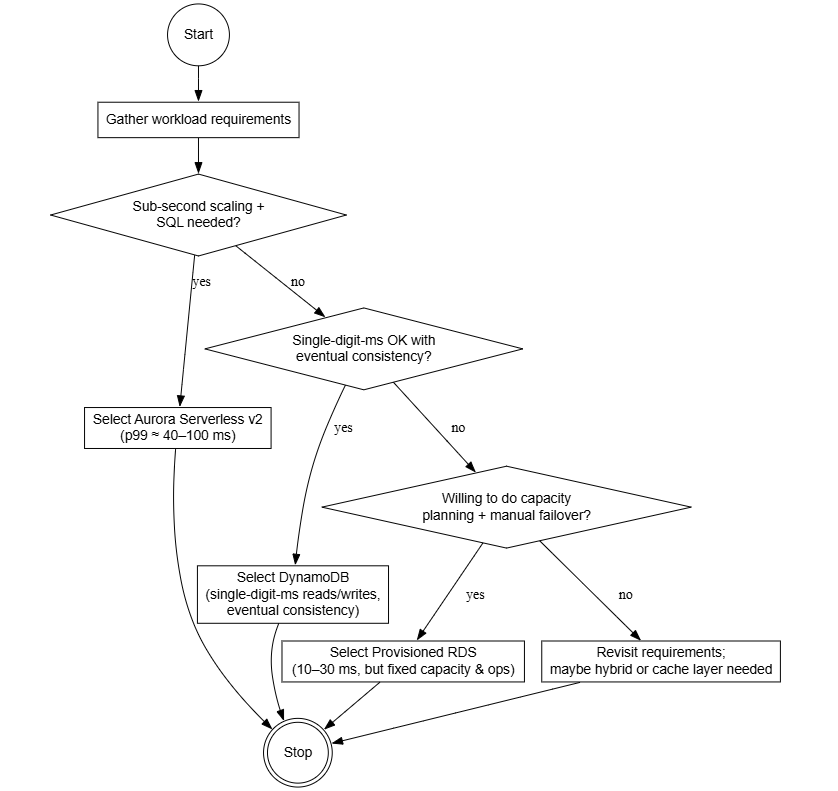
Compare Aurora Serverless v2, DynamoDB, and RDS for a latency‑sensitive workload.
Aurora Serverless v2 brings sub‑second scaling and familiar SQL at ~40‑100 ms p99. DynamoDB delivers single‑digit‑ms reads/writes with eventual consistency trade‑offs. RDS on provisioned hosts gives 10‑30 ms but demands capacity planning and manual failover logic. Pick by access pattern and transactional semantics.
400
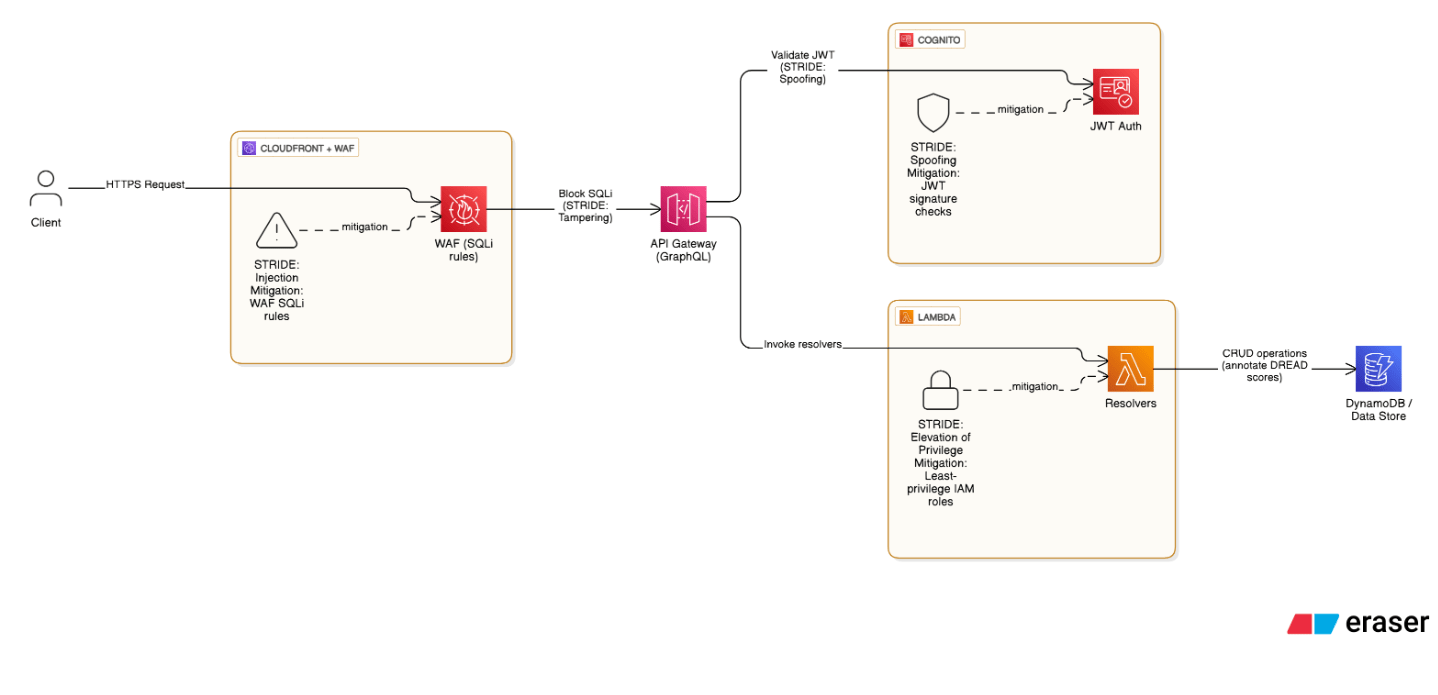
Describe a threat‑modeling exercise you led for a new AWS service rollout.
Using STRIDE + data‑flow diagrams, we mapped attack vectors on a public GraphQL API, scored risks with DREAD, prioritized WAF SQL‑injection rules and Cognito JWT auth, and signed off mitigations with red‑team validation.
400
Give an example where you reduced data‑egress fees in an analytics pipeline.
Relocated ETL jobs to same Region as data source, converted files to Parquet, queried via Athena CTAS for smaller subsets before export, and implemented PrivateLink to eliminate NAT traffic.

400
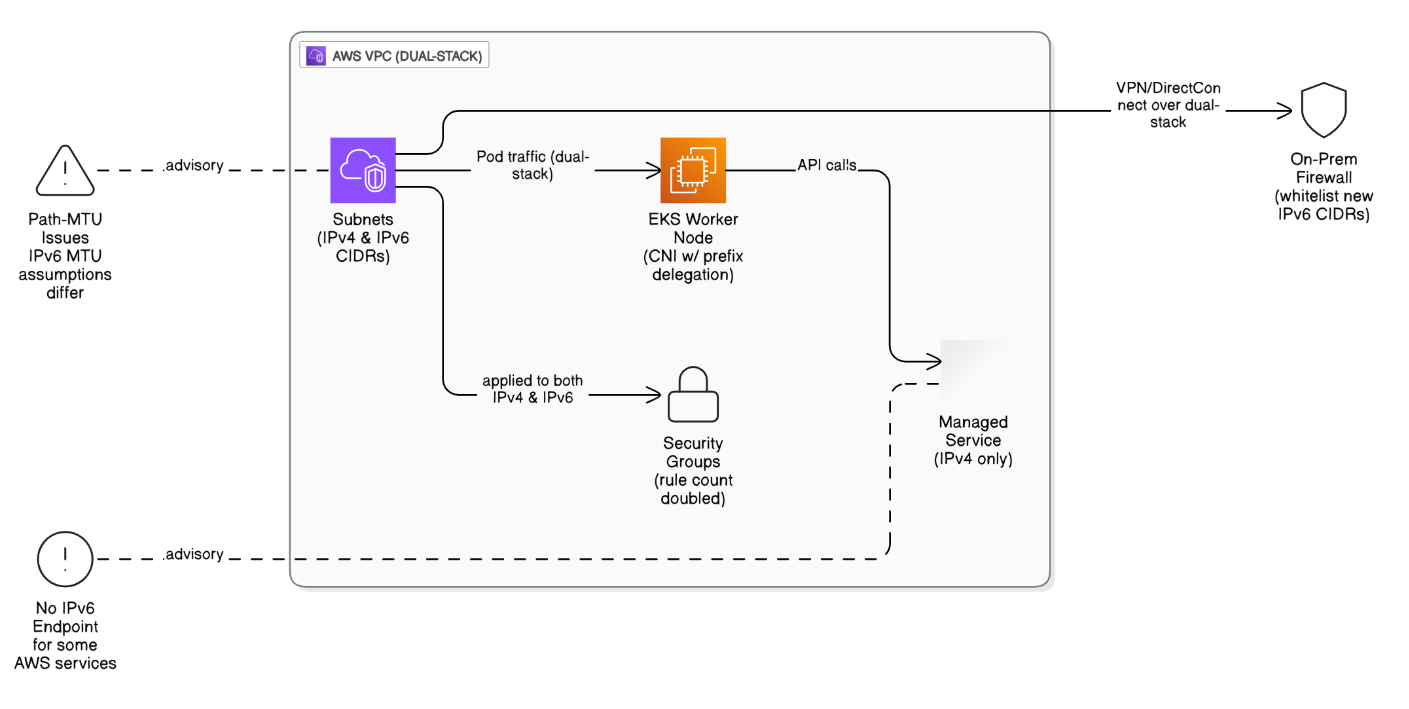
Discuss the challenges of dual‑stack IPv4/IPv6 migrations in VPCs.
Some AWS managed services lack IPv6 endpoints, EKS CNI needs prefix delegation, SGs double rule count, path‑MTU issues, and on‑prem firewalls must whitelist new CIDRs.
400
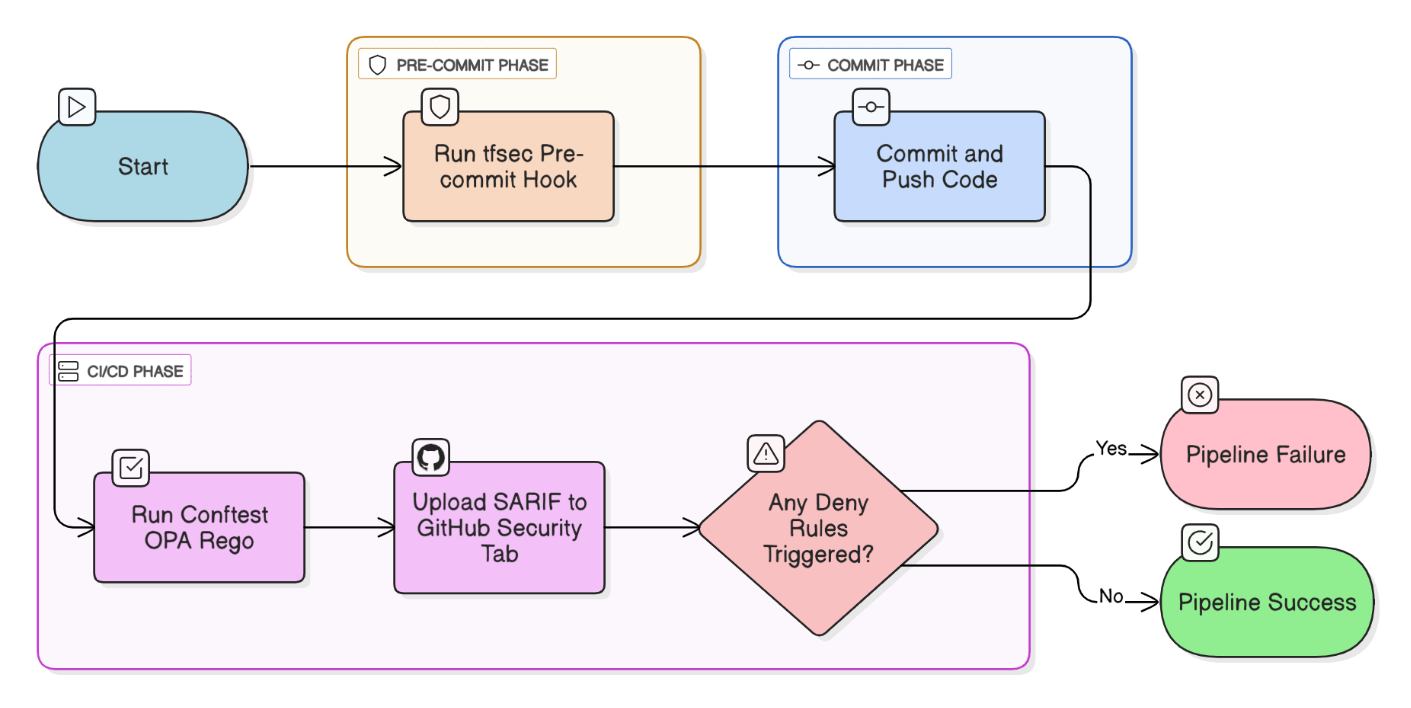
Walk through how you would implement policy‑as‑code guardrails (OPA, Tfsec, or Checkov) in a CI pipeline.
Pre‑commit hooks run tfsec; CI step runs Conftest OPA rego tests; SARIF results uploaded to GitHub Security tab; pipeline fails on any `deny` rule.
400
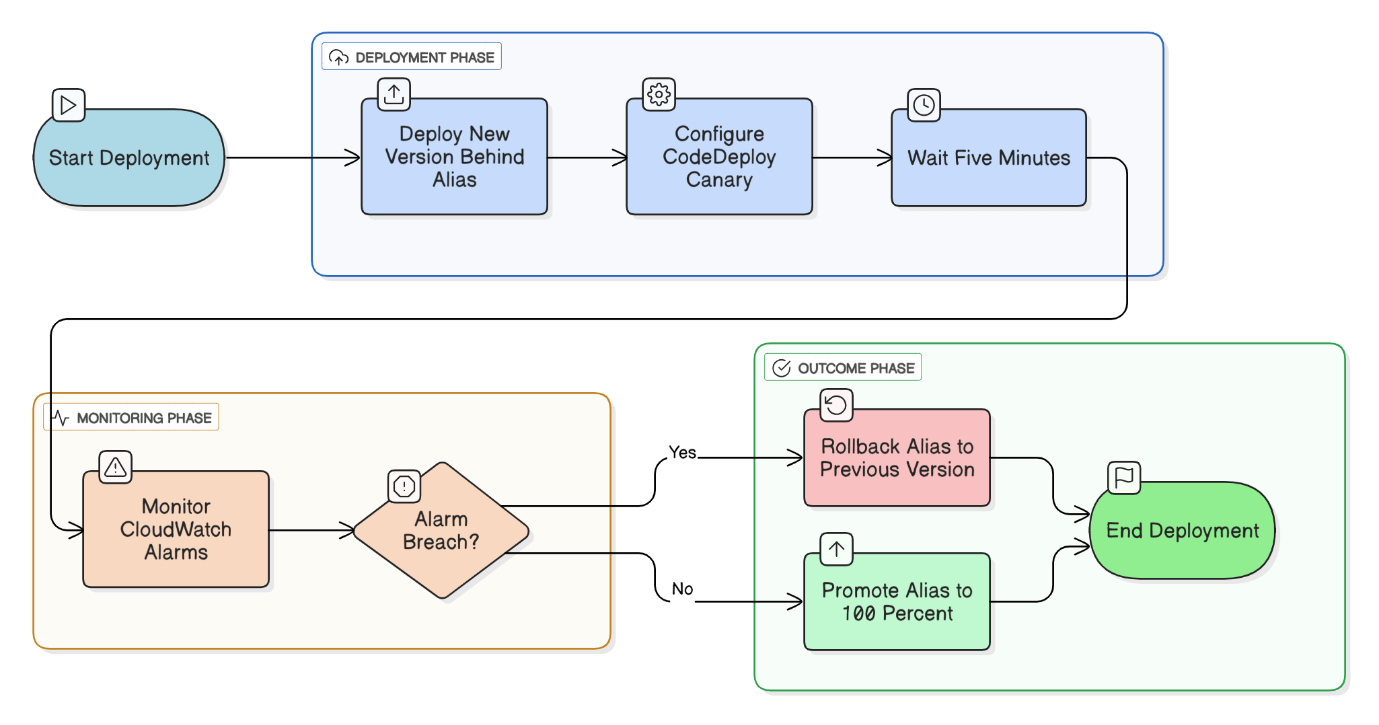
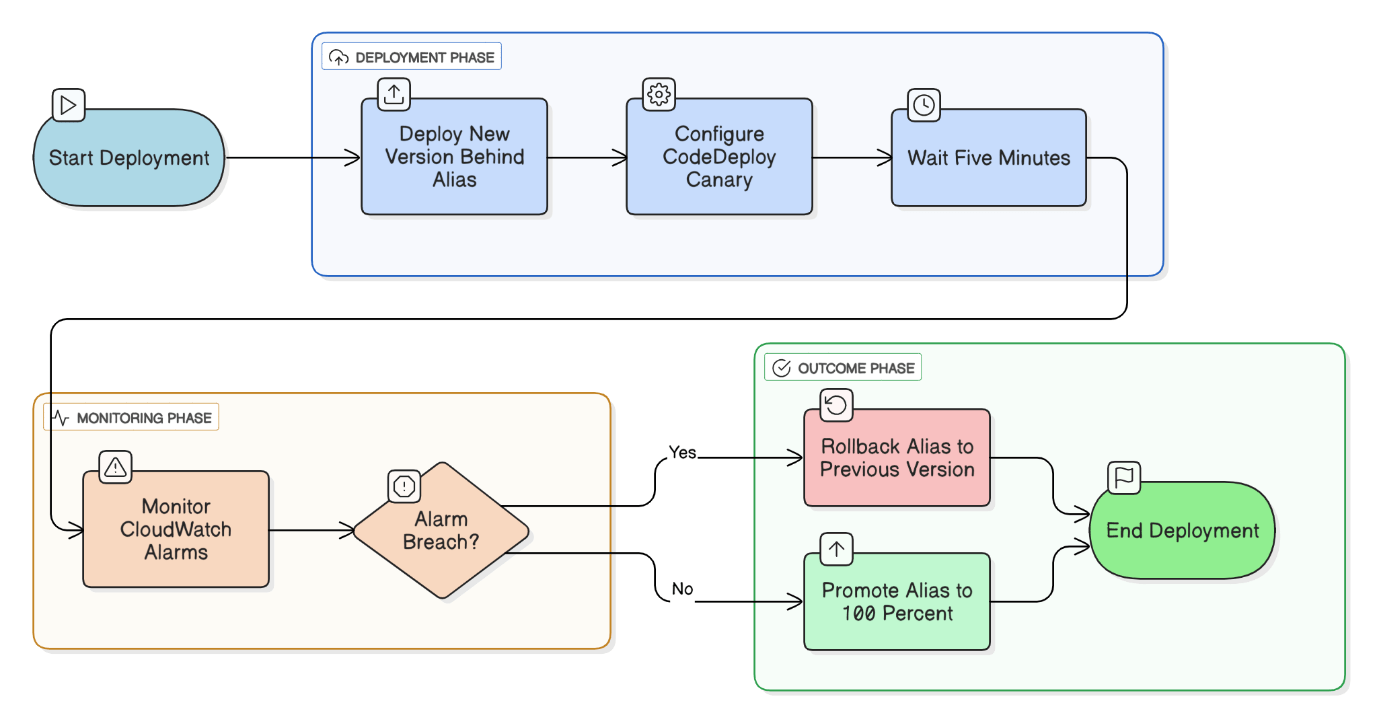
Walk through canary deployments for Lambda with AWS SAM or Serverless Framework.
Deploy new alias, set CodeDeploy Canary10Percent5Minutes, monitor CloudWatch alarms, automatically roll back on breach, then promote to 100 %.
400
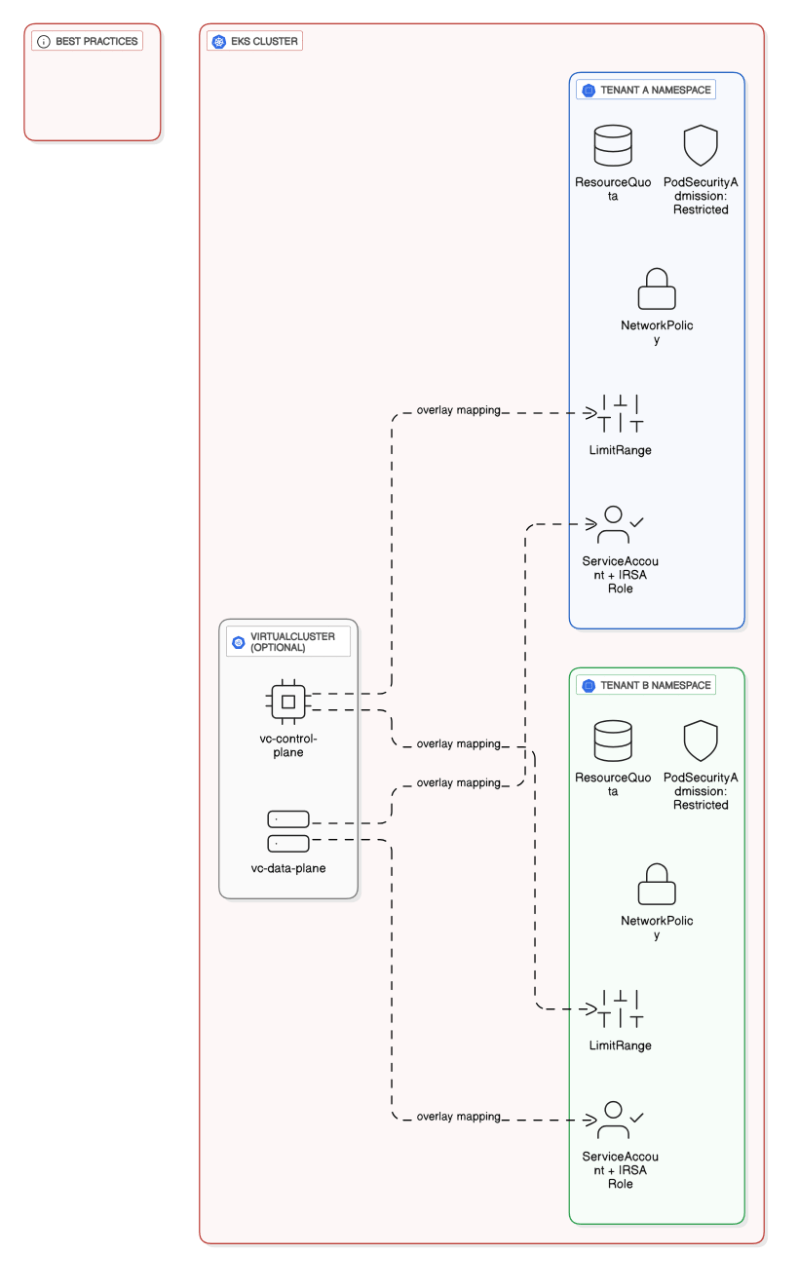
What are best practices for multi‑tenant namespace isolation in EKS?
Separate namespaces per tenant, enforce LimitRanges/ResourceQuotas, PSA restricted level, NetworkPolicies, IRSA scoped roles, and optionally virtual clusters.
400
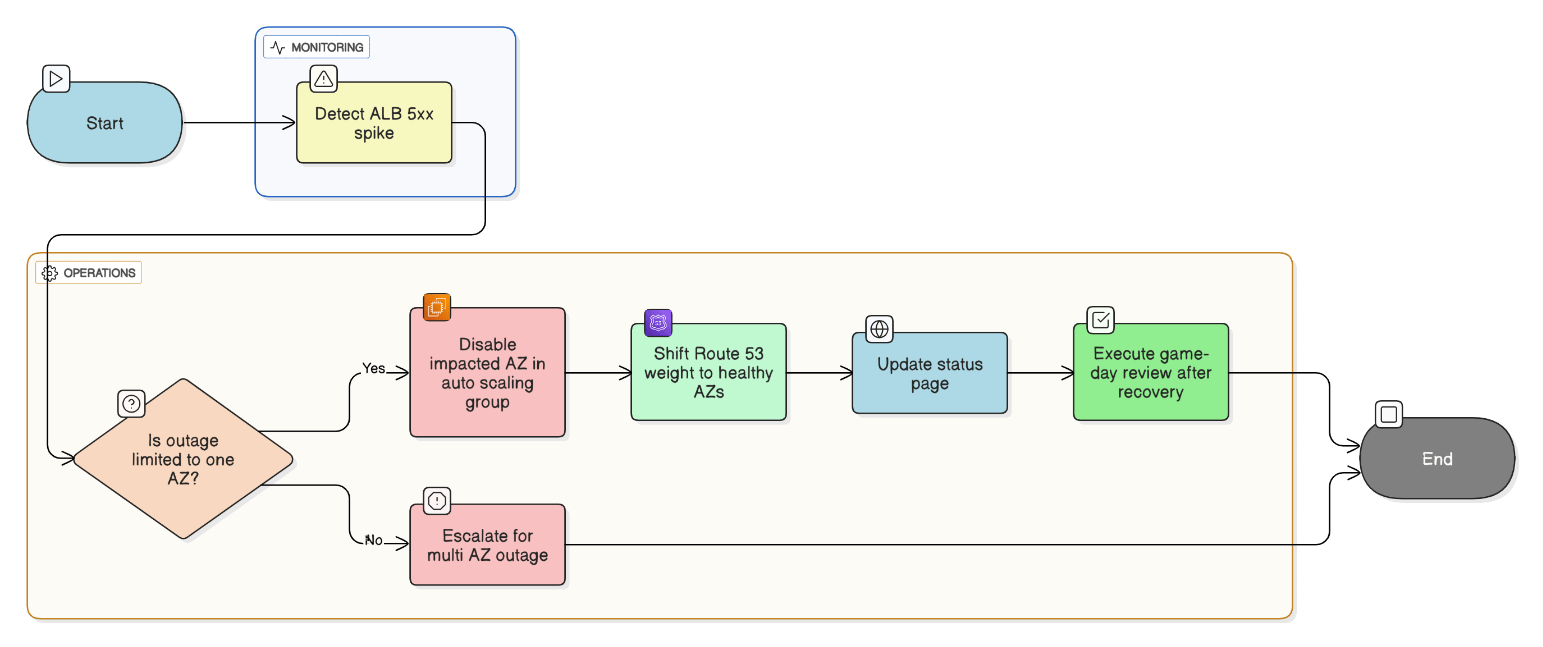
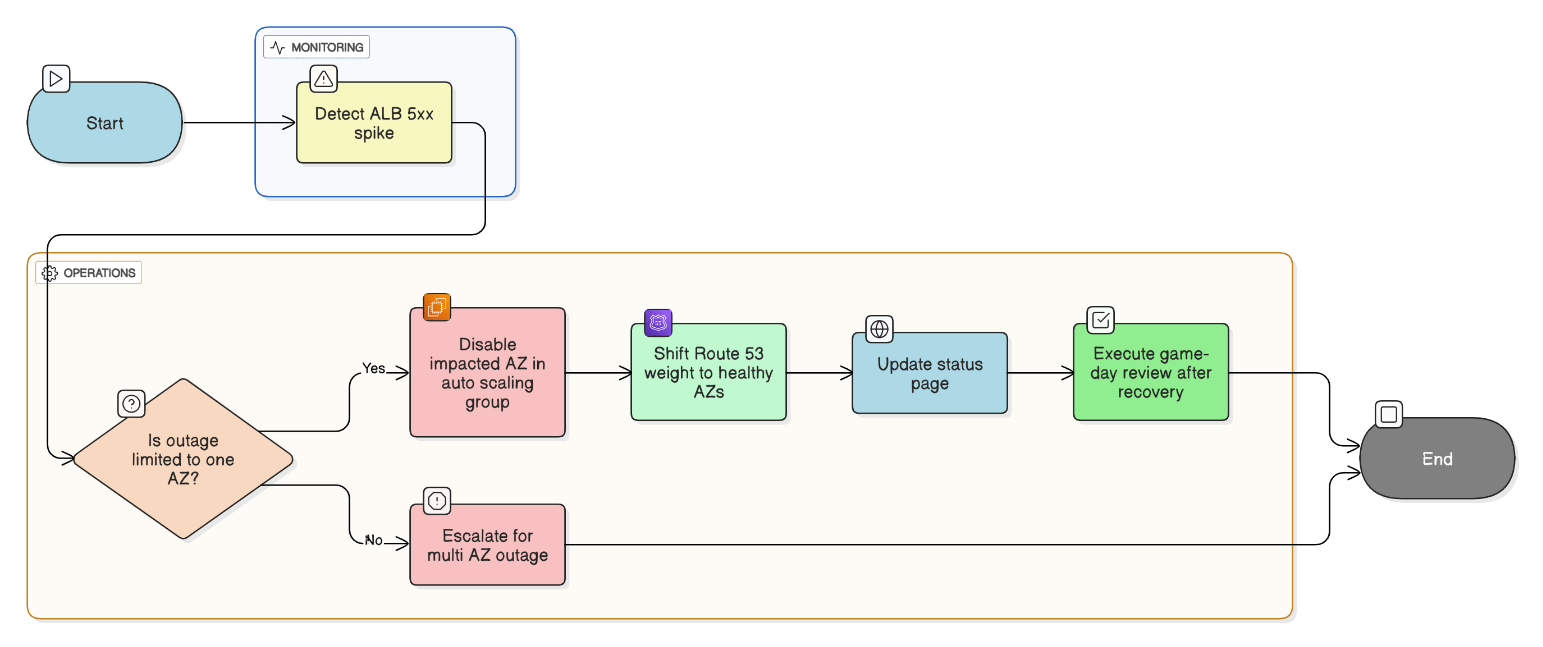
What is your runbook for an AWS networking outage impacting only one AZ?
Detect via ALB 5xx spike, disable AZ in ASG, shift Route 53 weight, notify status page, and execute game‑day after recovery.
400
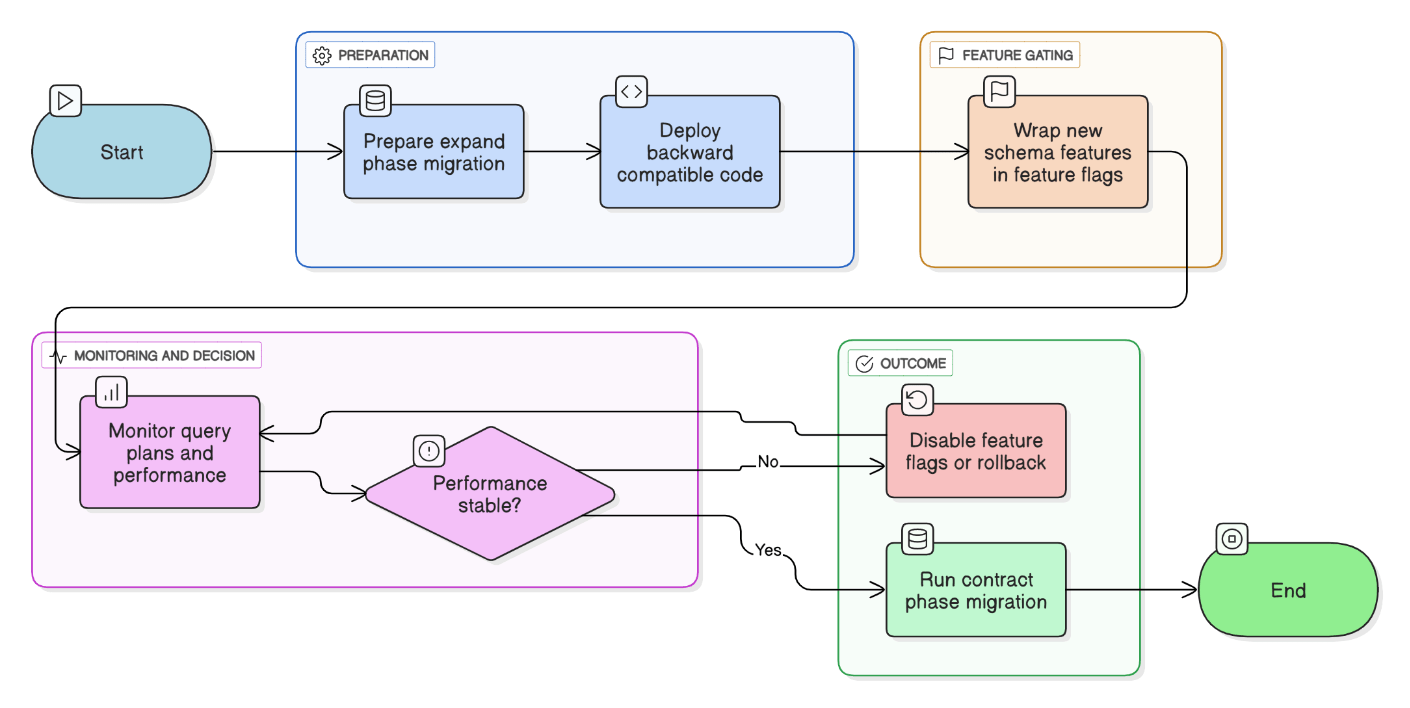
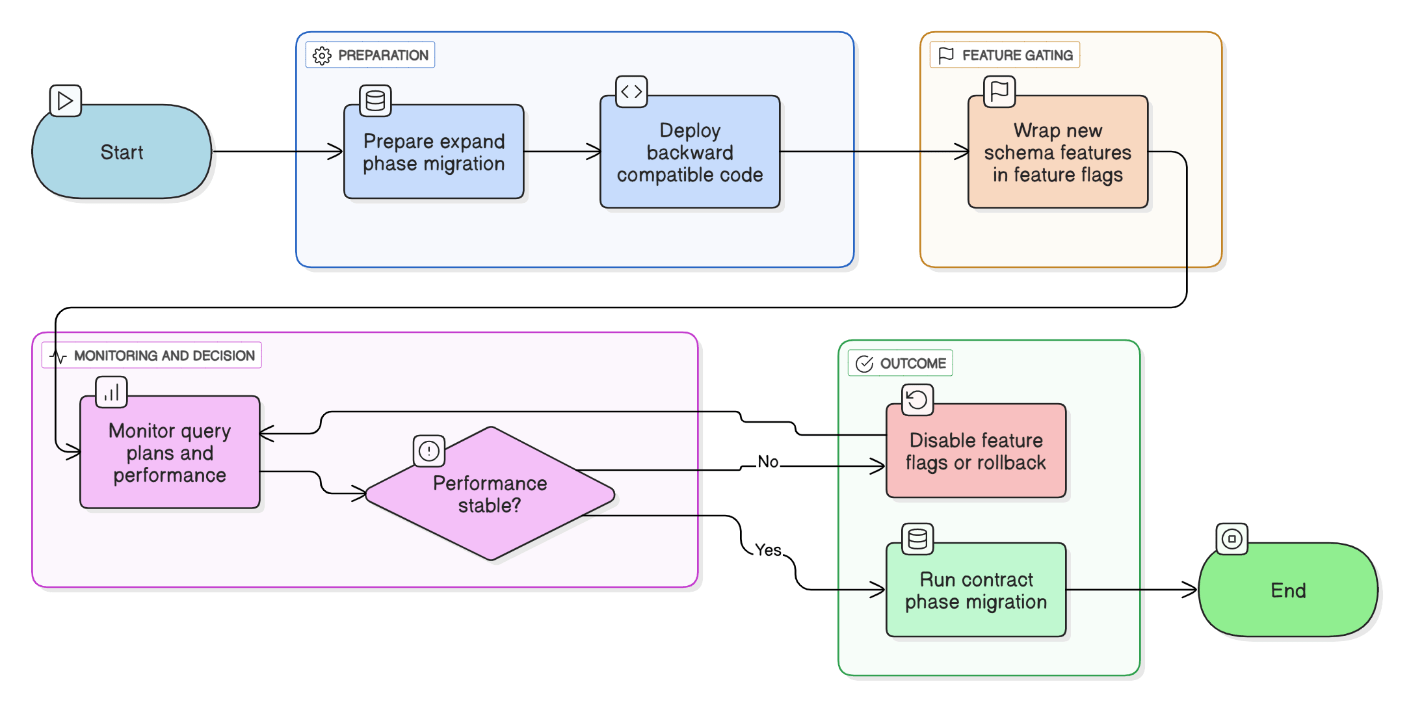
What strategies do you use to maintain reliability while rolling out frequent schema changes?
Practice expand‑contract migrations, keep code backward‑compatible, wrap changes in feature flags, and monitor query plans.
400
How do you evangelize best practices without becoming a bottleneck?
Codify standards in linters/CI, publish reference architectures, run brown‑bag sessions, and recognize early adopters.
500
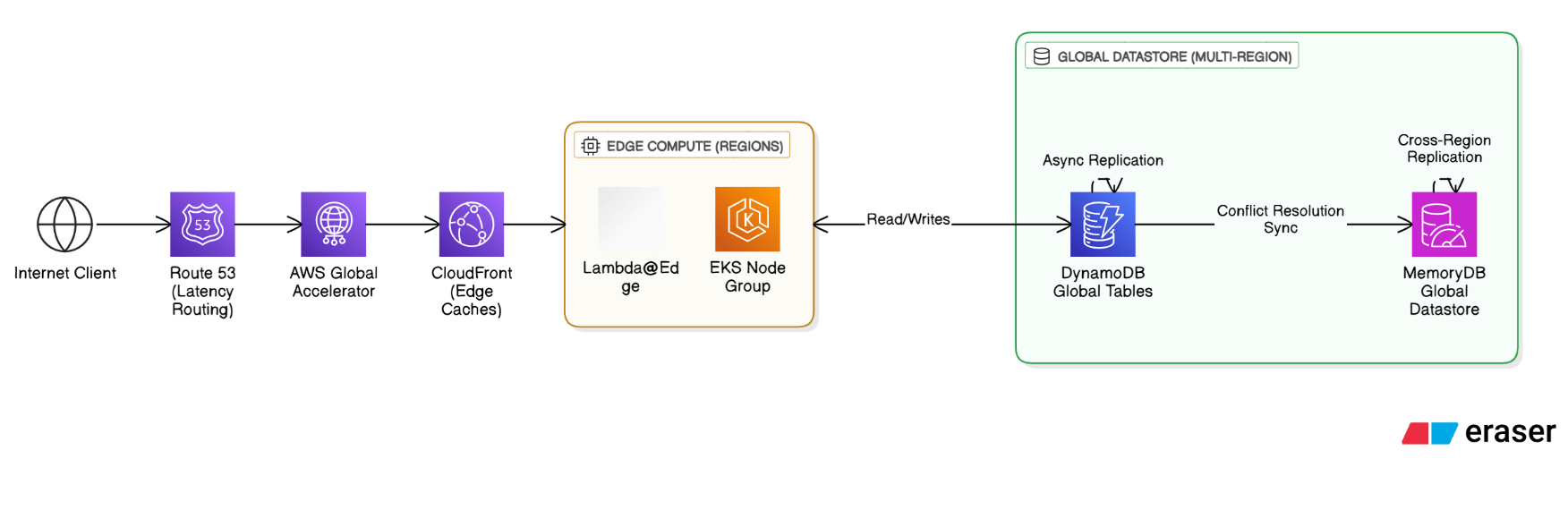
How would you design a global service with single‑digit‑millisecond latency requirements?
Push state to the edge: Route 53 latency routing + AWS Global Accelerator, regional compute in Lambda@Edge/EKS, data in DynamoDB Global Tables or MemoryDB Global Datastore, writes via async replication and conflict resolution, caching through CloudFront.
500
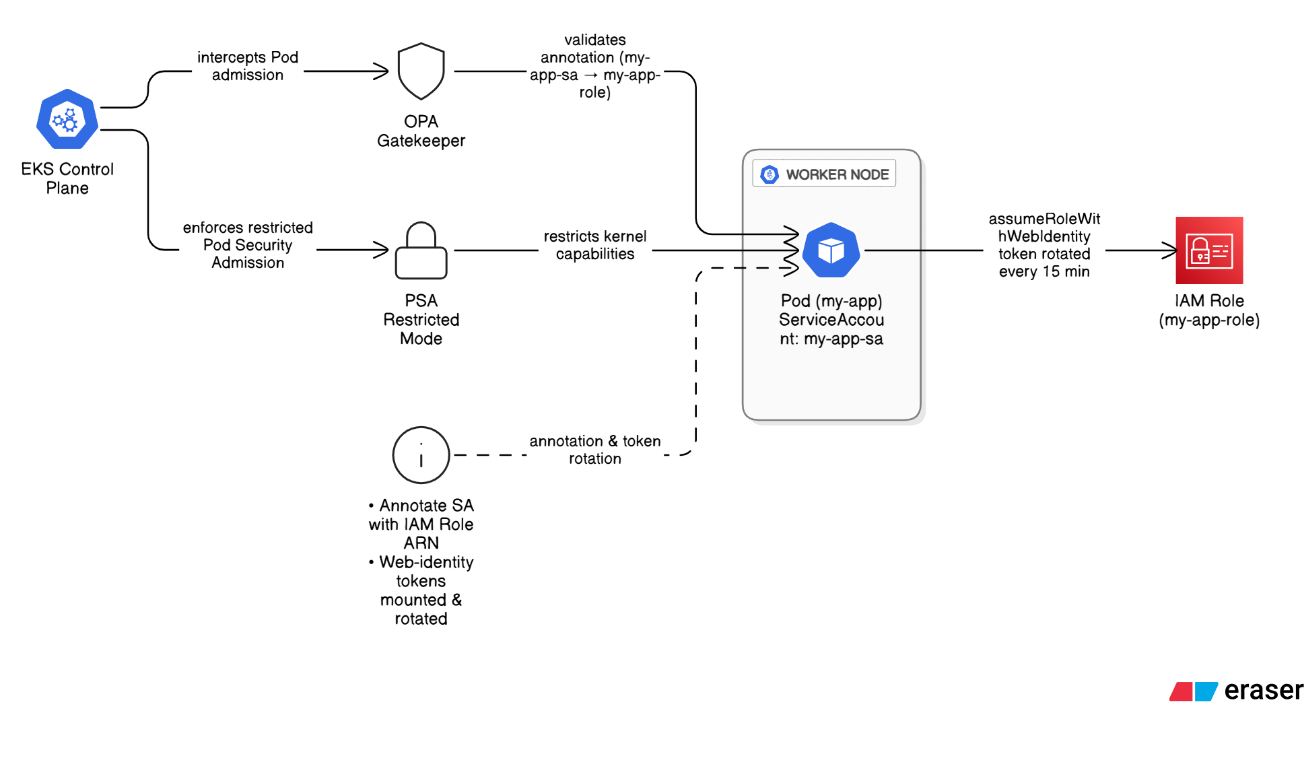
How do you secure workload identity for containers running in EKS?
Adopt IAM Roles for Service Accounts (IRSA), annotate ServiceAccounts with precise IAM roles, rotate web‑identity tokens every 15 minutes, enforce annotations via OPA Gatekeeper, and restrict kernel capabilities via PSA restricted mode.
500
How do you evaluate the break‑even point between Graviton and x86 instances?
Benchmark workloads, compile native libs with -march=armv8, evaluate price/perf in Compute Optimizer; if CPU‑bound utilization >60 %, Graviton shows 20‑40 % savings within a week.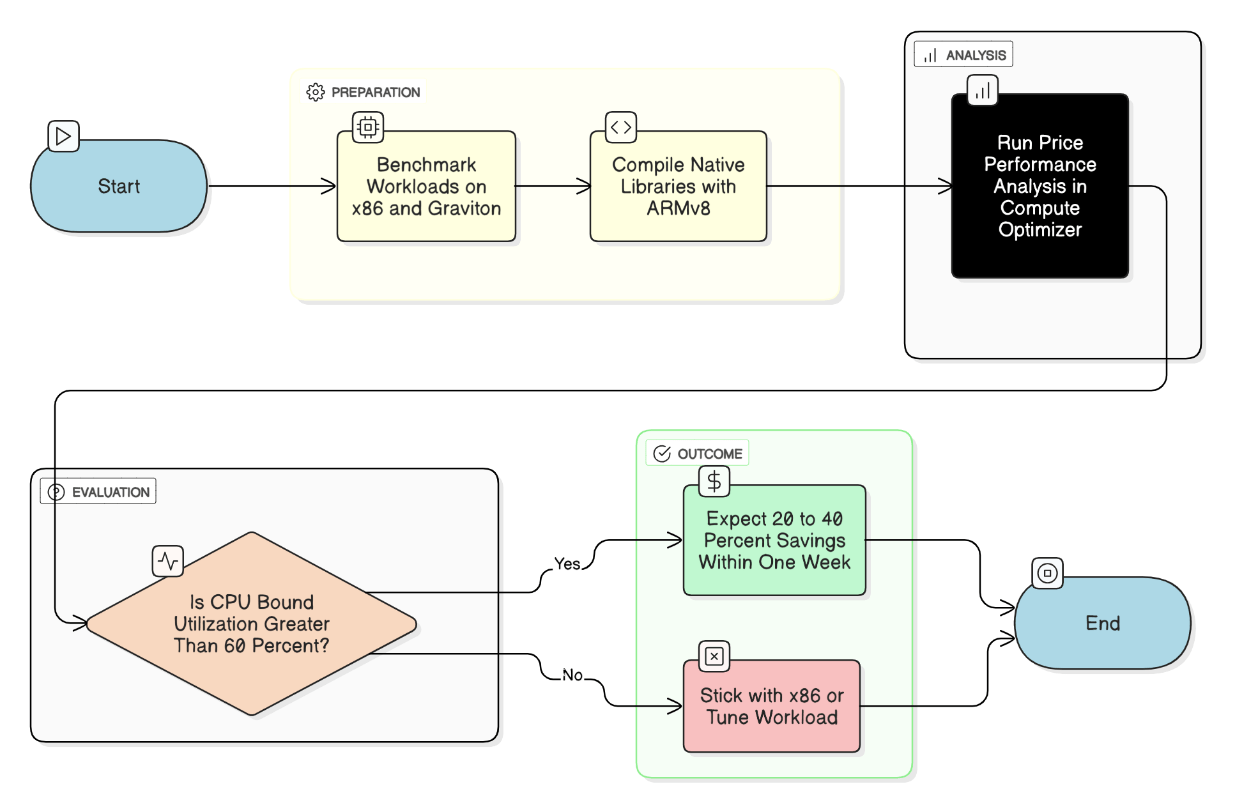
500
How do you secure traffic over a Site‑to‑Site VPN when the peer cannot support IKEv2?
Use IKEv1 with strongest shared cipher suite, enable DPD, set dual tunnels, limit lifetime, and consider running IPsec over Direct Connect as backup.
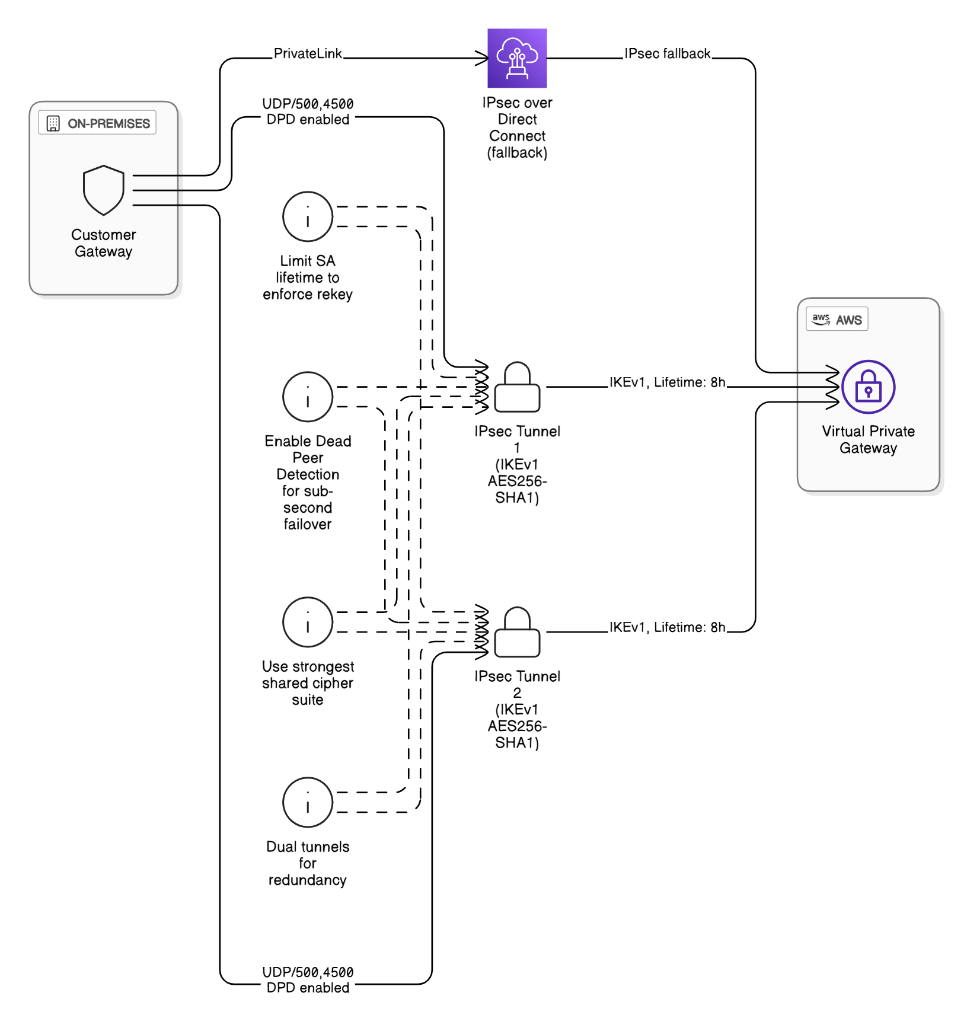
500
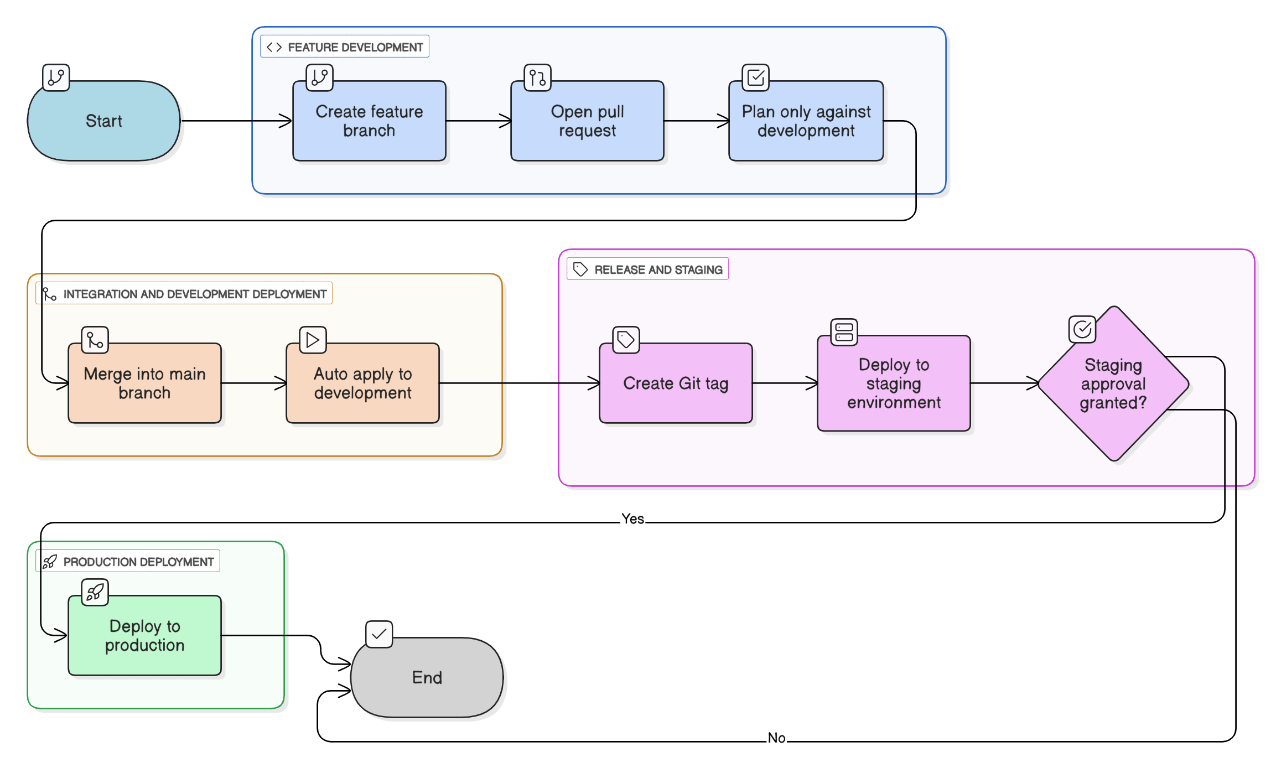
Describe your branching strategy for IaC and how it maps to promotion environments.
Trunk‑based: feature branches → PR → plan‑only in dev; merge to main triggers auto‑apply to dev; a git‑tag triggers staging → production via GitHub Environments requiring manual approval.
500
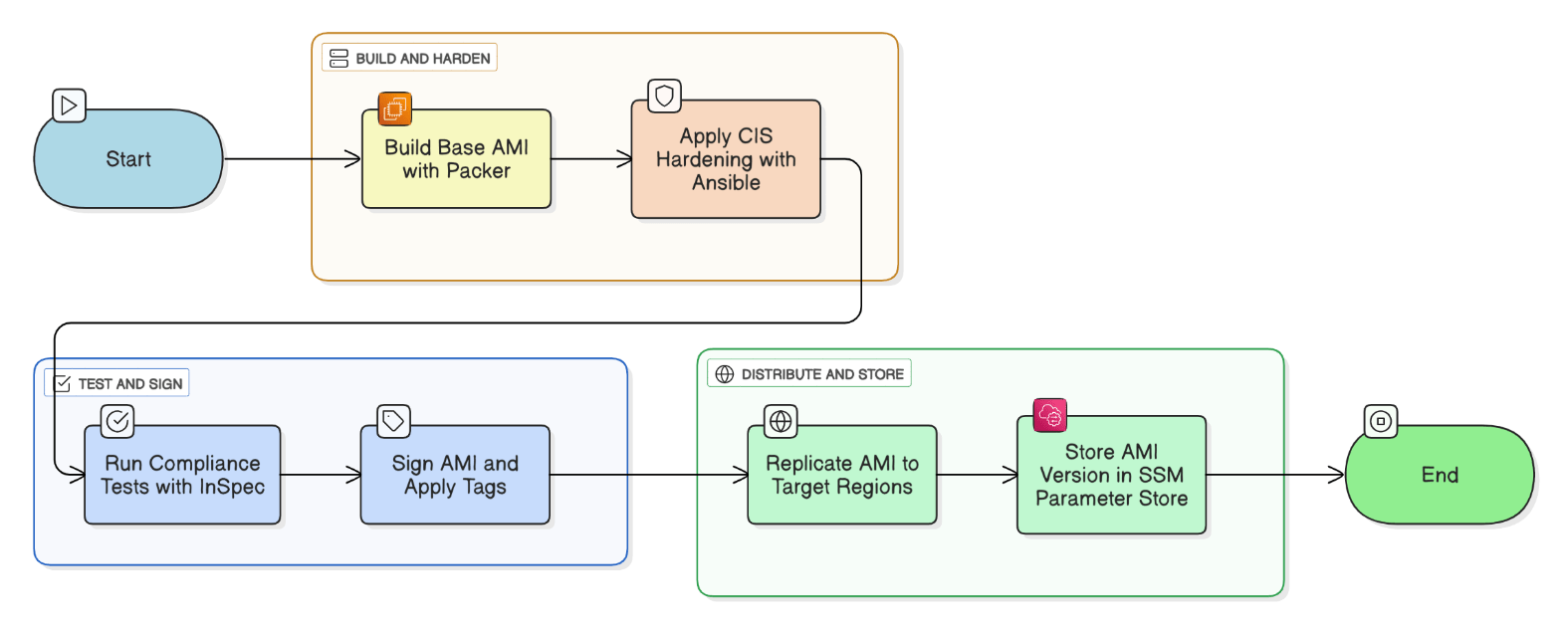
How do you bake AMIs in a golden‑image pipeline while meeting CIS hardening baselines?
Packer builds base AMI, applies Ansible hardening, runs InSpec tests, signs AMI tags, replicates to target Regions, and stores version in SSM Parameter Store.
500
How do you implement pod‑level security with PSA modes and OPA Gatekeeper?
Set cluster PSA to “restricted”, deploy Gatekeeper constraints enforcing `runAsNonRoot`, `readOnlyRootFilesystem`, and drop `CAP_SYS_ADMIN`, run audit mode first, then enforce.
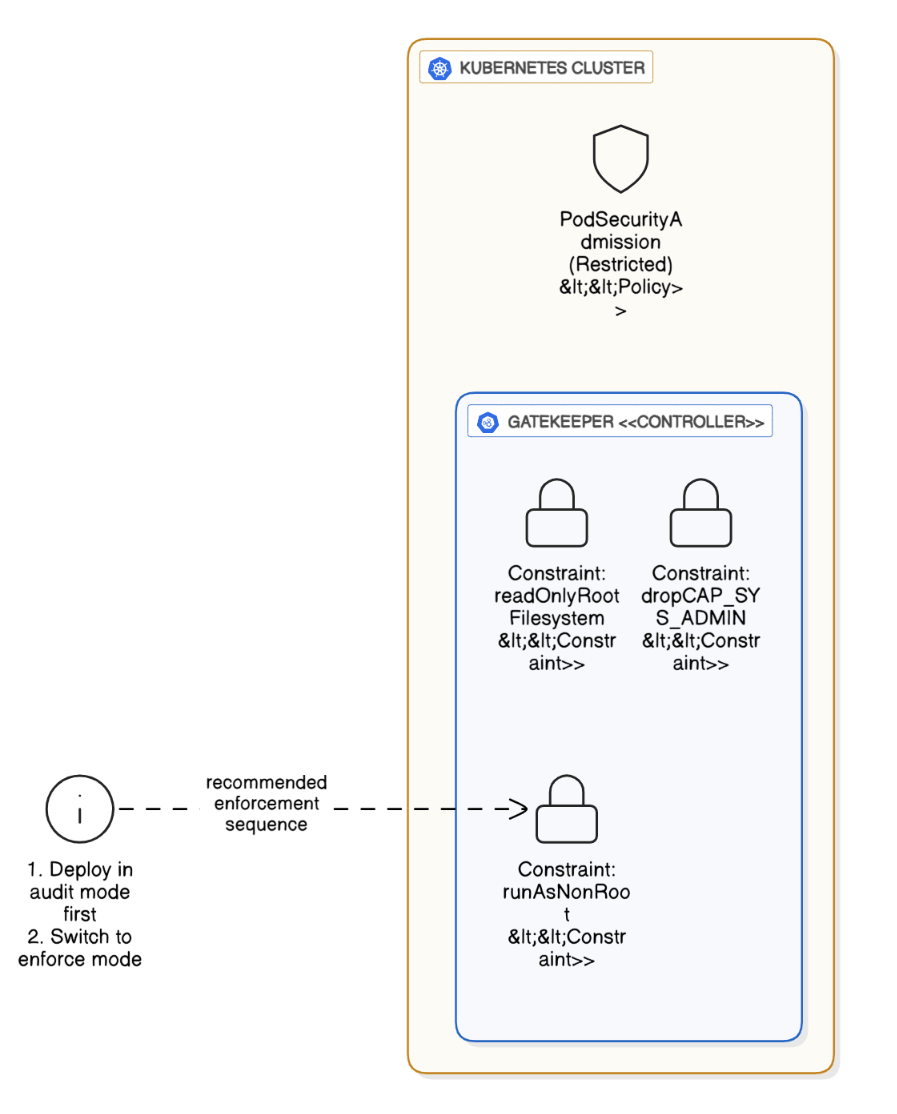
500
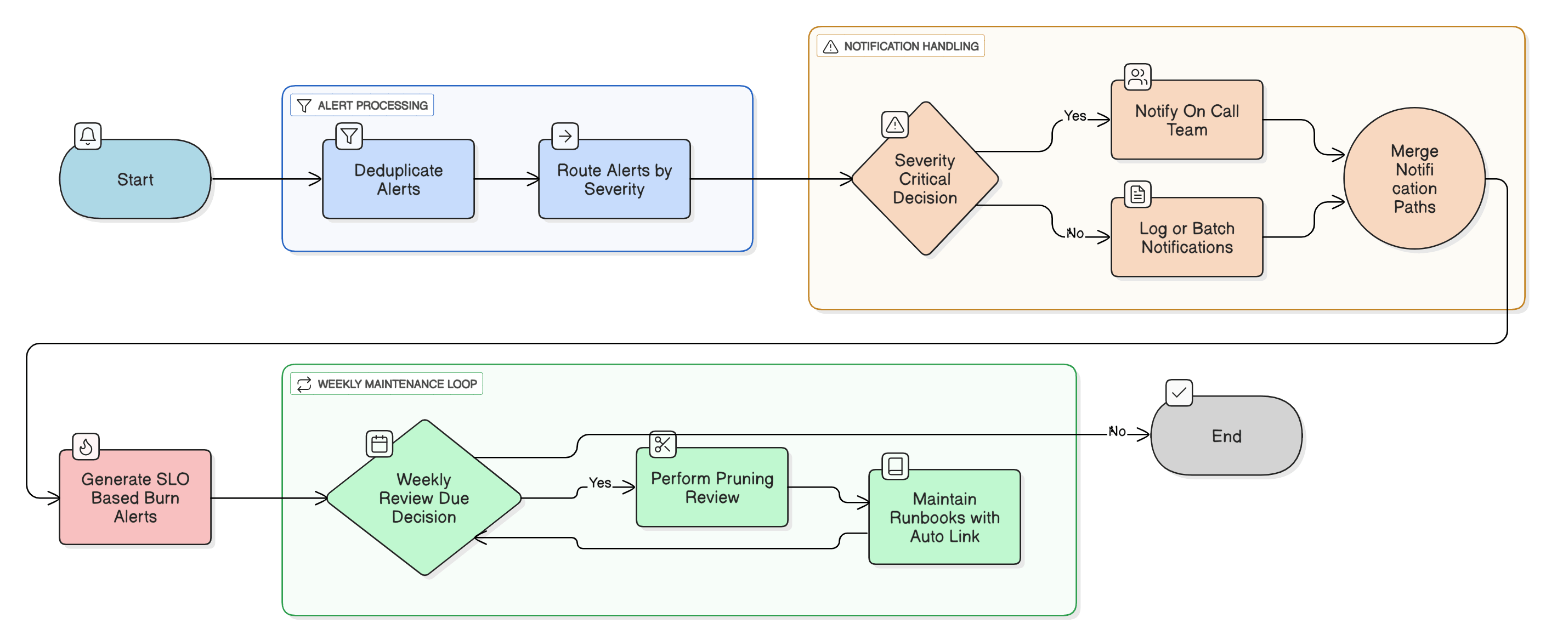
How do you manage alert fatigue while maintaining low MTTA/MTTR?
Deduplicate alerts, route by severity, use SLO‑based burn alerts, weekly pruning review, and maintain runbooks with auto‑link.
500
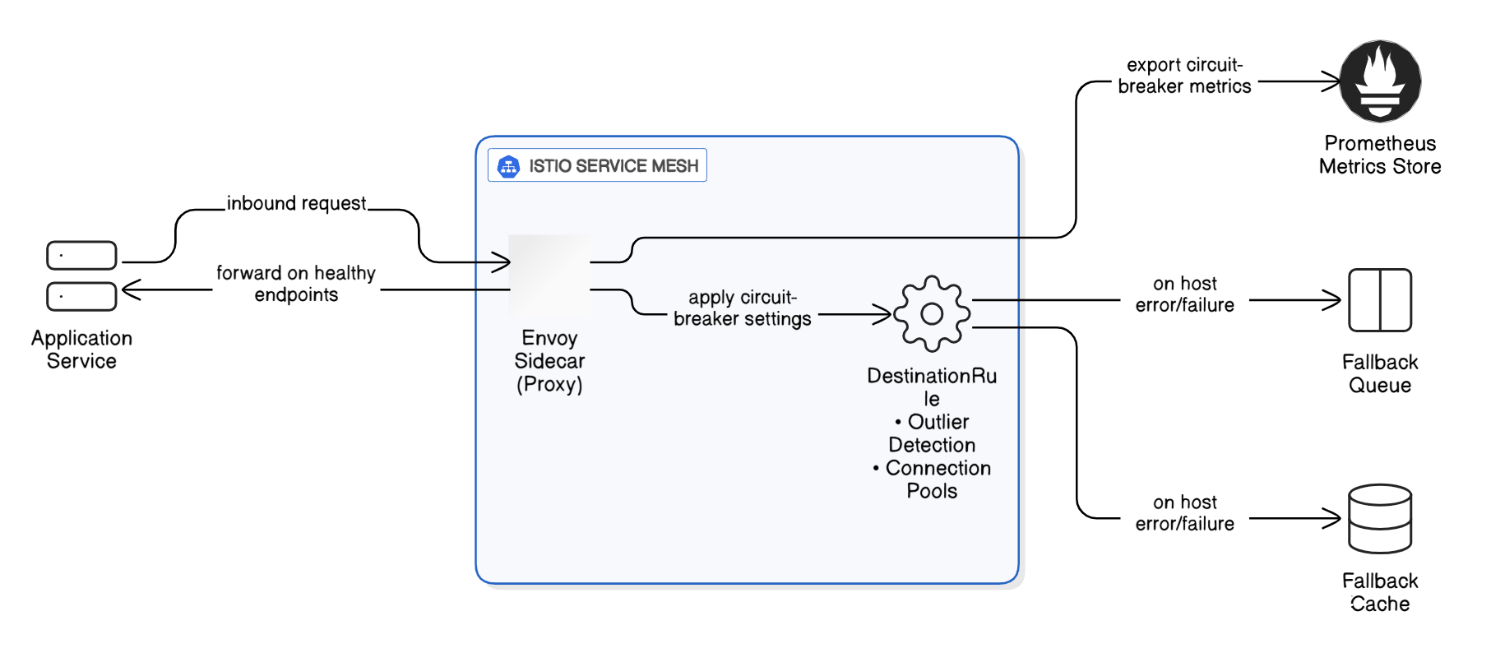
Describe how you would implement circuit‑breaker patterns in a service mesh.
In Istio, set `DestinationRule` outlier detection and connection pools, fallback to queue or cache, and export metrics to Prometheus.
500
Explain how you balance product delivery velocity against technical debt in a scale‑up environment.
Use WSJF scoring, allocate 20 % sprint capacity to debt, track debt items in Jira, and review quarterly.
600
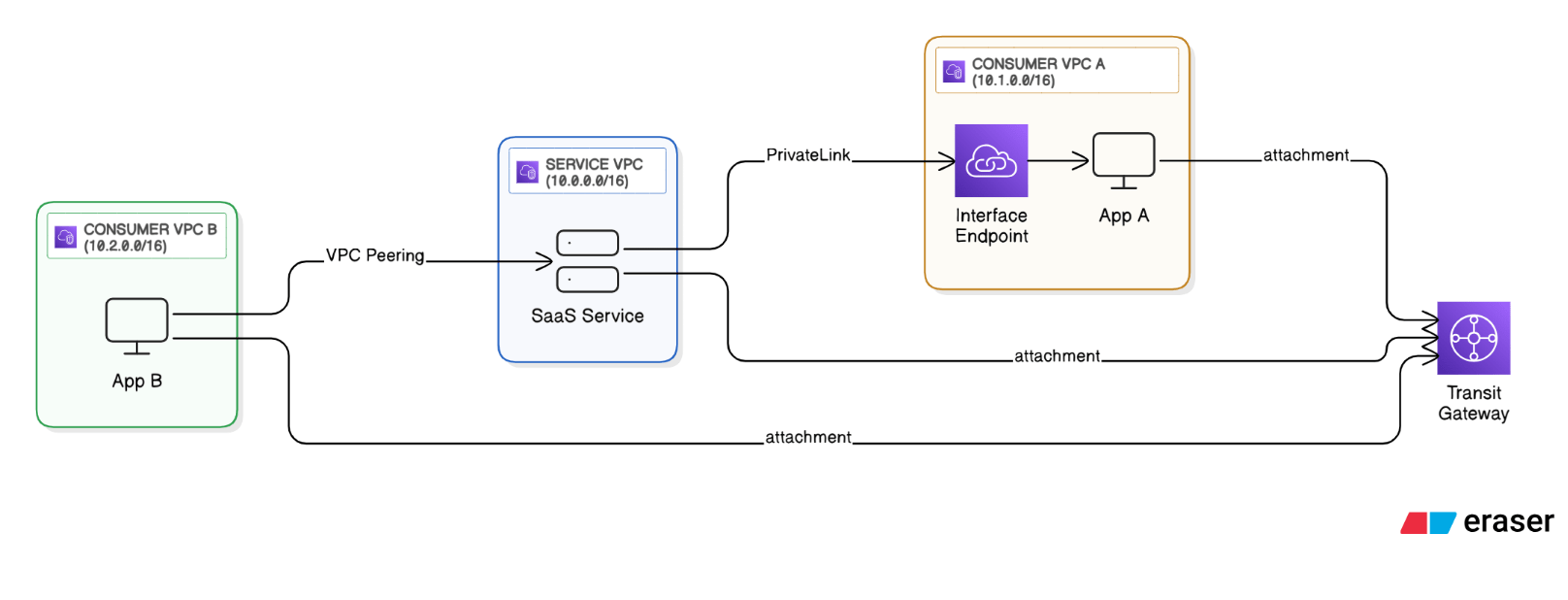
Explain how PrivateLink, Transit Gateway, and VPC peering differ, and when you would choose each.
PrivateLink exposes an interface endpoint inside consumer VPCs, ideal for one‑way SaaS and overlapping CIDRs. Transit Gateway is a hub‑and‑spoke L3 router with route‑table segmentation and transitive routing. Peering is simple point‑to‑point, non‑transitive, good for few VPCs with unique CIDRs.
600
Walk through your process for rotating and auditing secrets across multi‑cloud and on‑prem.
Centralize secrets in HashiCorp Vault, replicate to AWS Secrets Manager for Lambda, use Lambda rotation helpers for RDS, enable Azure Key Vault auto‑rotate, aggregate Vault audit logs in Splunk, and enforce rotation schedules via Terraform Cloud run‑tasks.
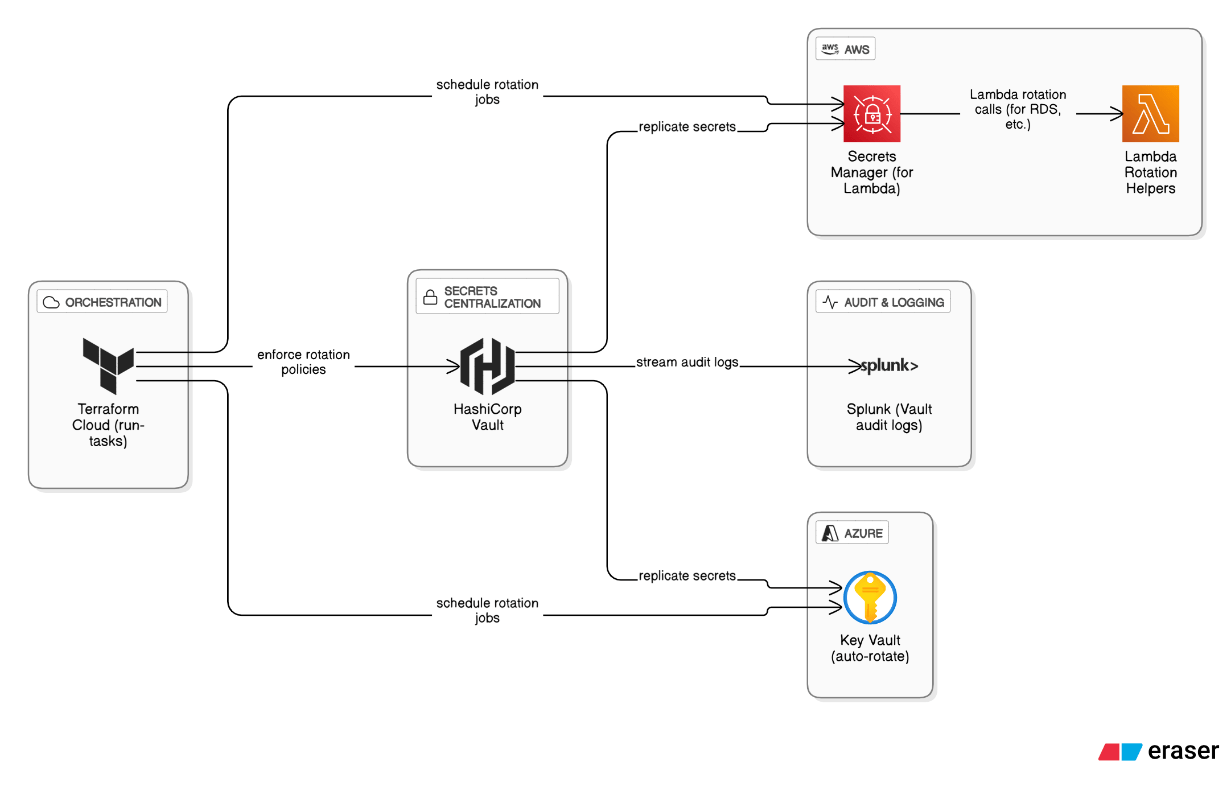
600
Discuss pros/cons of Savings Plans vs Spot Instances in CI/CD runners.
SPs guarantee discount for base load; Spot offers deepest savings but interruptions; a mixed ASG with SP baseline and Spot burst keeps pipelines fast and cheap.
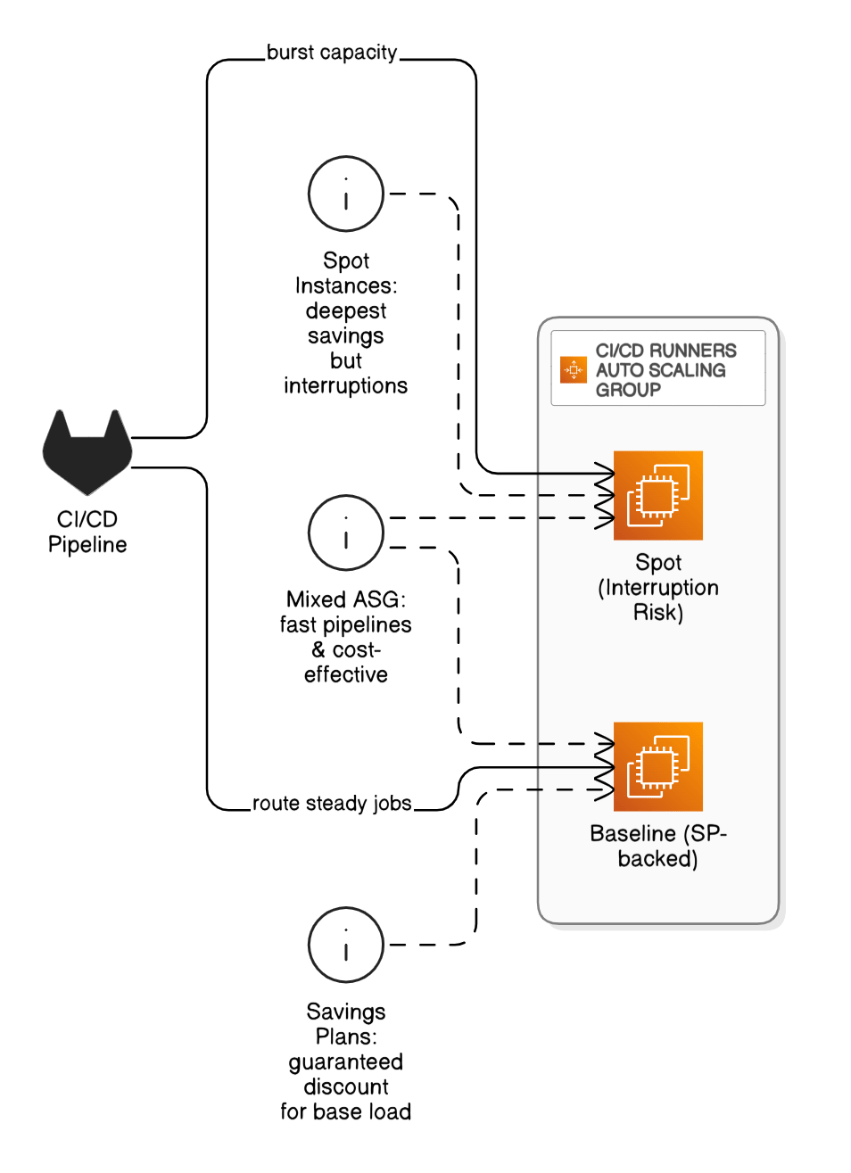
600
Explain ENI‑trunking for ECS and its scaling limits.
Trunk ENI attaches to instance, branch ENIs per task, supports up to 120 tasks per m5.large, constrained by ENI/IPv4 address quotas; monitor via CloudWatch metric `NetworkInterfacesAvailable`.
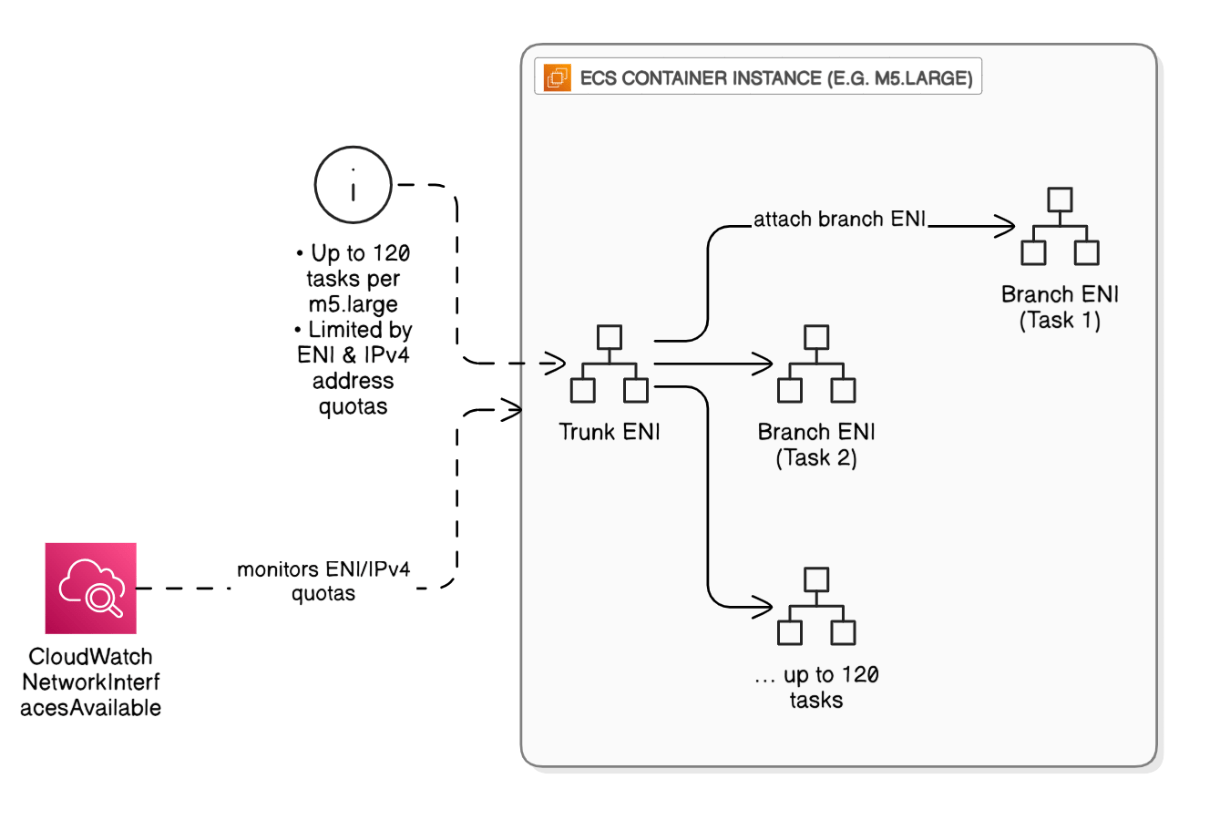
600
What are the gotchas when using Terraform Cloud workspaces with multiple AWS accounts?
Each workspace needs isolated AWS creds; variable sets must be carefully scoped; run‑triggers can create cyclic applies; remote plan JSON needs to be stored securely.
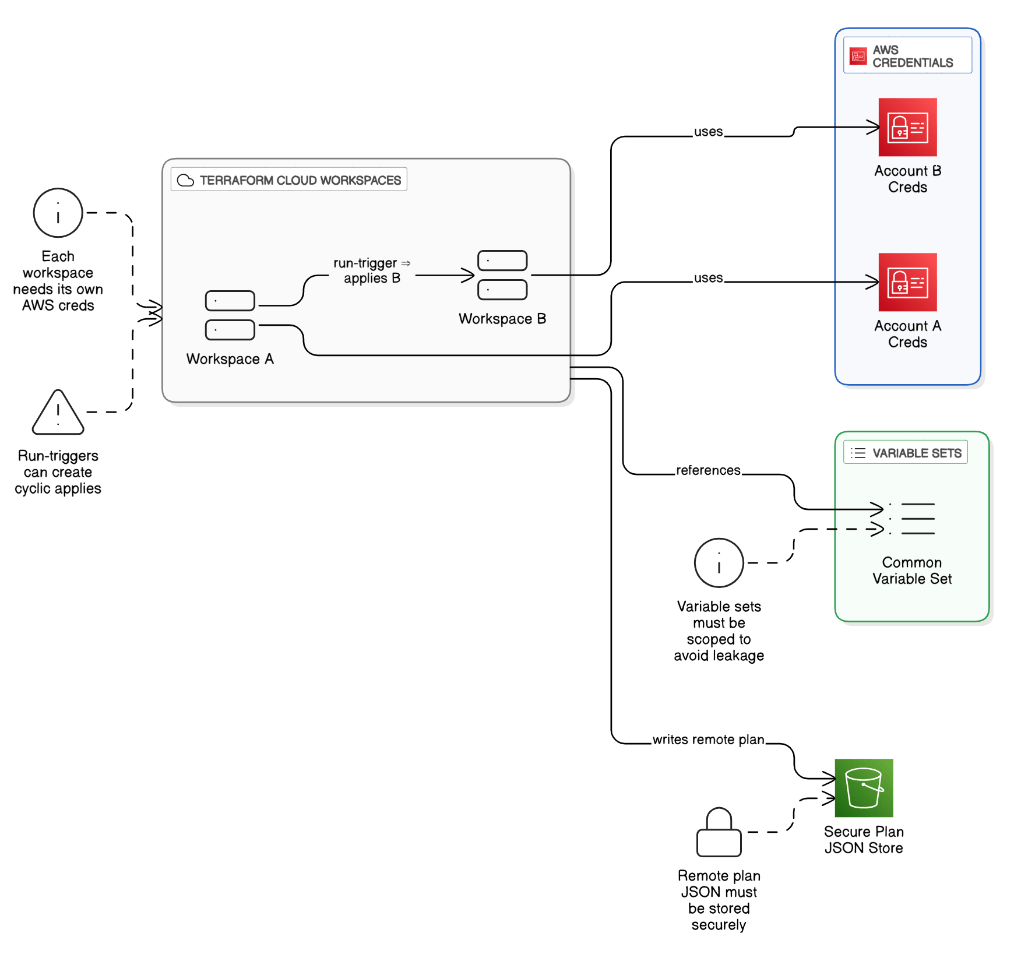
600
Describe your approach to securing software supply chains (e.g., Sigstore, SLSA).
Sign containers with cosign, store attestations in Rekor, require signature verification at admission, generate provenance metadata in CI, and adopt SLSA‑level 2 build integrity.
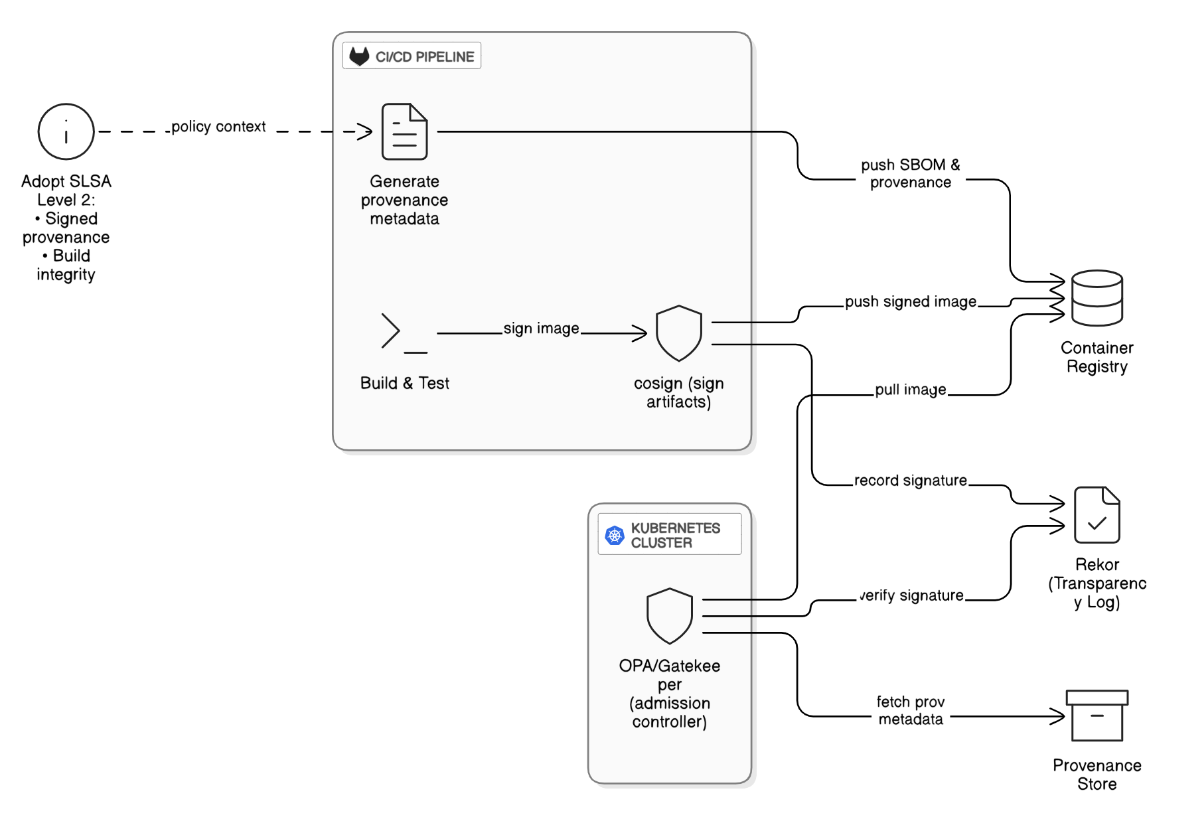
600
Discuss patterns for zero‑downtime schema migrations in micro‑services using RDS Proxy.
Apply expand‑and‑contract migrations via Flyway, connect through RDS Proxy to avoid connection exhaustion, and gate write‑paths behind feature flags.
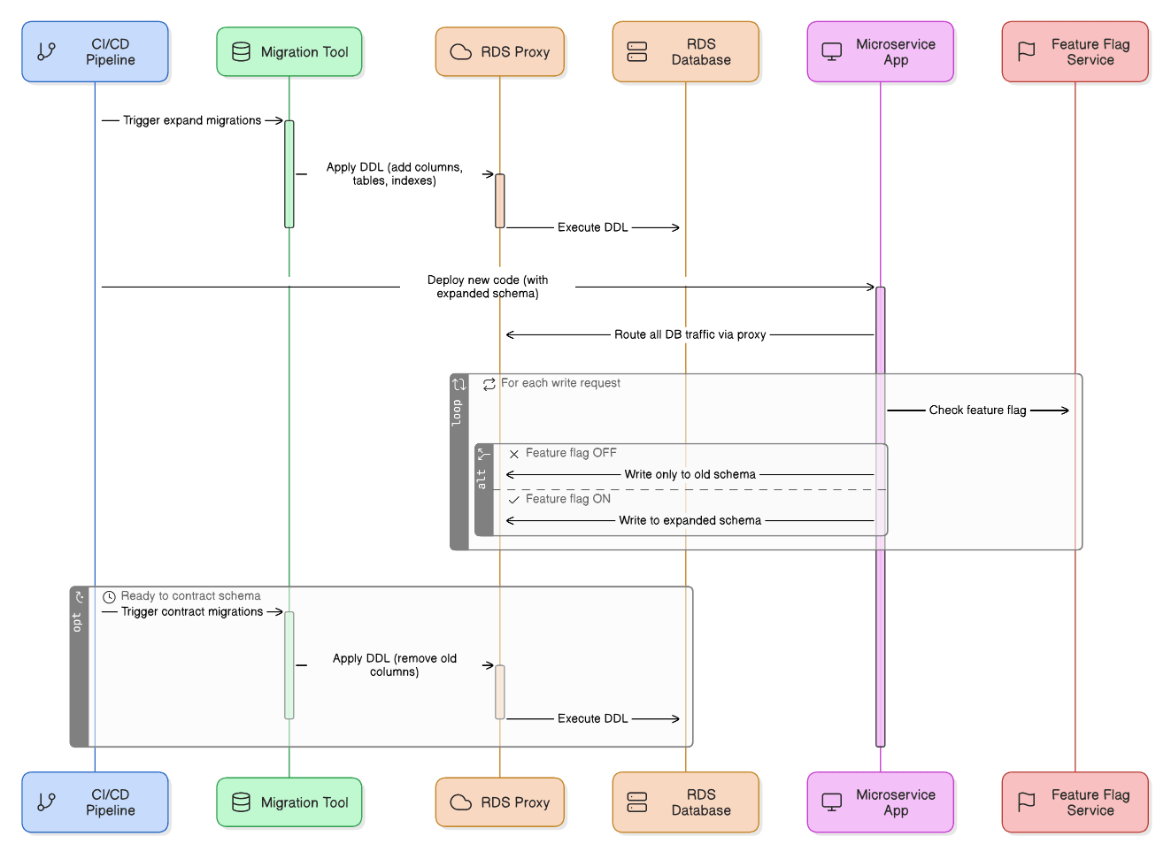
600
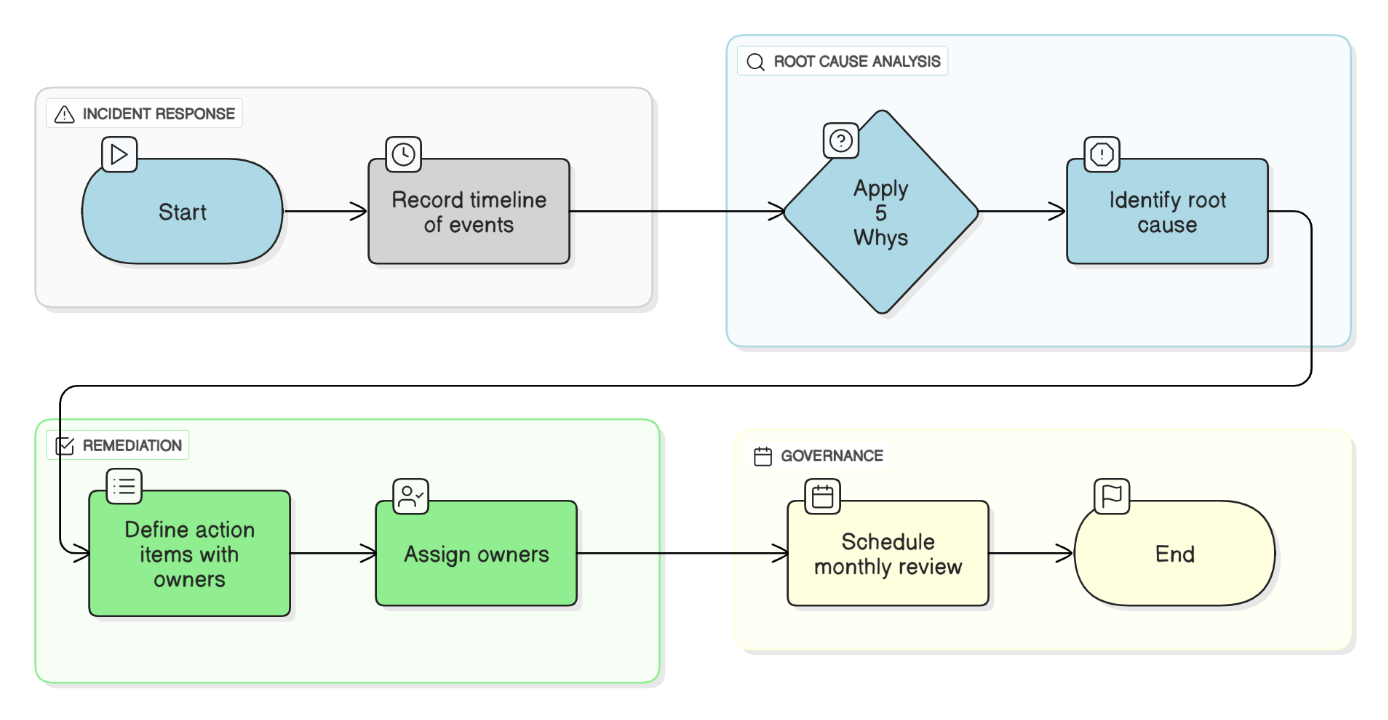
Describe a post‑mortem you authored and how you drove systemic fixes.
Database failover misconfigured TTL caused 17‑min outage; timeline, 5 whys, action items with owners, and monthly review to verify completion.
600
How do you measure and mitigate tail‑latency in distributed systems?
Instrument p99.9 latencies, use hedged requests, timeout budgets, and prioritize critical traffic with priority queues.
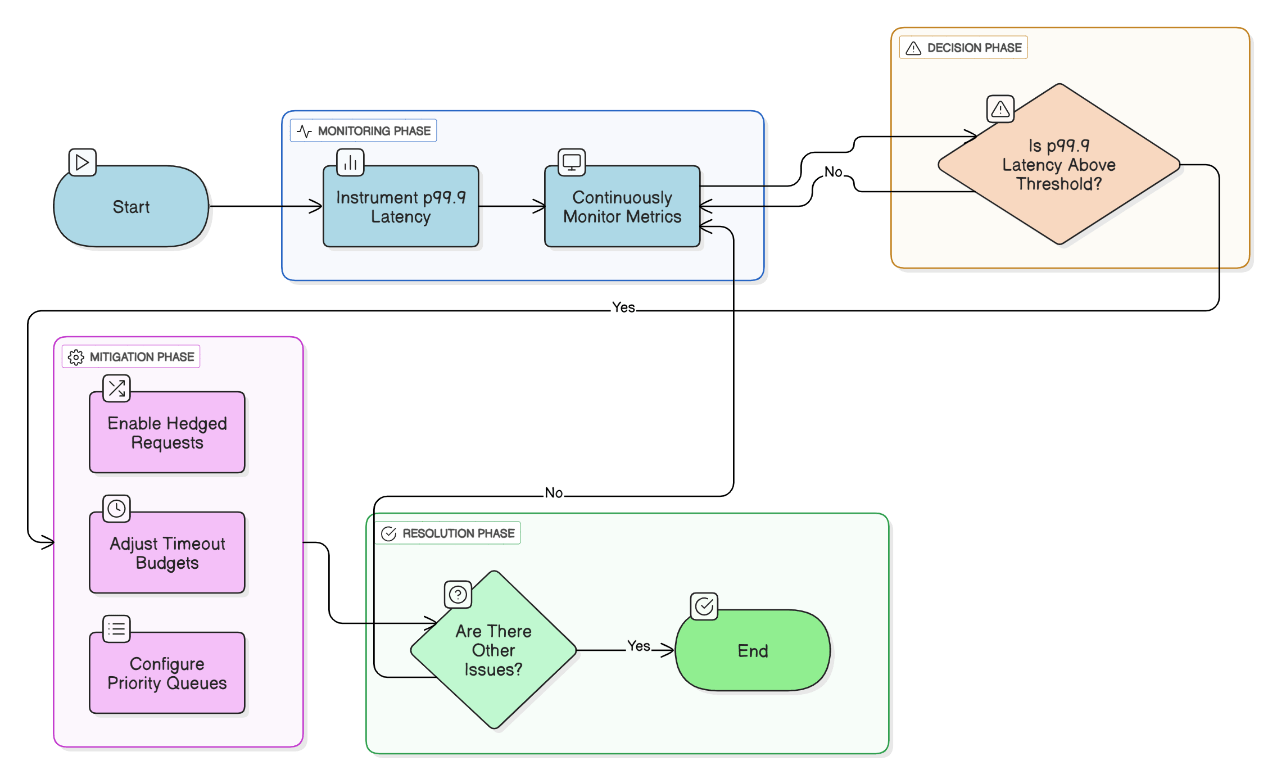
600
Describe your framework for conducting design reviews in a multi‑disciplinary team.
RFC template, reviewers from security/ops/product, approval checklist, decisions logged as ADRs, and async comments before meeting.
700
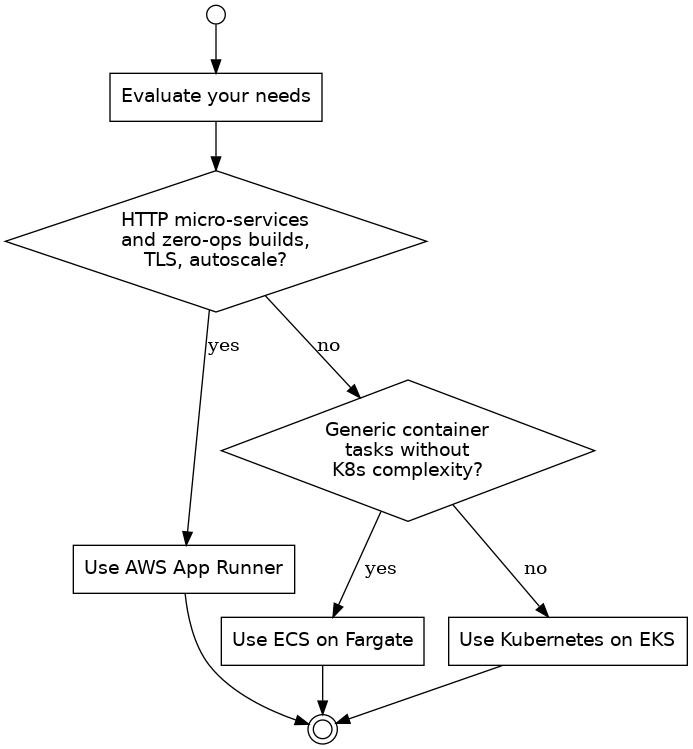
When might you choose AWS App Runner or ECS on Fargate over Kubernetes on EKS?
If you need HTTP micro‑services and want zero‑ops builds, TLS, and autoscale, App Runner is fastest. ECS Fargate suits generic container tasks without Kubernetes complexity. Pick EKS when you require the K8s ecosystem, CRDs, or service mesh features.
700
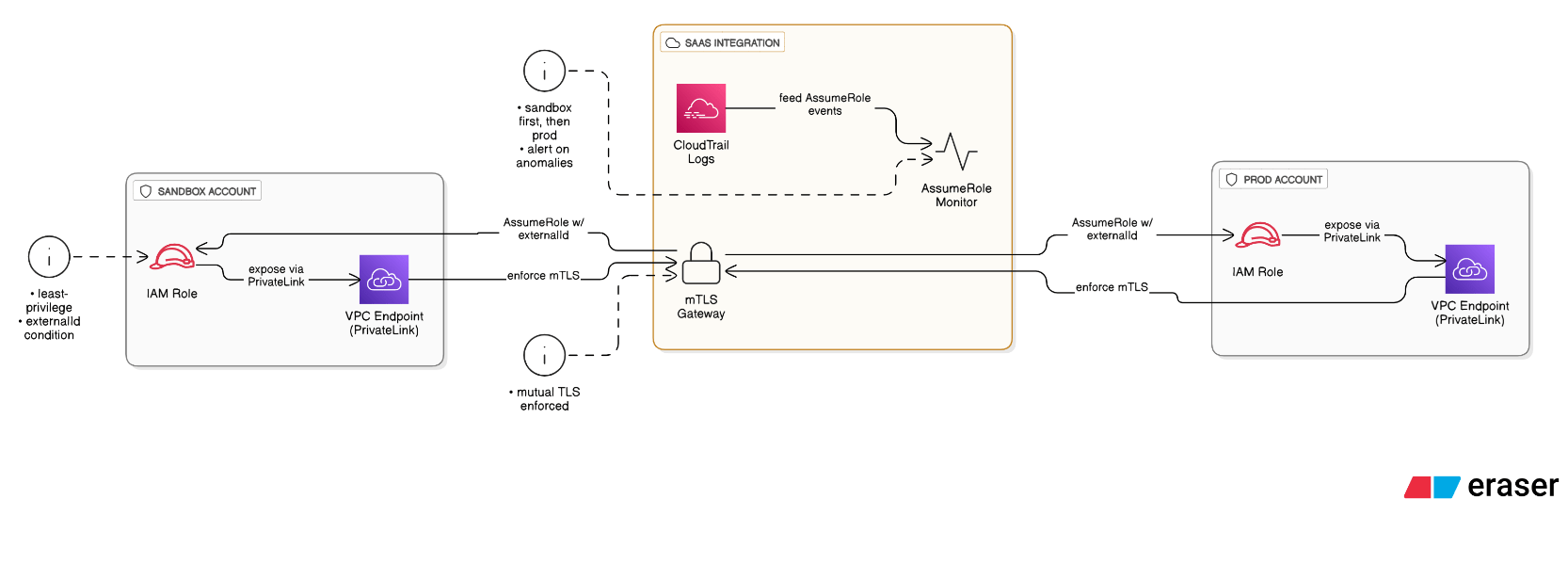
What is your strategy for securing third‑party SaaS integrations that need cross‑account IAM access?
Provision least‑privilege IAM roles with externalId conditions, expose access via PrivateLink endpoints when possible, enforce mTLS, monitor AssumeRole events in CloudTrail, and sandbox the SaaS in an isolated account before production enablement.
700
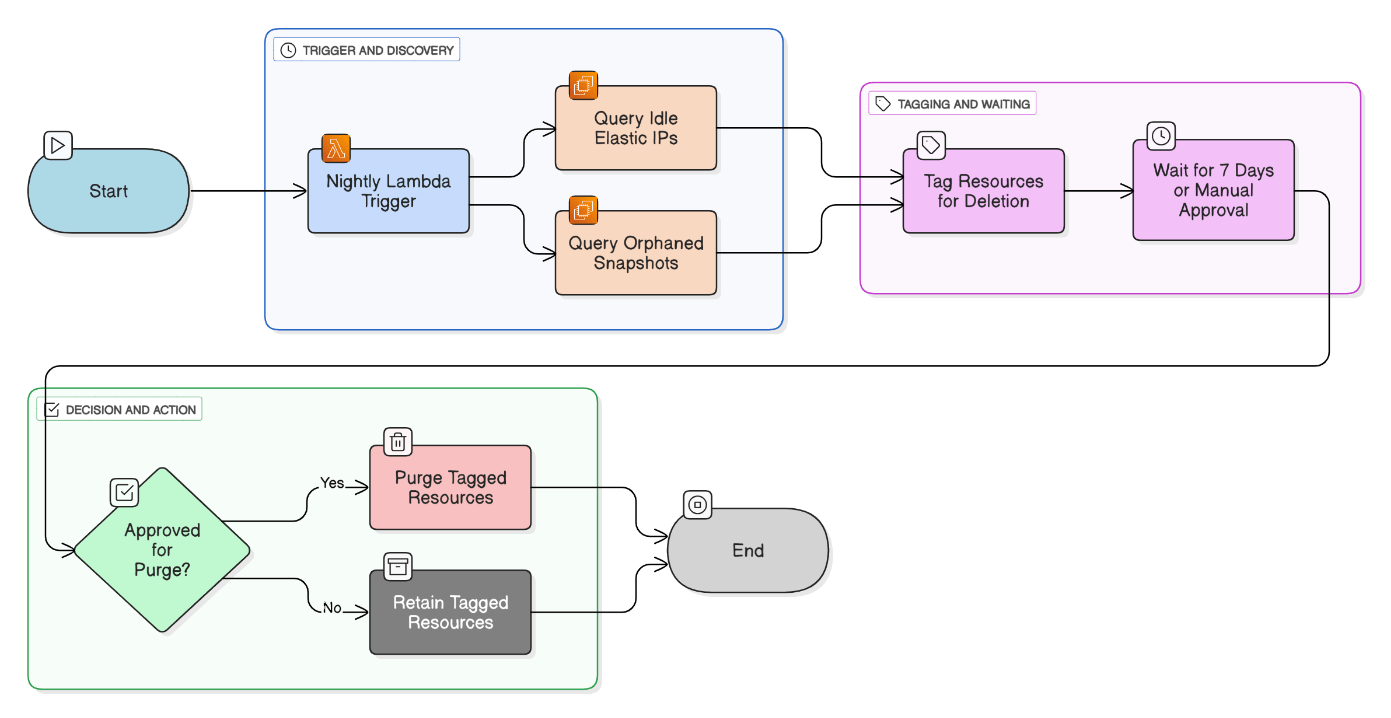
Outline an automated approach for killing zombie resources across accounts.
Nightly Lambda queries Resource Groups Tagging API, finds idle EIPs, orphaned snapshots >90 days, stages deletion with a 7‑day tag, and purges after approval.
700
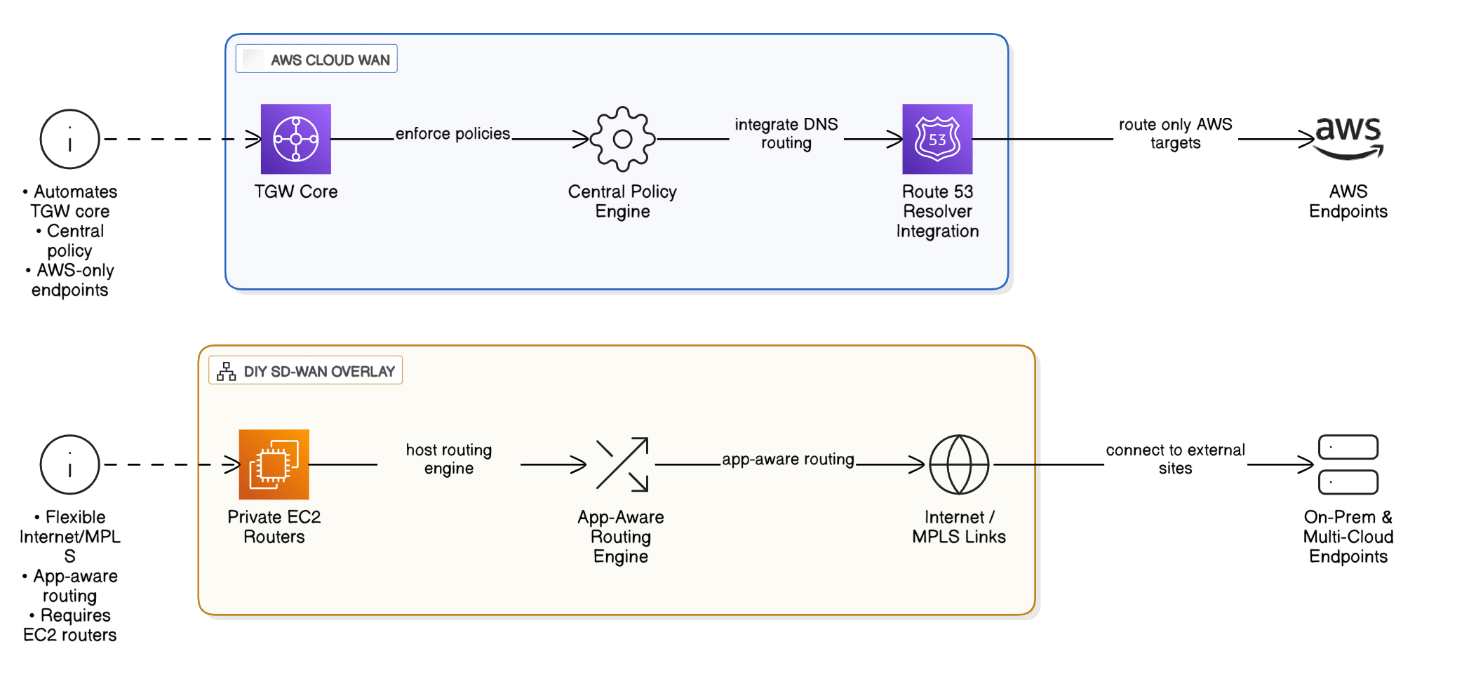
Compare AWS Cloud WAN to DIY SD‑WAN overlays.
Cloud WAN automates TGW core, centralizes policy, integrates with Route 53 Resolver, but only AWS endpoints. DIY SD‑WAN offers app‑aware routing over Internet/MPLS but needs private EC2 routers.
700
Explain drift detection at scale and how you remediate.
Enable Terraform Cloud drift alerts, run AWS Config rules, diff results, send Slack summary, and auto‑apply low‑risk changes via Terraform Cloud run‑tasks.
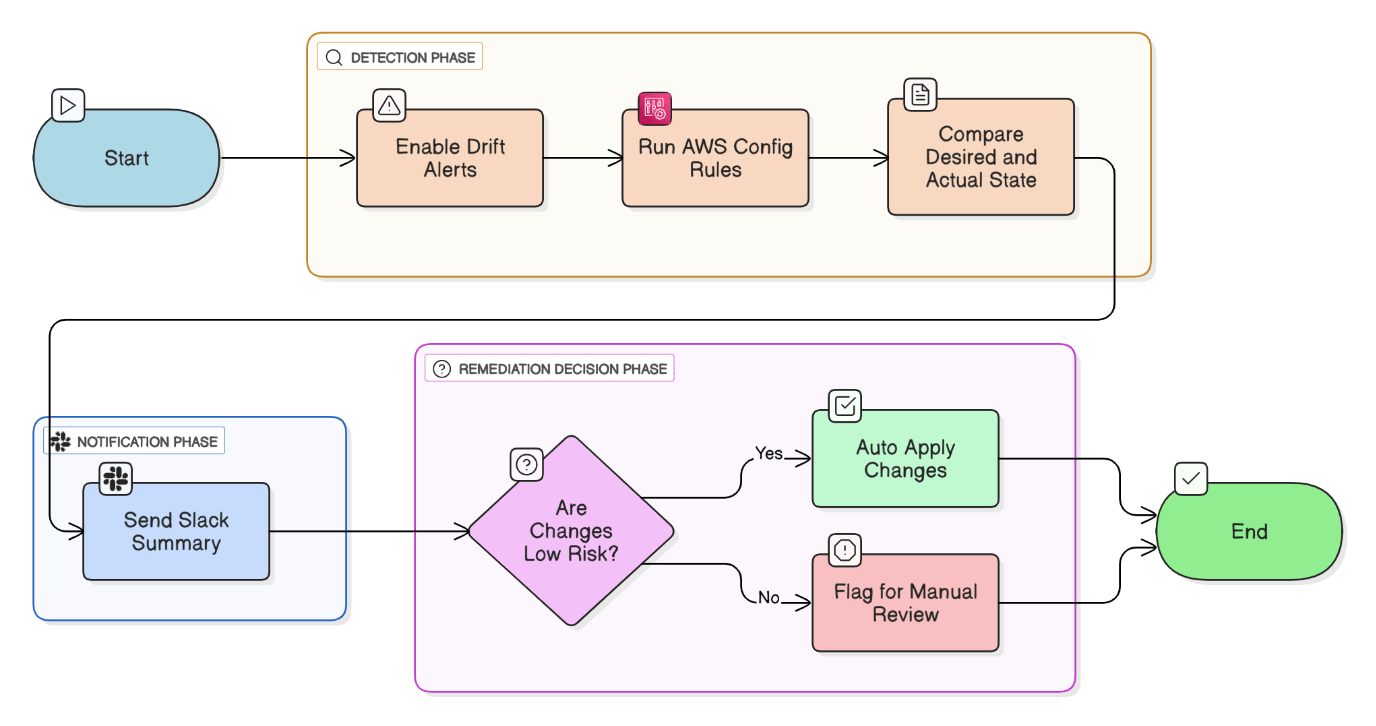
700
What metrics determine promotion from staging to production?
100 % test pass, p95 latency within SLO, error rate <0.1 %, zero critical vulnerabilities, cost delta <5 %, and stakeholder sign‑off.
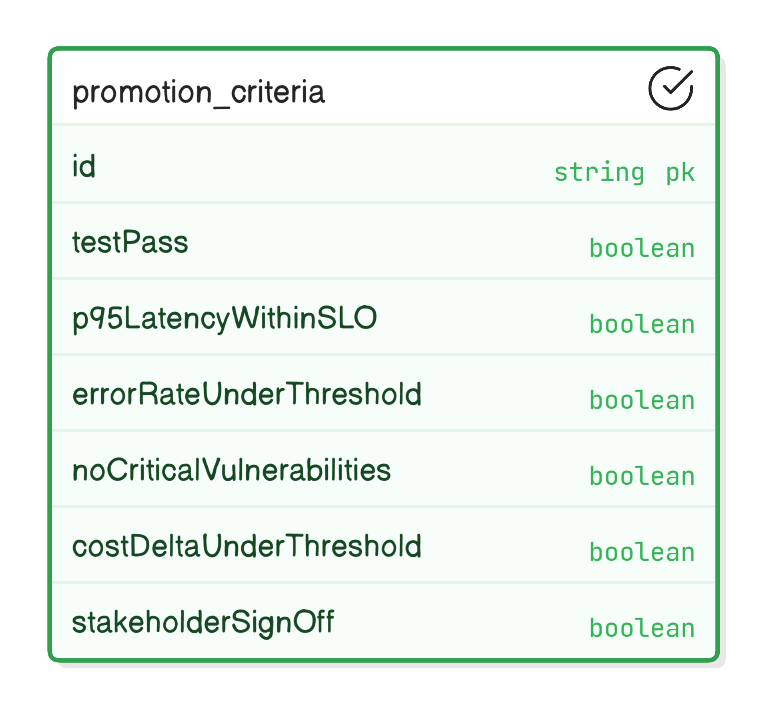
700
Compare Lambda Powertools with custom middleware for observability.
Powertools provides out‑of‑box structured logging, metrics, and tracing, reducing boilerplate; custom middleware offers flexibility but increases maintenance; Powertools is preferred for standardization.
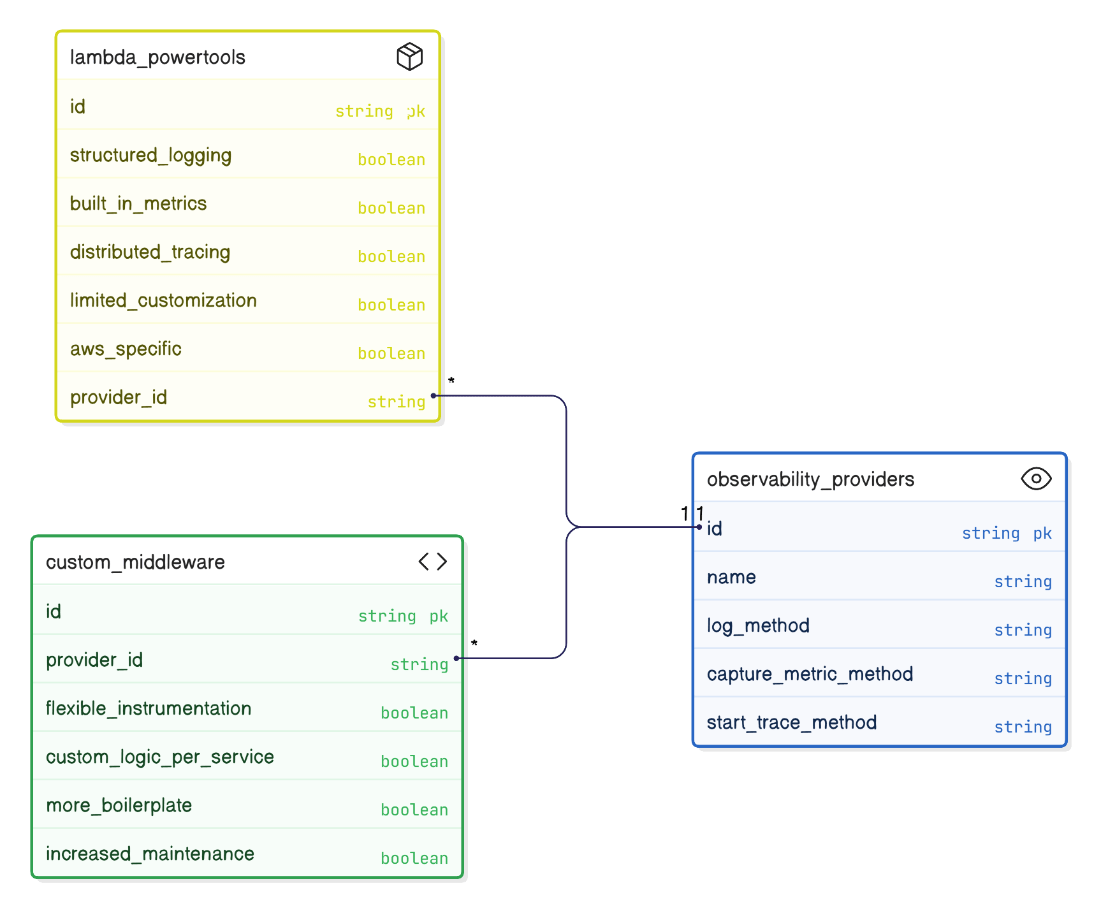
700
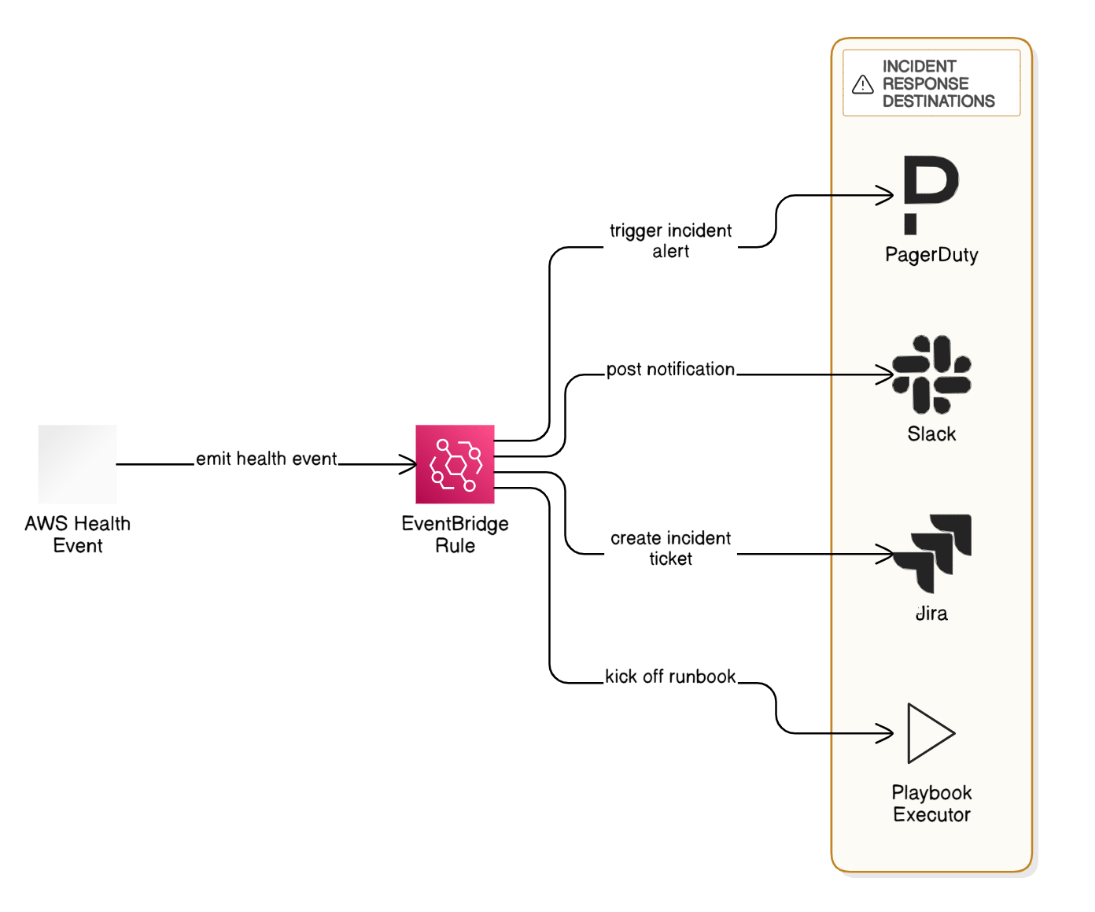
Explain how you would integrate AWS Health events with your incident‑response tooling.
EventBridge rule captures Health events, pushes to PagerDuty and Slack, creates Jira incident ticket, and kicks off playbook.
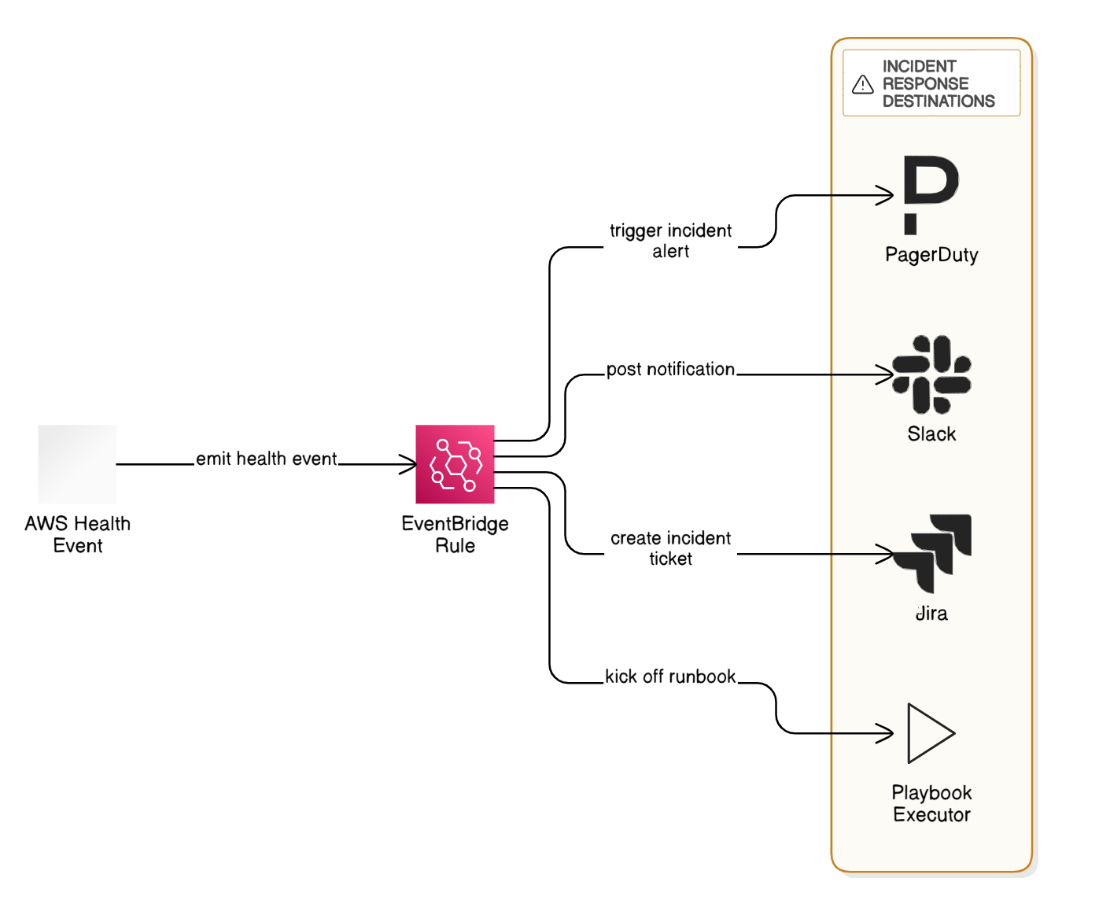
700
Explain proactive capacity planning using historical trend analysis and predictive autoscaling.
Feed CloudWatch metrics into Prophet forecasting, adjust ASG predictive scaling policies, and review quarterly with FinOps.
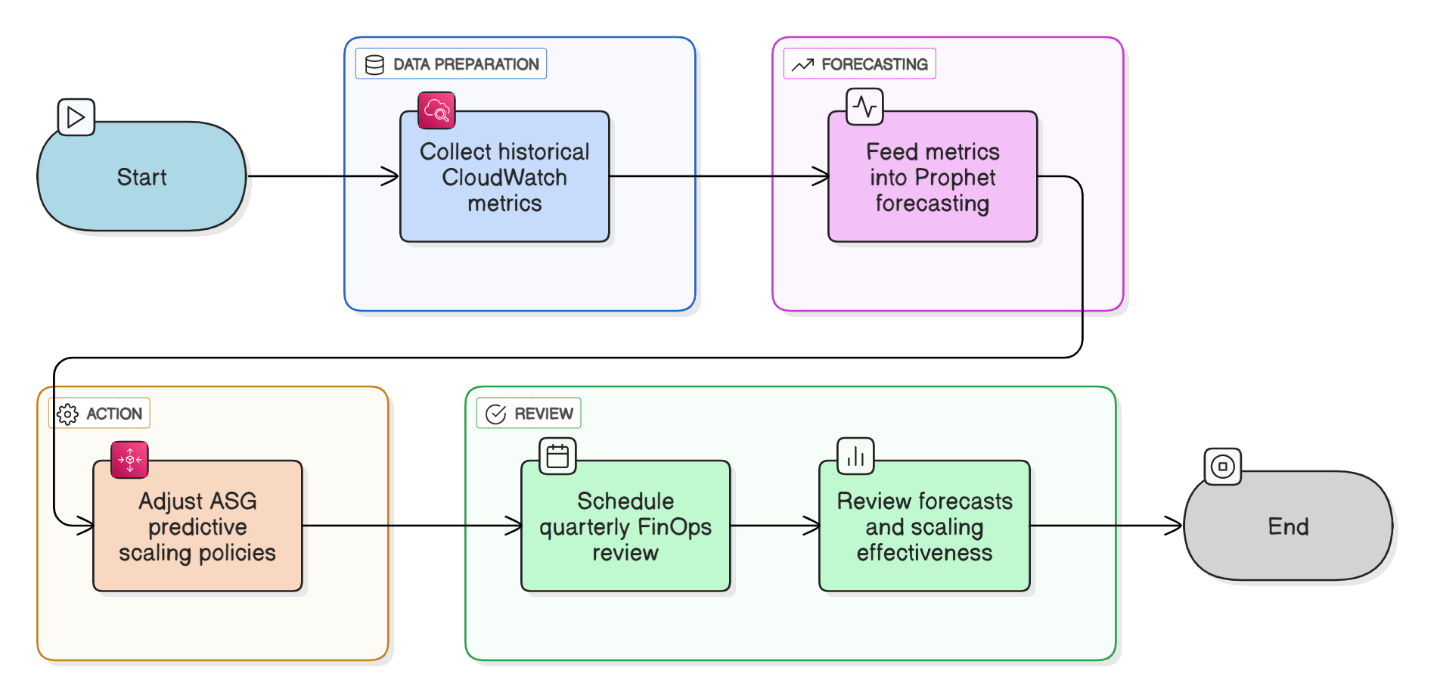
700
How do you quantify and communicate the business value of reliability investments?
Translate SLO minutes saved into revenue protection, customer churn avoidance, and engineering load reduction, then present ROI.
800
What patterns do you follow to migrate a stateful monolith to micro‑services in AWS without downtime?
Employ the strangler‑fig: put a facade in front, extract bounded contexts individually, share data via change‑data‑capture streams (Kinesis/SNS), dual‑write or event‑source, shift traffic via blue‑green, de‑couple schema with view materialization until service owns data.
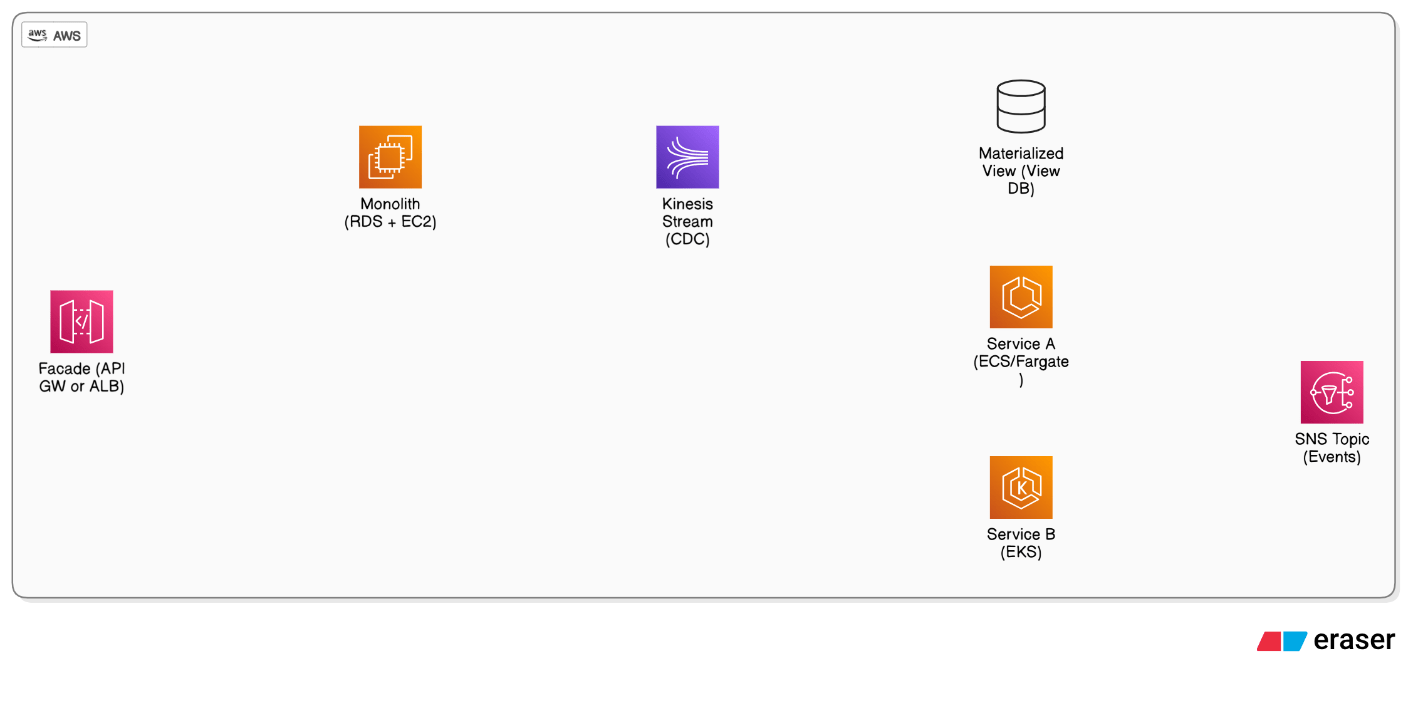
800
Discuss the implications of Nitro Enclaves and confidential computing for regulated data workloads.
Nitro Enclaves isolates memory and CPU for tokenization/PII workloads, reducing PCI scope; it keeps plaintext keys off the host OS, integrates with KMS attestation, and satisfies regulator requirements for hardware‑based isolation without losing cloud elasticity.
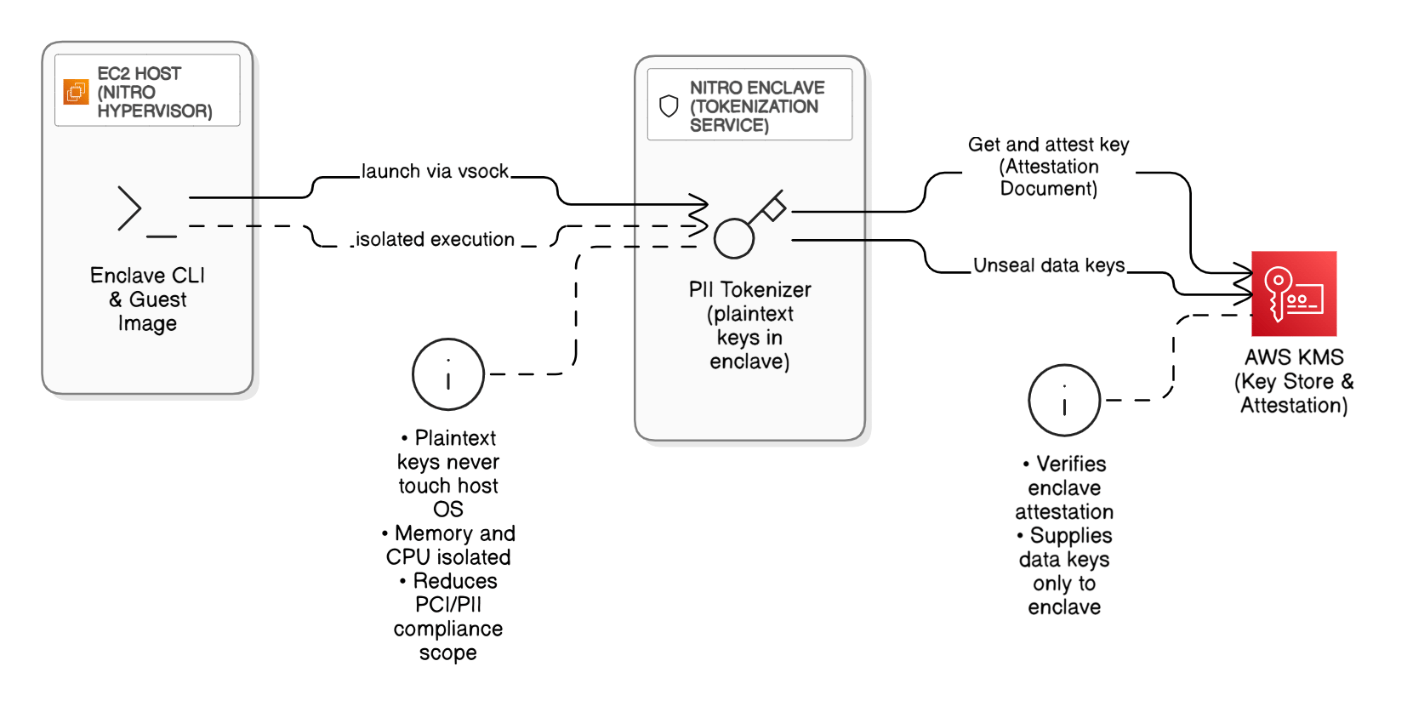
800
How do you integrate cost‑anomaly alerts into incident management?
Enable AWS Cost Anomaly Detection → EventBridge → PagerDuty; run triage playbook that queries CUR, maps change to recent deploy, and escalates if >\$1k.
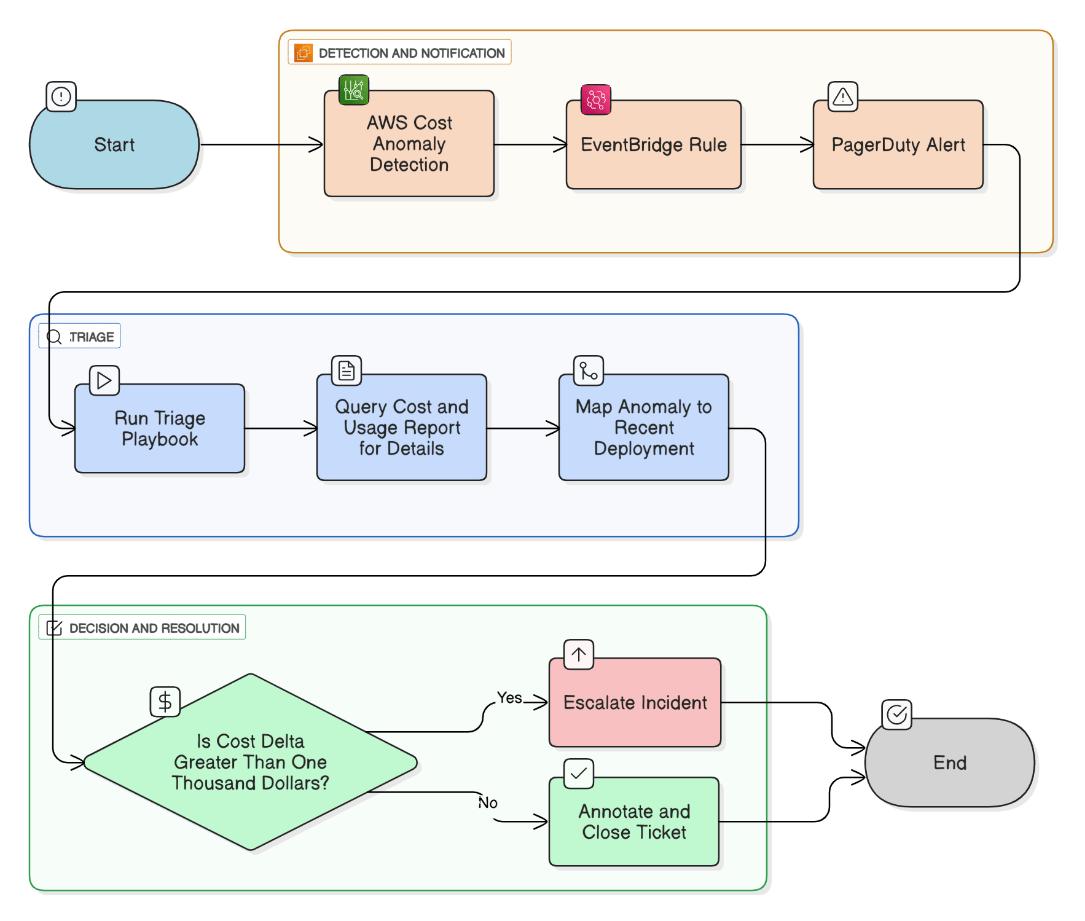
800
What techniques do you use to troubleshoot intermittent TLS handshake failures on ALB?
Enable ELB access logs, grep for `-1` SSL code, validate certificate chain, test ciphers via `openssl s_client`, check target response times and ALB idle timeouts.
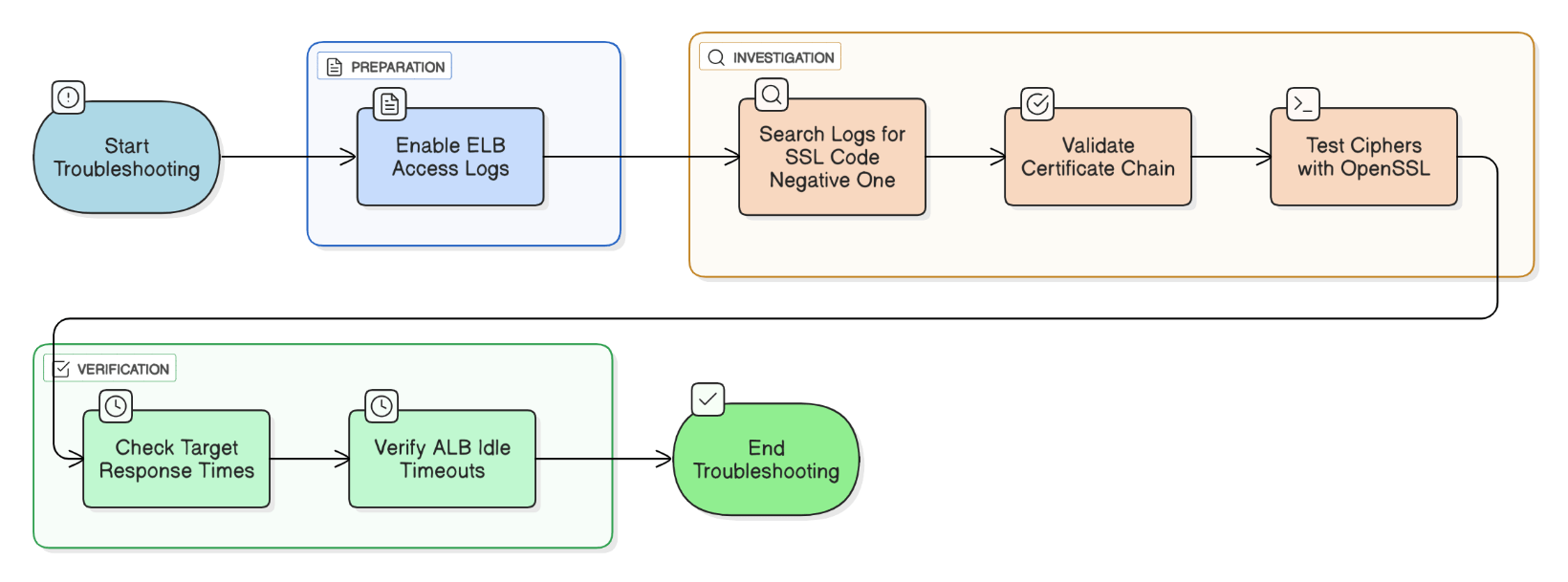
800
How do you architect GitOps for Kubernetes with Argo CD or Flux in a regulated industry?
Store manifests in signed Git repos, use Argo CD AppProjects to restrict namespace access, enforce PR reviews, deploy OPA admission controller, and log every sync event to SIEM.
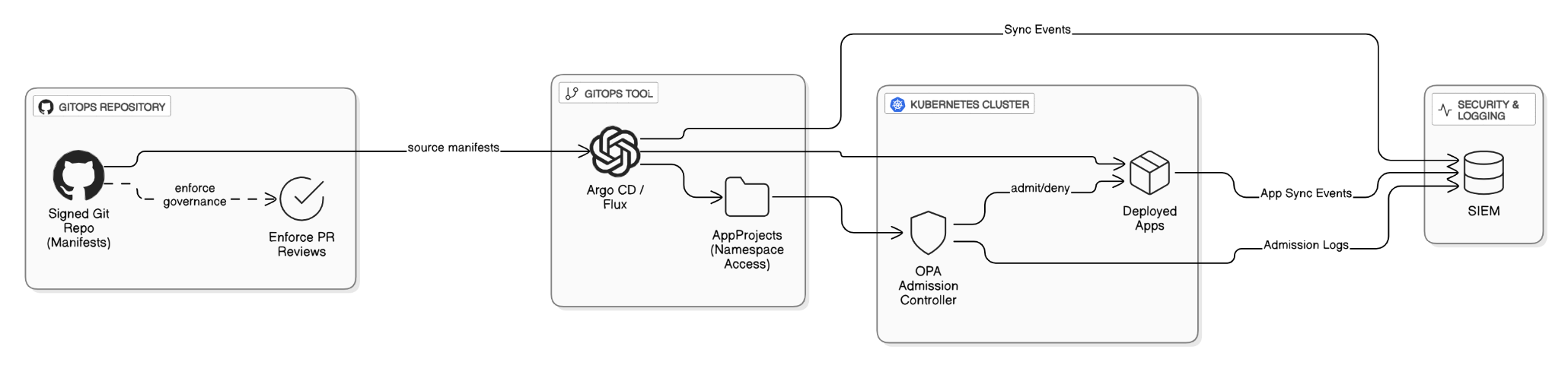
800
Discuss how to parallelize large test suites without eroding coverage.
Shard tests via pytest‑xdist, store coverage in Codecov, employ historical timing for balancing, and retry flaky tests with exponential backoff.
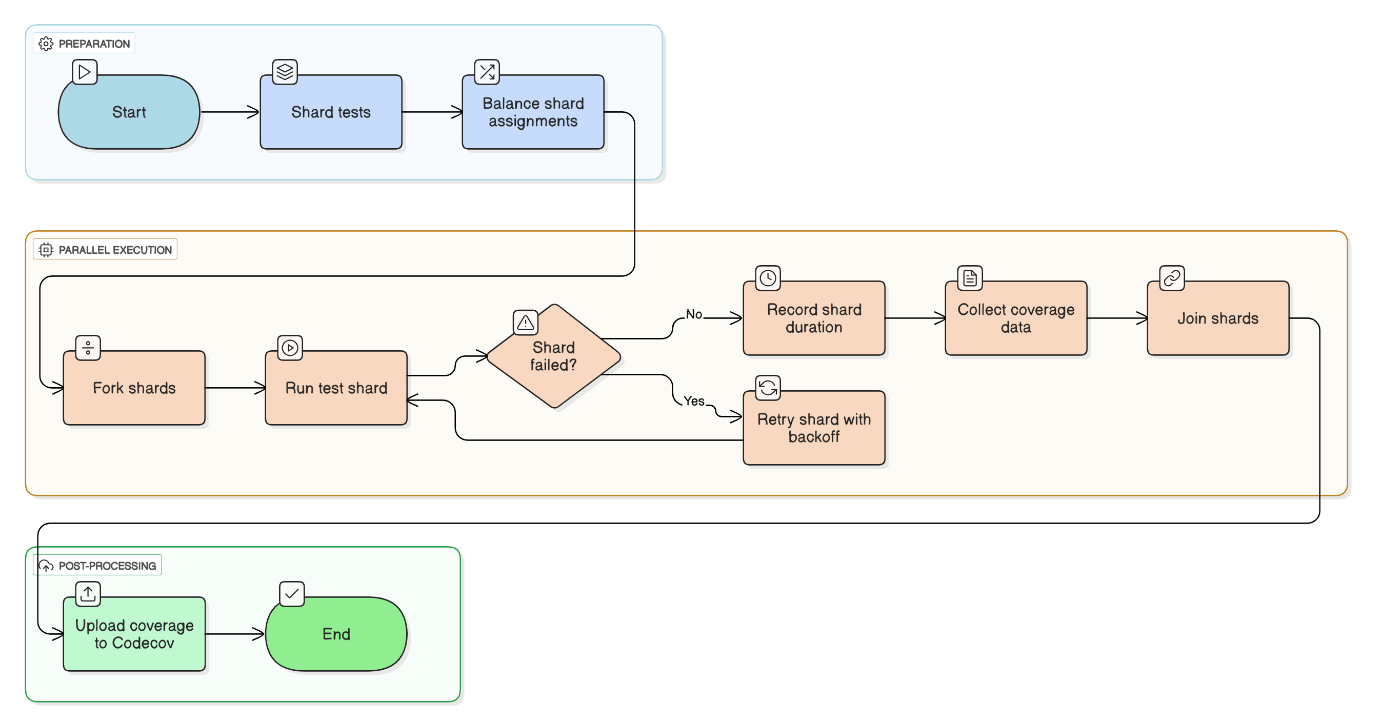
800
Explain how you troubleshoot intermittent cold‑start issues in Lambda APIs behind ALB.
Monitor `InitDuration`, reduce bundle size, use provisioned concurrency, switch runtime to ARM, and keep connection pools warm via CloudWatch Events keep‑alive.

800
Discuss chaos‑engineering experiments you’ve run on production (or pre‑prod) Kubernetes clusters.
Used LitmusChaos to kill CoreDNS pods, observed retry storm, tuned readiness probes, and added fallback resolver.
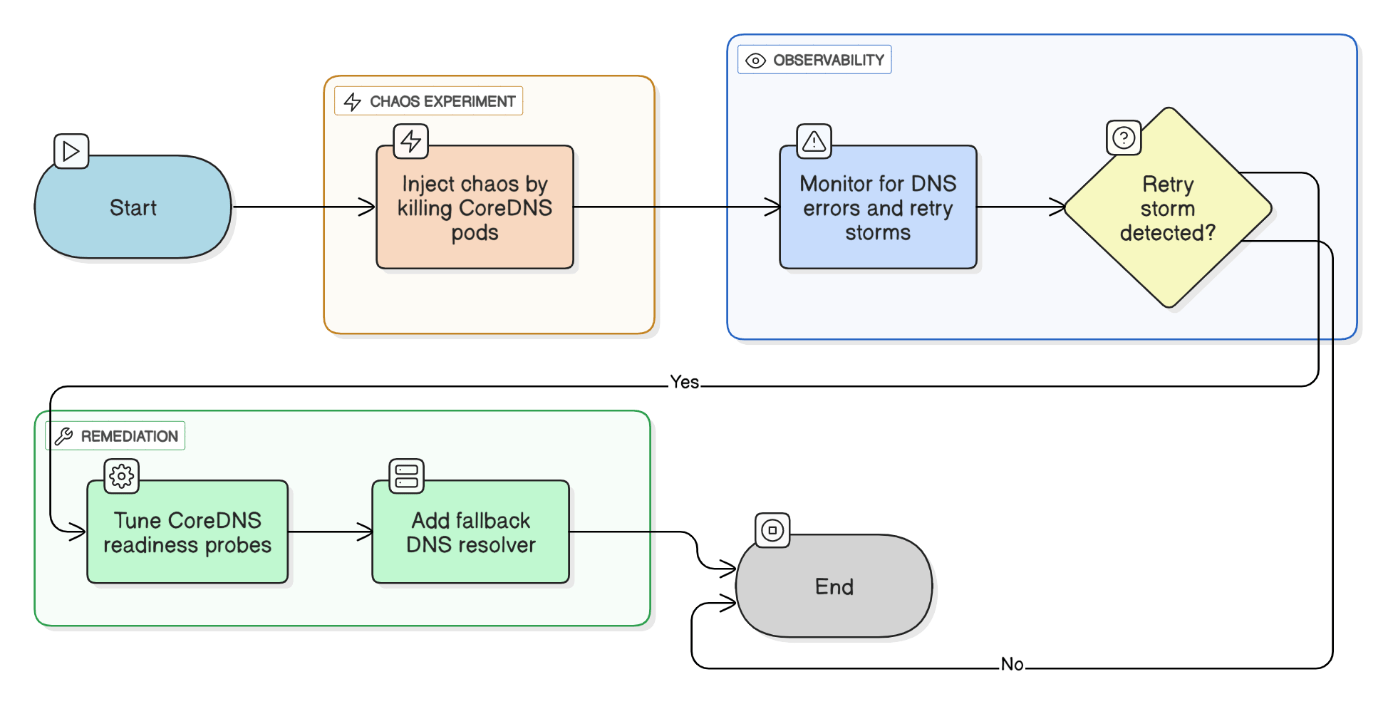
800
Compare leader‑election mechanisms in multi‑Region distributed systems (e.g., DynamoDB TTL vs. ZooKeeper).
DynamoDB conditional writes offer low‑ops but eventual failover; ZooKeeper gives strong consistency but requires VM quorum and cross‑Region WAN tuning.
800
Discuss strategies for leading a zero‑trust transformation across legacy and cloud workloads.
Start with identity centralization, enforce mTLS, implement identity‑aware proxies, phase out legacy VPNs, and measure success via pen‑tests.
900
Outline an approach for multi‑Region active‑active data consistency under strict RPO/RTO constraints.
Use globally replicated data stores (DynamoDB Global Tables/Aurora Global Database), implement idempotent writes and conflict resolution (vector clocks), partition users to nearest Region, employ Route 53 latency records, and test failover via chaos engineering.
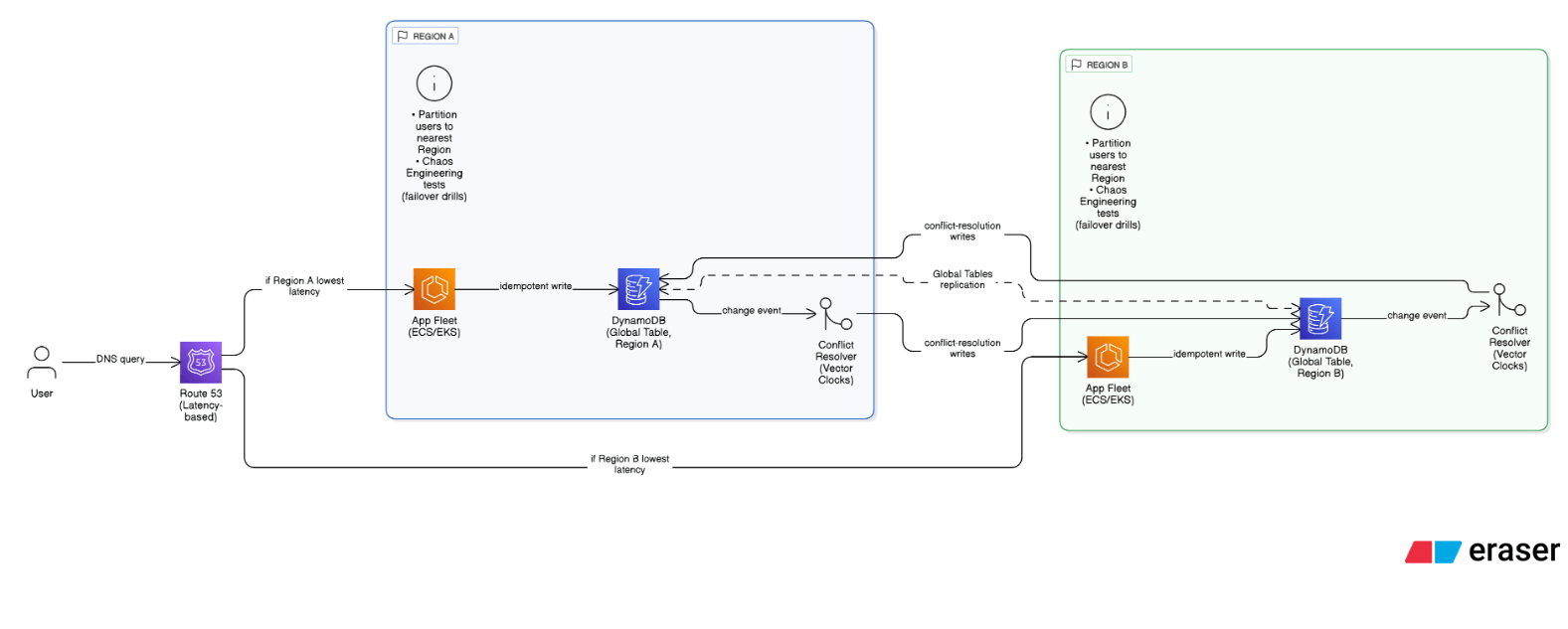
900
How do you detect and mitigate privilege‑escalation paths in IAM roles?
Run CloudSplaining and IAM‑Access‑Analyzer to enumerate risky actions like iam:PassRole or sts:AssumeRole*, quarantine offending roles via SCP‑based deny, and add preventative boundary policies blocking escalation vectors.
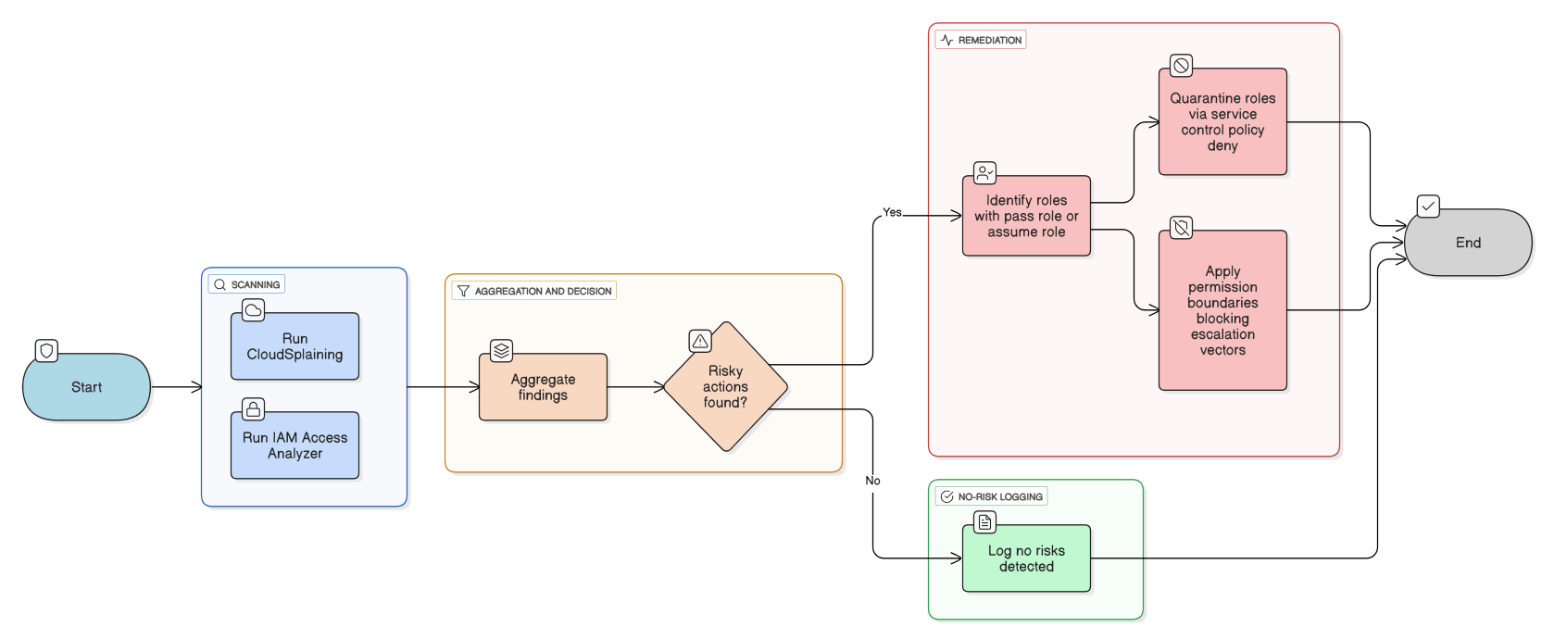
900
Explain chargeback vs showback models and when each is appropriate.
Showback surfaces costs without billing; good for cultural adoption. Chargeback invoices cost centers once tagging >95 % accurate; drives accountability but requires financial tooling.
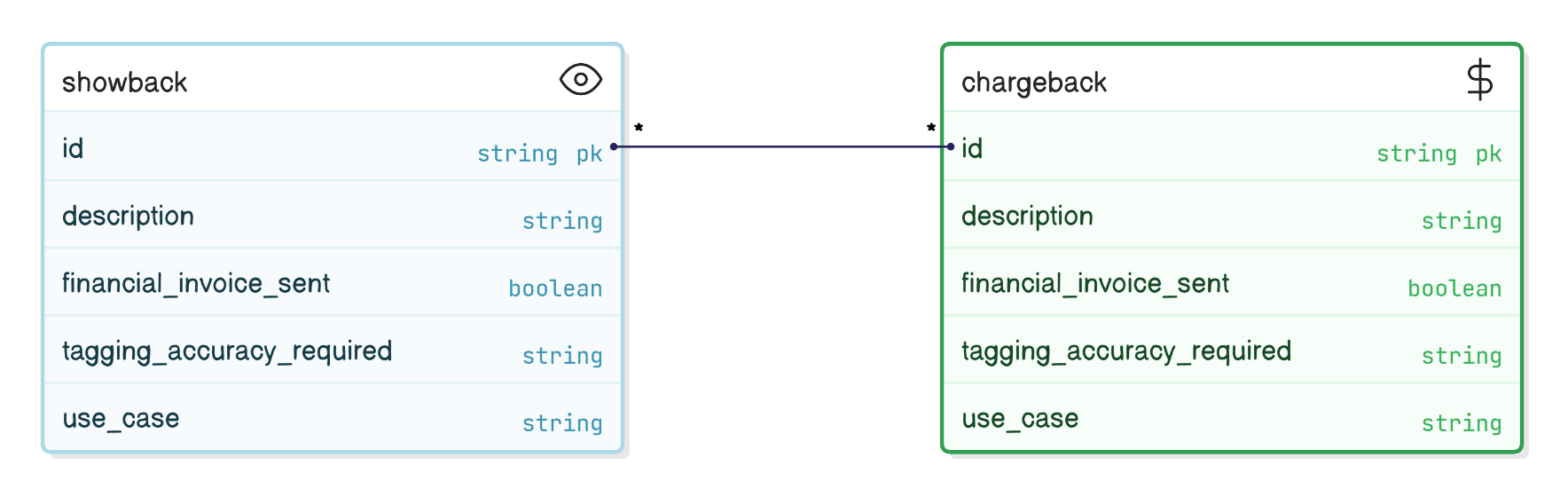
900
Describe the networking considerations when running Kubernetes Network Policies versus AWS Security Groups.
SGs operate at ENI level and cover node‑to‑node; Network Policies apply pod‑to‑pod L3/L4 via CNI plugin; enforce both for layered defense, mind CIDR mask differences.
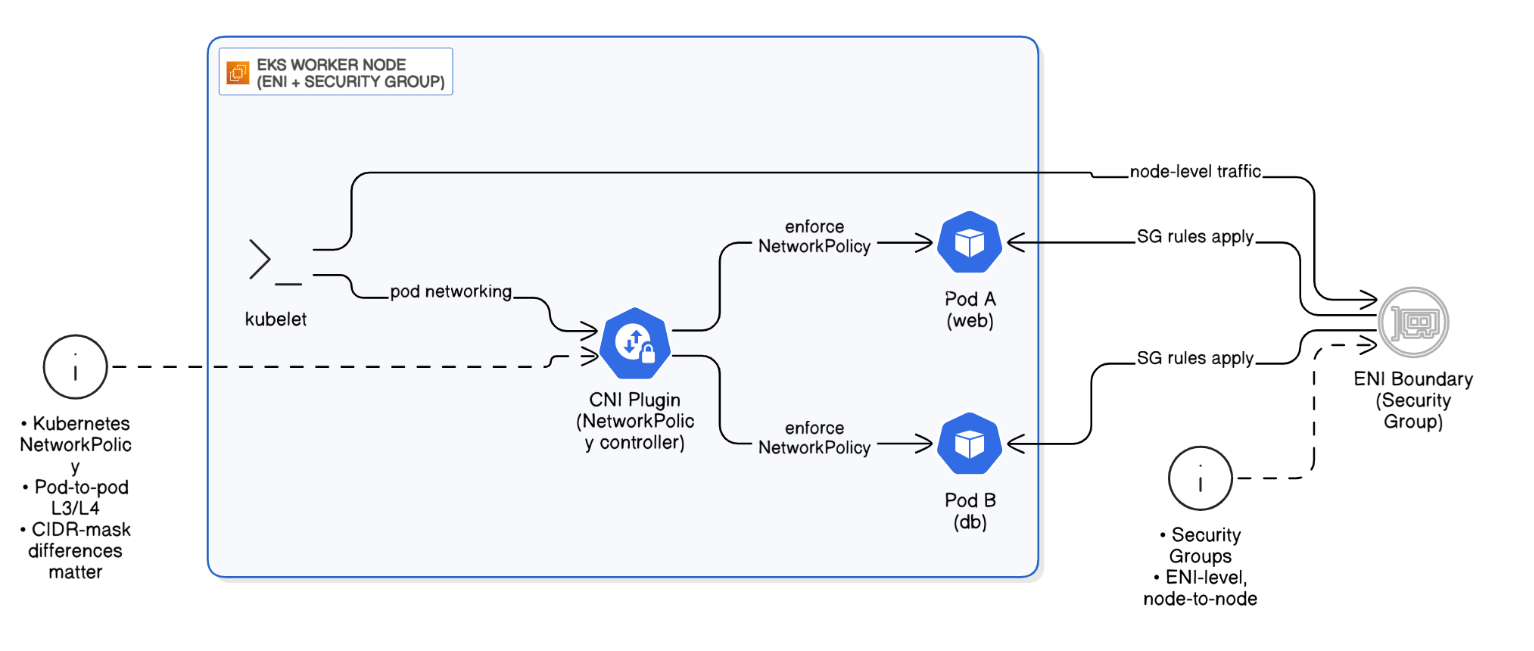
900
Discuss the role of OpenTelemetry in IaC pipelines.
Instrument Terraform runs via OTLP exporter, capture duration, resource counts, failure rate, and visualize pipeline health trends in Grafana.
900
Explain the pros/cons of monolithic versus multi‑repo Helm chart repositories.
Mono‑repo simplifies dependency versioning and review, but pull requests get noisy. Multi‑repo grants service autonomy; manage common templates via helmfile or umbrella charts.
900
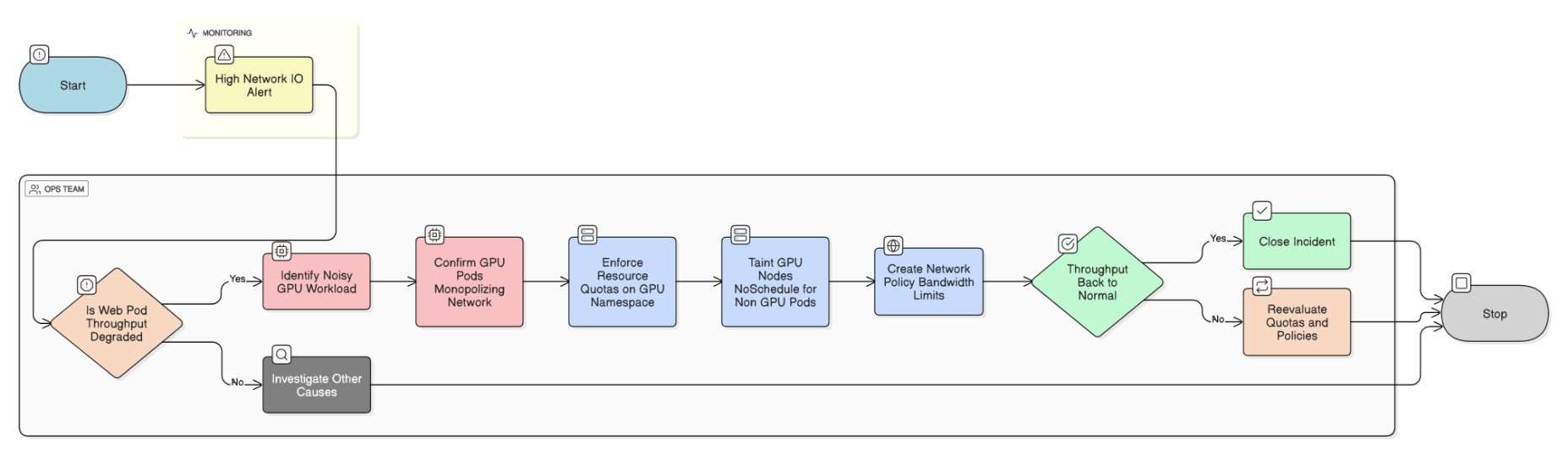
Describe a real incident caused by noisy neighbors in a shared Kubernetes cluster and how you resolved it.
GPU workload monopolized network I/O, starving web pods; enforced ResourceQuotas, tainted GPU nodes, and added NetworkPolicy bandwidth limits.
900
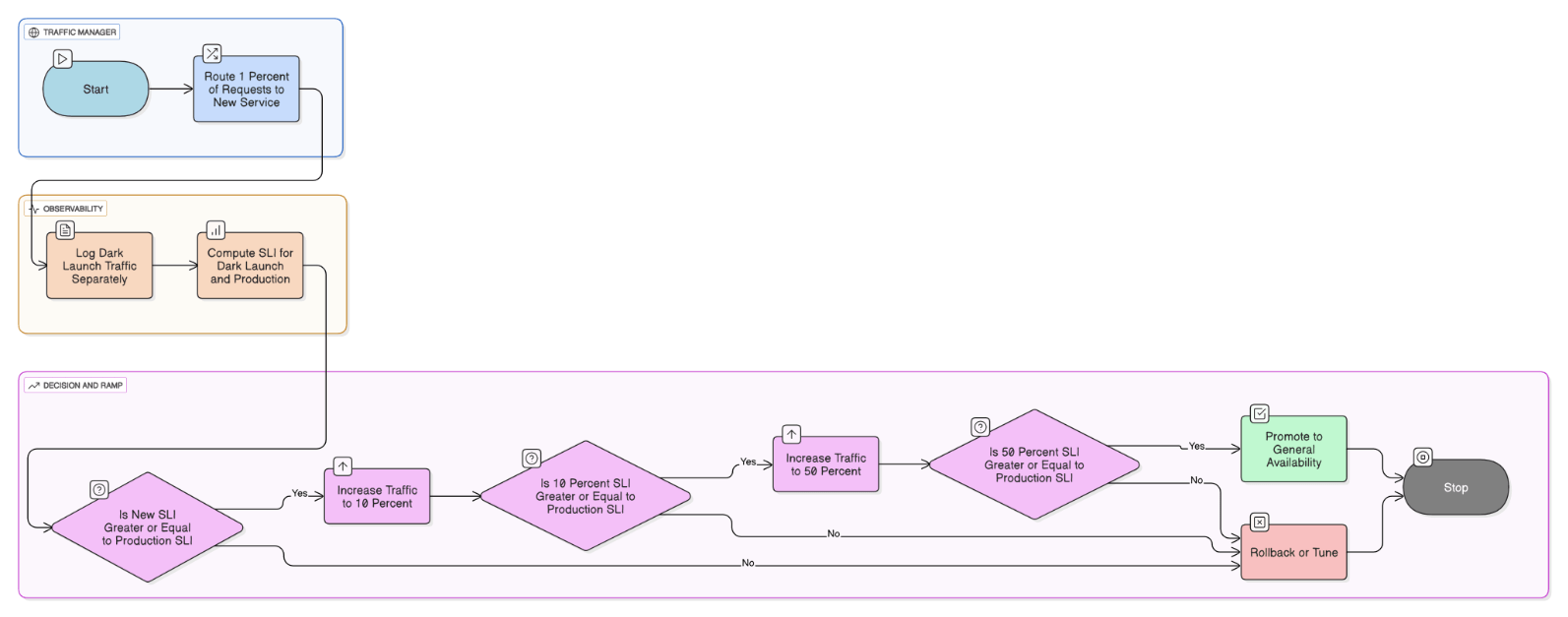
What patterns do you follow for dark‑launching new services to measure real‑user performance?
Route 1 % traffic with header flag, log separately, compare SLI, and scale to 10 %/50 % before GA.
900
What’s your approach to choosing consistency models (strong vs. eventual) under strict SLA constraints?
Classify data domains, evaluate user impact of staleness, pick strong for financial transactions, eventual for analytics, and document assumptions in ADRs.
900
Tell me about a time you had to push back on unrealistic uptime requirements; how did you negotiate a workable SLA?
Finance requested 99.99 %; modeled cost of HA multi‑Region, proposed 99.9 % with warm standby DR, demonstrated ROI break‑even, achieved agreement.
1000
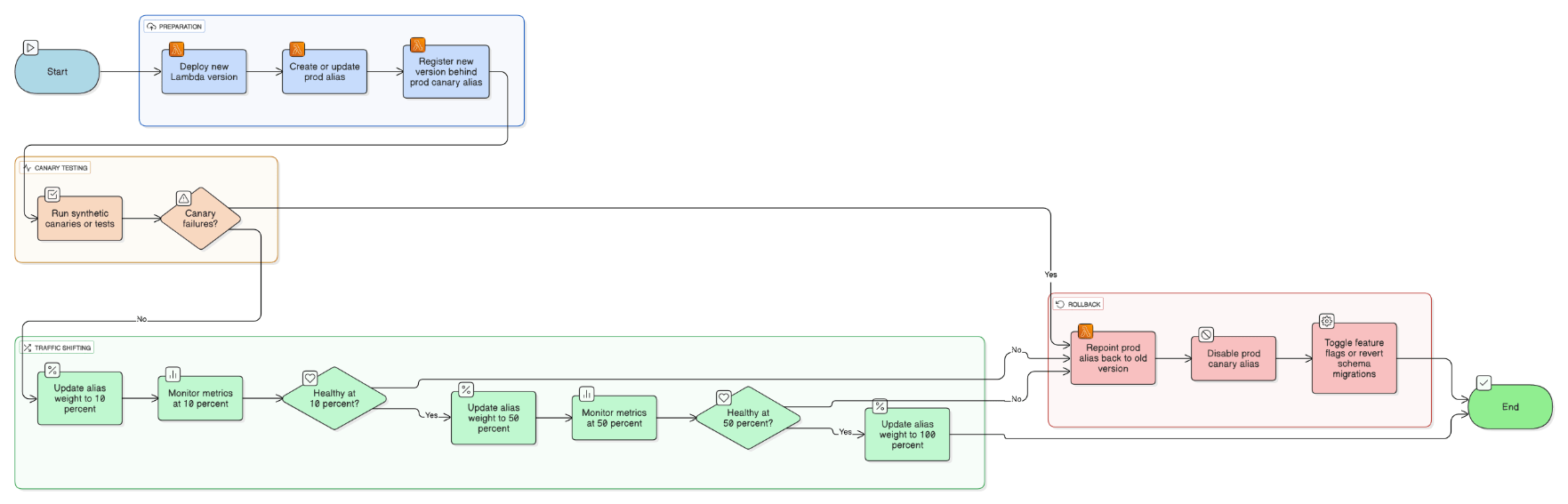
Describe how you’d implement a blue‑green deployment strategy for a Lambda‑based serverless API.
Deploy a new version behind an alias, route 0% traffic, run synthetic canaries, then shift 10→50→100 % using CodeDeploy weighted aliases. Roll back instantly by repointing alias; coordinate schema changes through feature flags.
1000
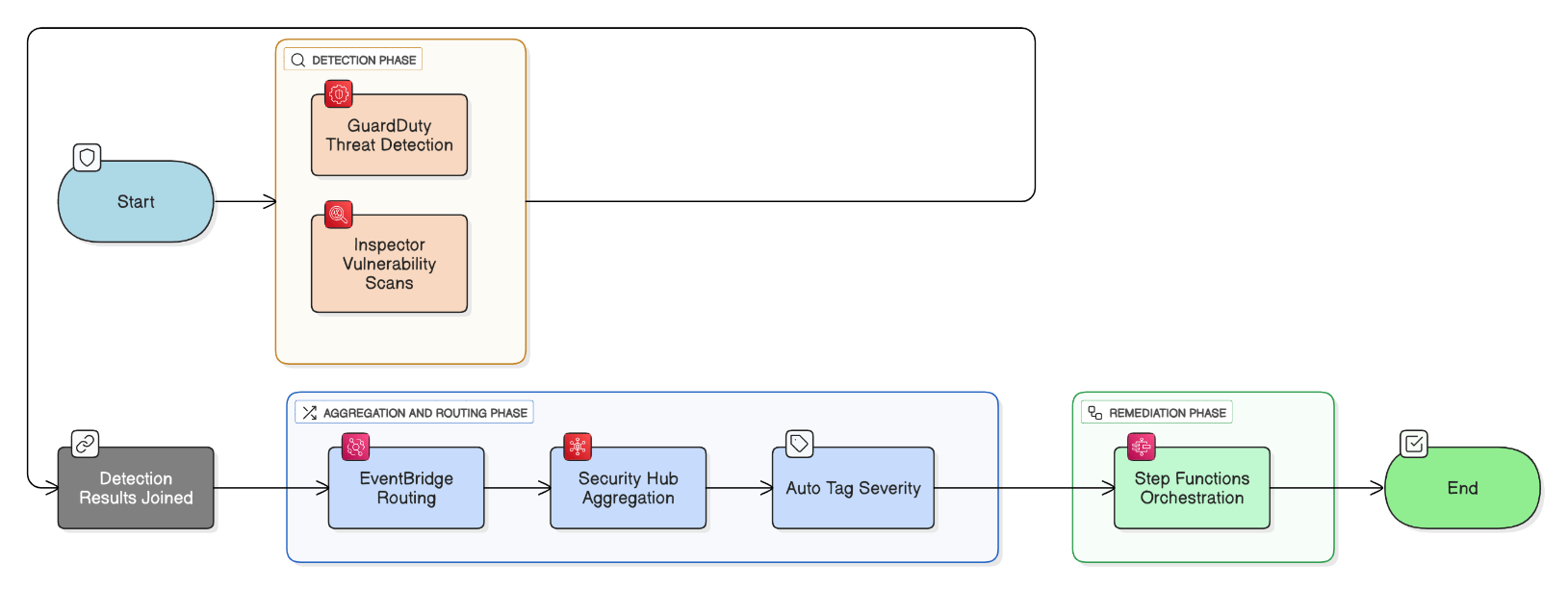
Explain the difference between Inspector, GuardDuty, and Security Hub and how you would orchestrate findings.
GuardDuty provides threat‑intel & behavioral detections; Inspector scans for host and container CVEs; Security Hub aggregates and normalizes findings. Route both tool feeds into Security Hub via EventBridge, auto‑tag severity, trigger Step Functions for remediation.
1000
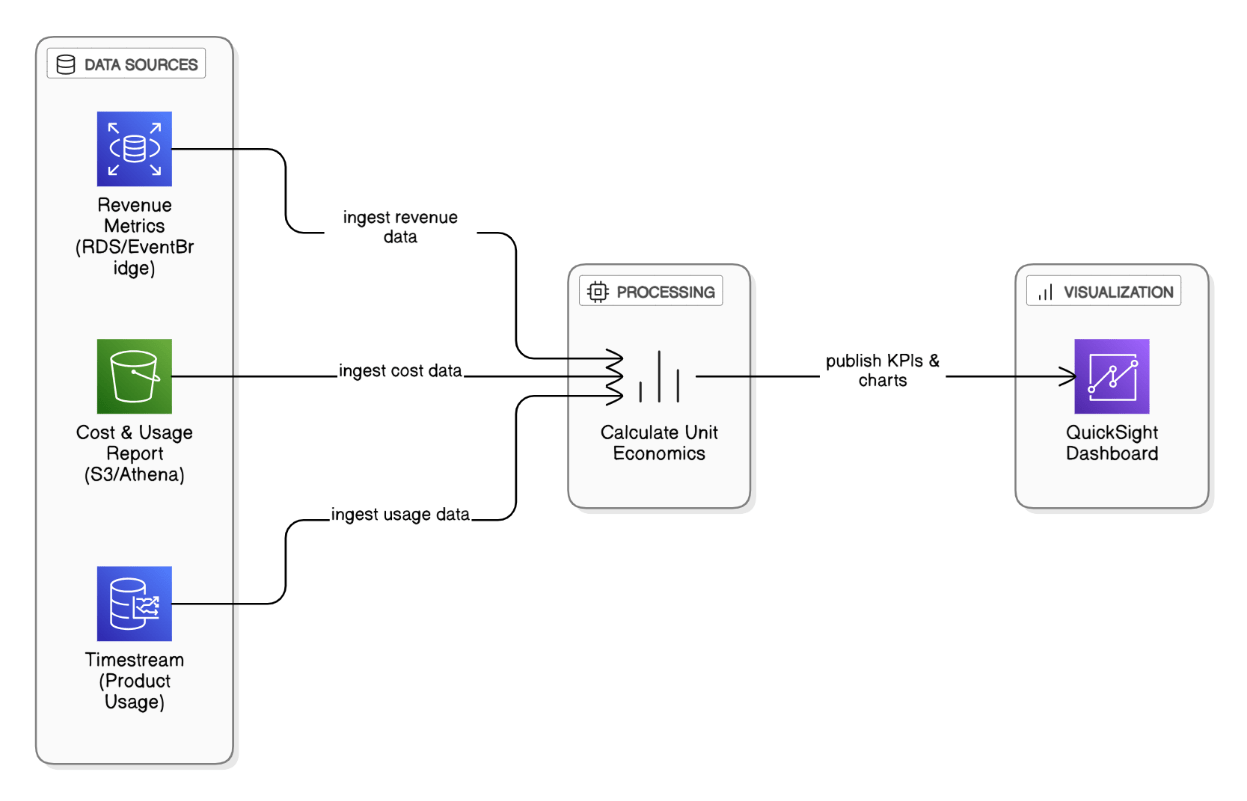
Describe how you’d build a unit‑economics dashboard for a SaaS product on AWS.
Combine CUR data with product usage metrics in Timestream, calculate cost per active user, surface in QuickSight, and align with revenue metrics for margin insight.
1000
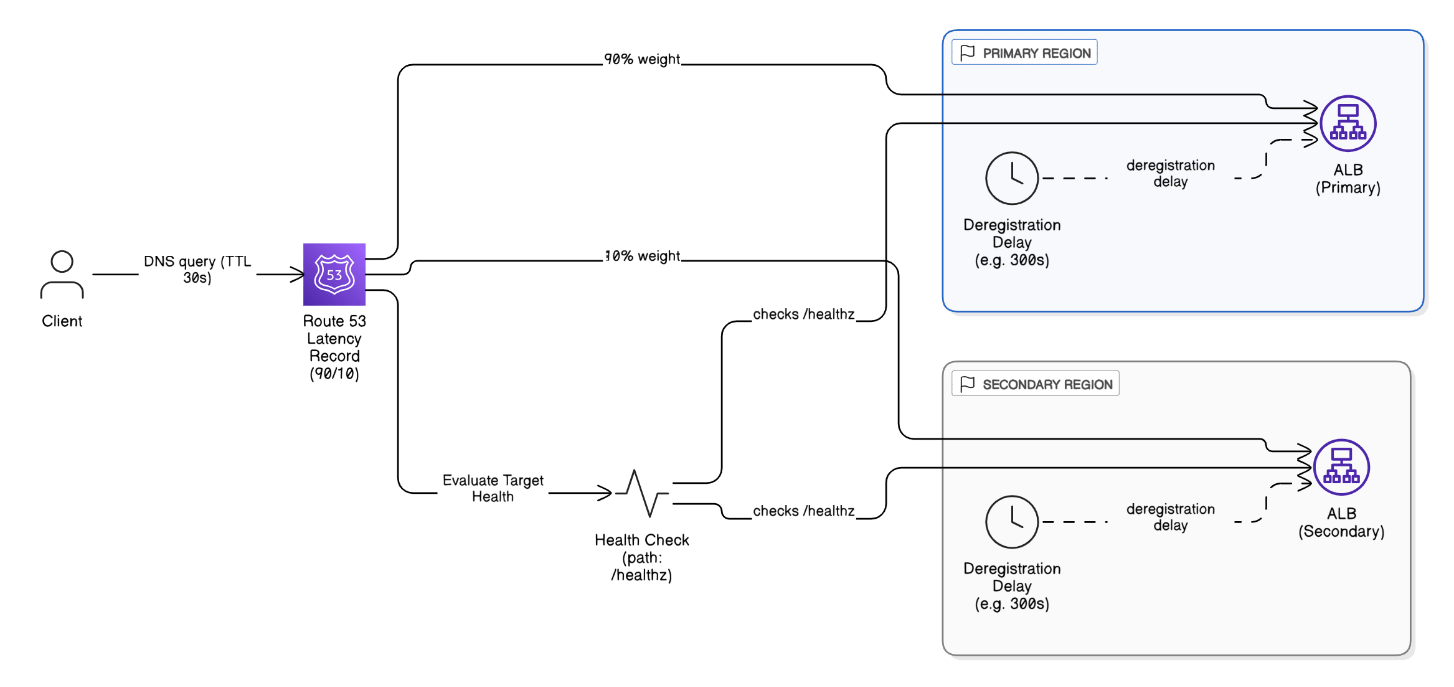
How do you design DNS failover for latency‑based routing weighted toward primary Regions?
Create latency records weighted 90/10, attach health checks to `/healthz`, enable Evaluate Target Health, tune TTL to 30 s, and use ALB deregistration delay during failover.
1000
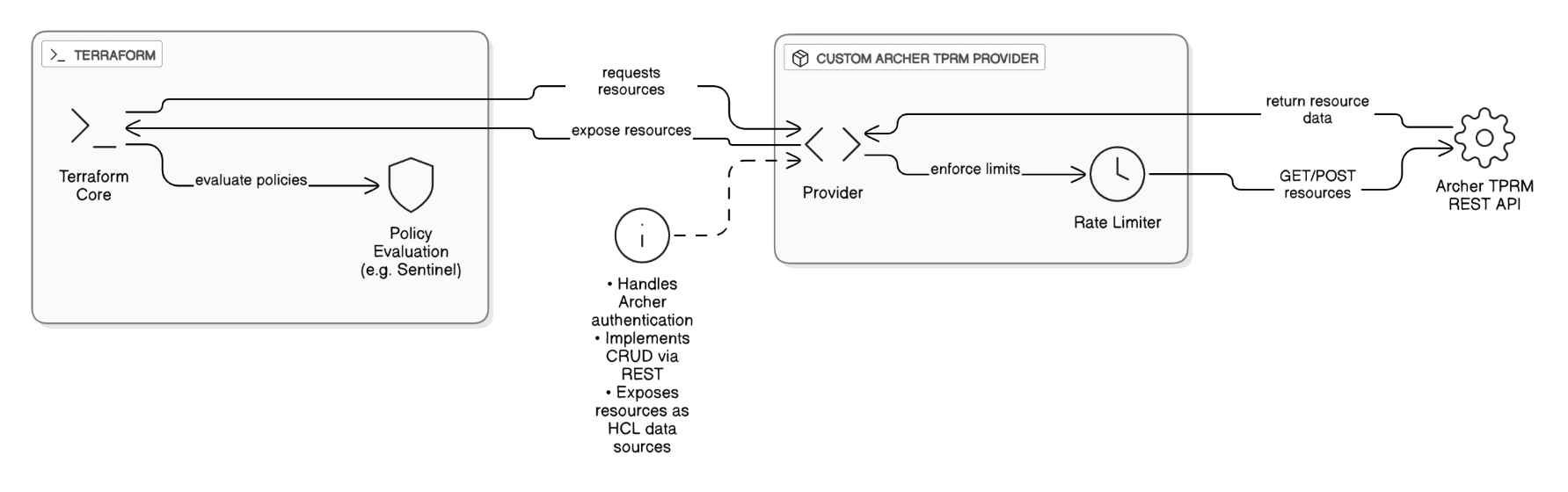
Share an example where you used custom Terraform providers or CDK constructs to solve a unique problem.
Wrote a custom provider to manage Archer TPRM resources via its REST API, handling rate‑limiting and exposing resources to policy evaluations.
1000
How would you implement feature‑flag‑driven rollouts across micro‑services?
Integrate LaunchDarkly SDK, expose flag context per customer, tie to experiment metrics, backstop with environment variables for Lambda cold‑starts.
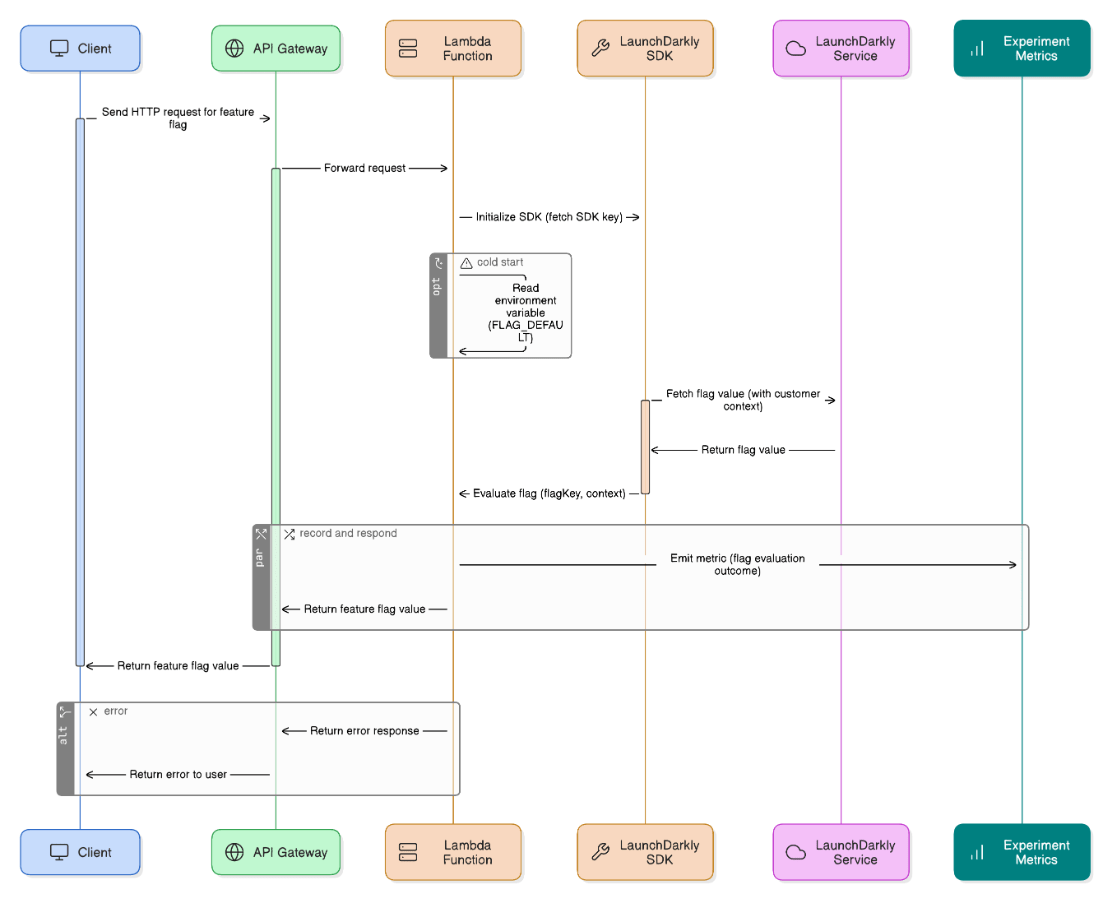
1000
How would you architect an event‑driven workflow with EventBridge Pipes, Step Functions, and Lambda?
Source events to EventBridge Pipes with input transform, Step Functions orchestrates saga, Lambda tasks idempotent, DLQ for failures, and use EventBridge Scheduler for retries.
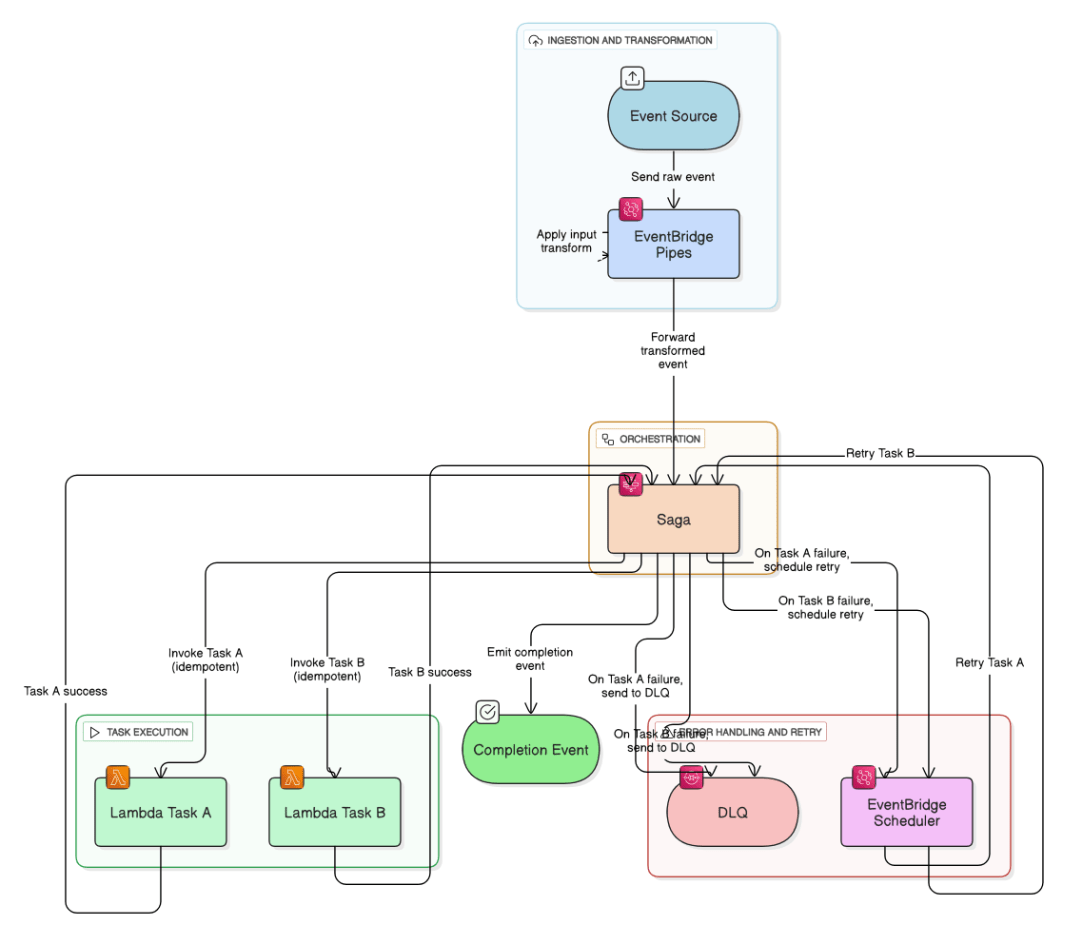
1000
How do you calculate capacity buffers for Black‑Friday‑style traffic spikes?
Forecast peak +30 % using 95th percentile historical, warm ASG nodes via scheduled scaling, and pre‑scale DB replicas.
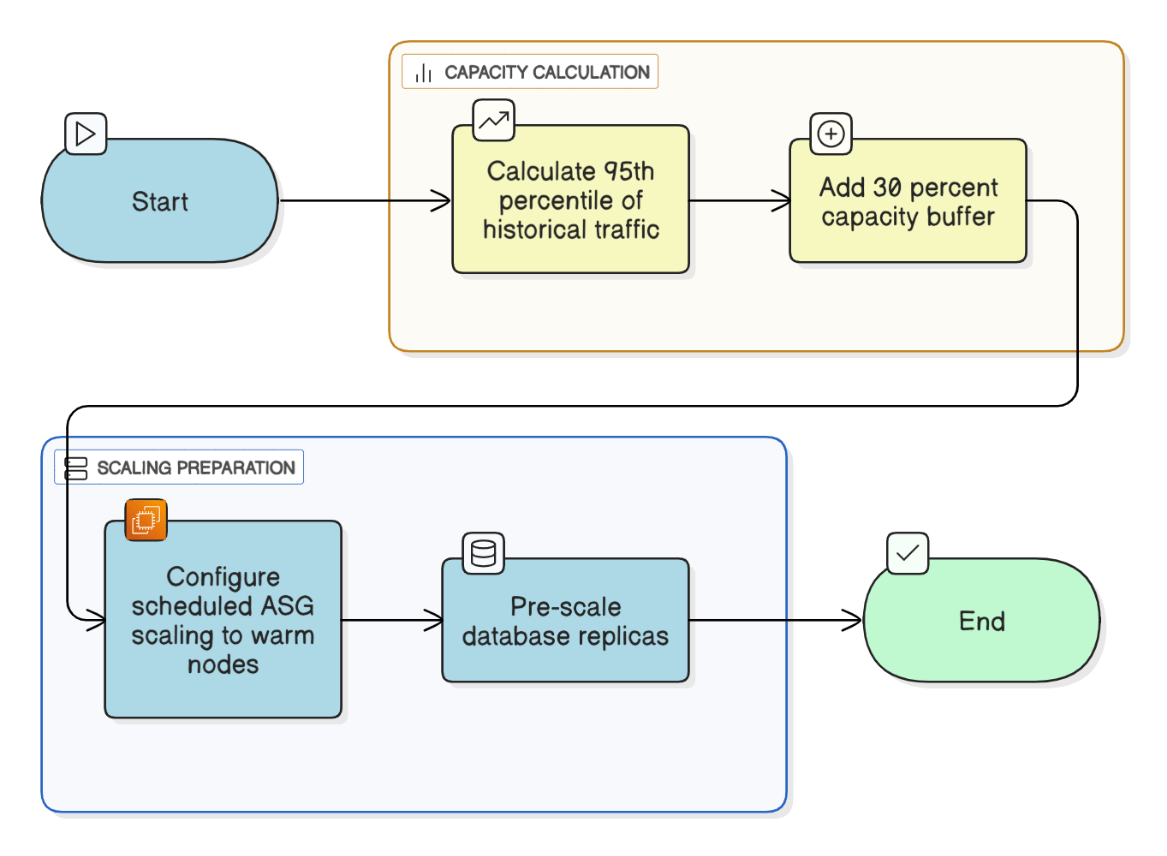
1000
Describe a time you improved a service’s SLO through error‑budget‑based prioritization.
Burn rate exceeded 2 × budget; paused feature deploys, fixed connection pool leaks, deployed canary, and SLO burn normalized within a week.
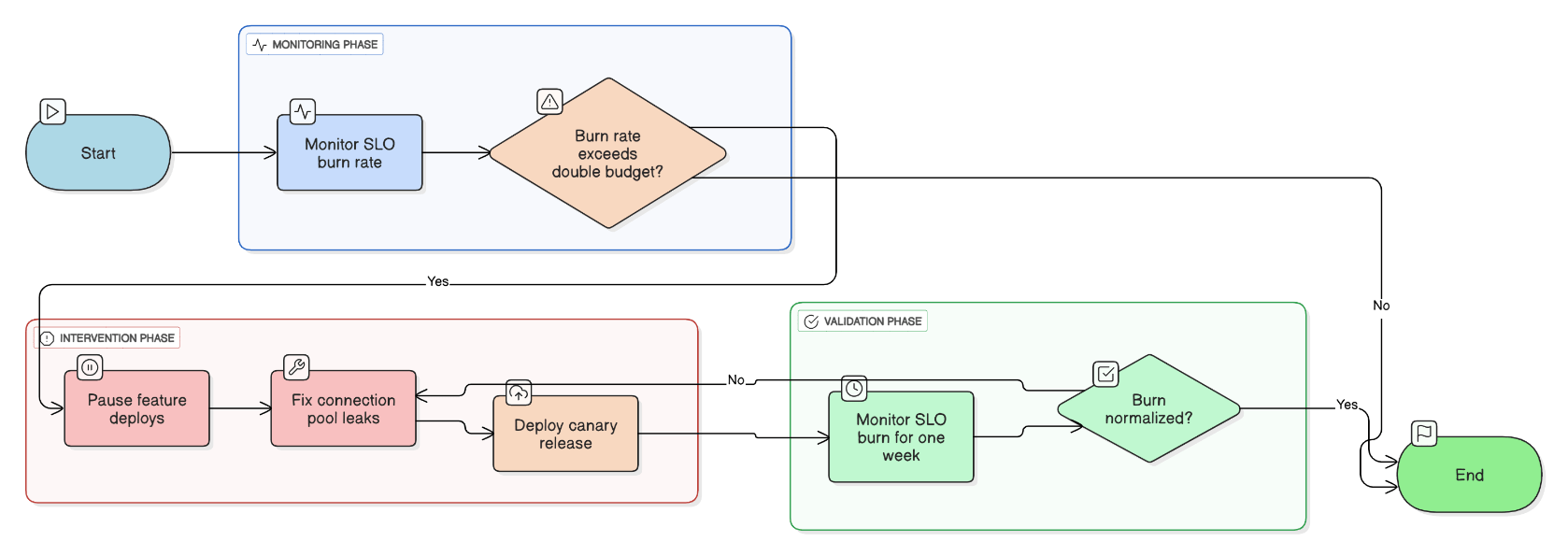
1000
What’s your approach to creating a culture of continuous learning and experimentation?
Schedule game‑days, blameless post‑mortems, hack weeks, allocate training budget, and celebrate lessons learned.
1100
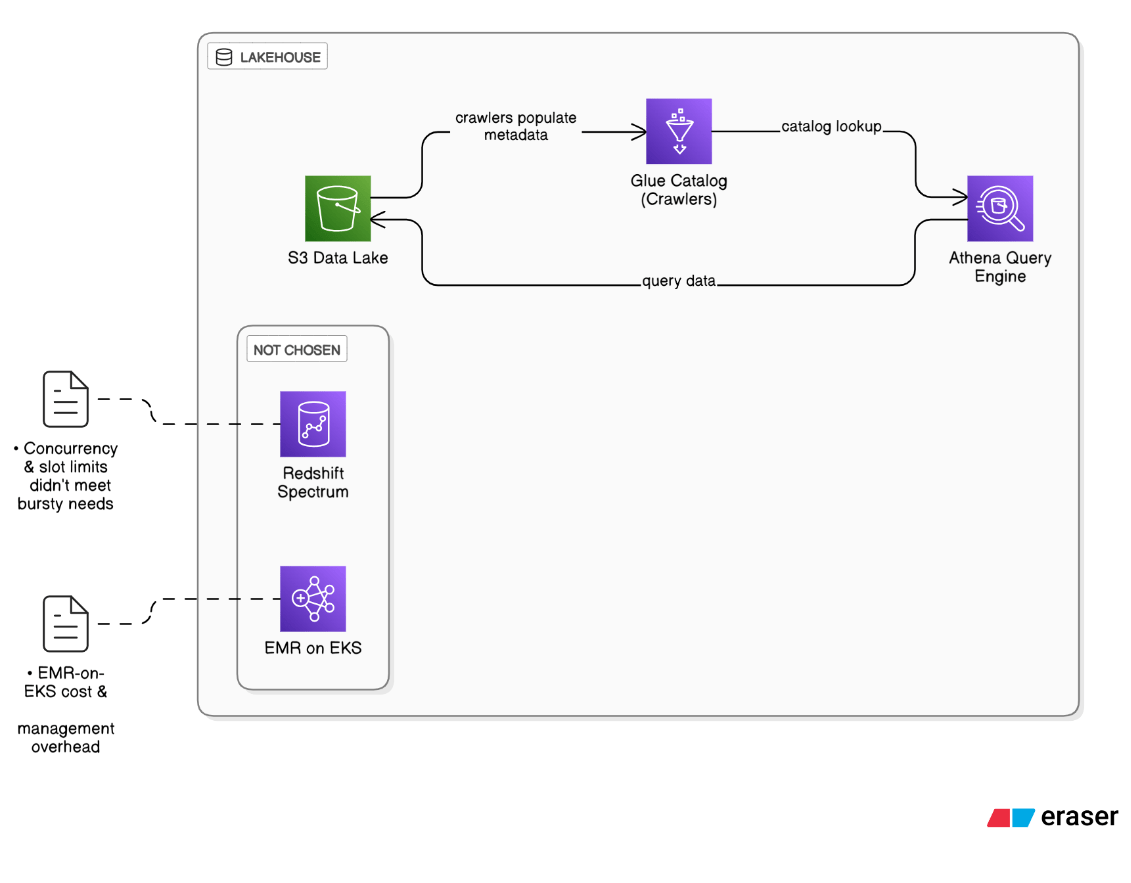
Walk through the Lakehouse pattern you implemented with S3, Glue, and Athena. Why not Redshift Spectrum or EMR?
S3 provides cheap, immutable storage; Glue crawlers maintain the catalog; Athena pools worker fleets so we avoid cluster ops. Redshift Spectrum’s concurrency and per‑query slot limits didn’t meet bursty analyst workloads, and EMR carried EMR‑on‑EKS cost & management overhead.
1100
Detail how you codified CIS, NIST 800‑53, and ISO 27001 controls in Cloud Custodian and OPA. What design patterns avoided rule sprawl?
Organize controls by YAML metadata, parameterize region/account, reference shared filter libraries, and inject the same data set into OPA Rego. A control ID → policy map avoids duplication; unit tests verify each policy’s tag, severity, and remediation link.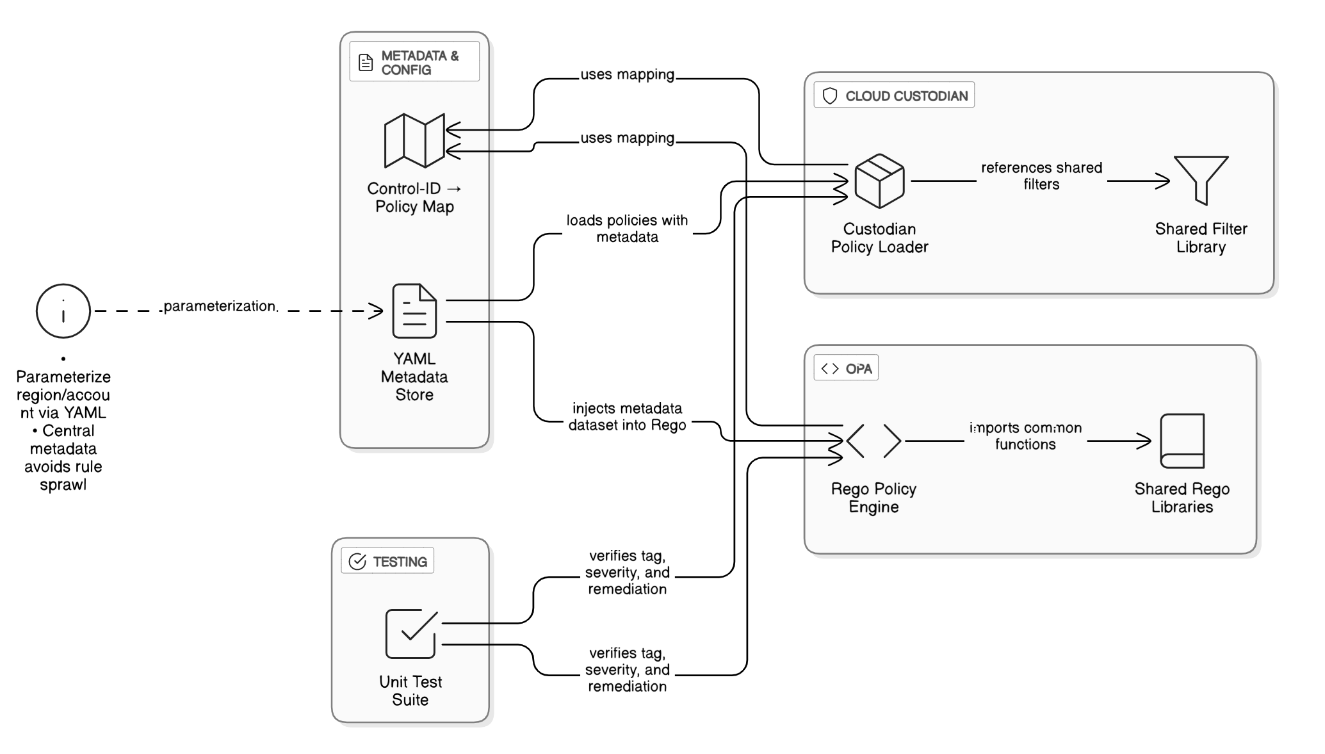
1100
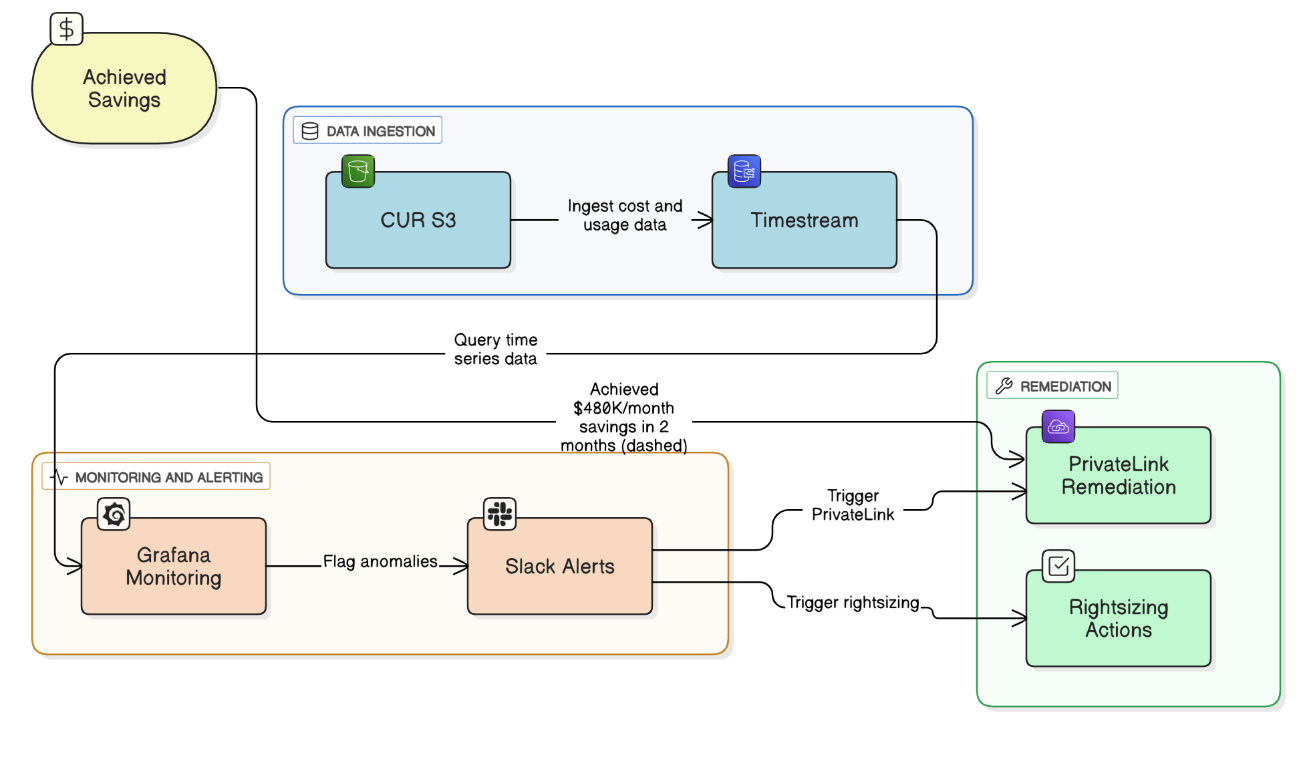
Explain how you used Cost Explorer, CUR, and Grafana to drive a \$480 k/month savings.
CUR ingested into Timestream, Grafana queried week‑over‑week deltas, Slack alerts flagged a 4× NAT egress spike and over‑provisioned Aurora; rightsizing and PrivateLink cut \$480 k in 2 months.
1100
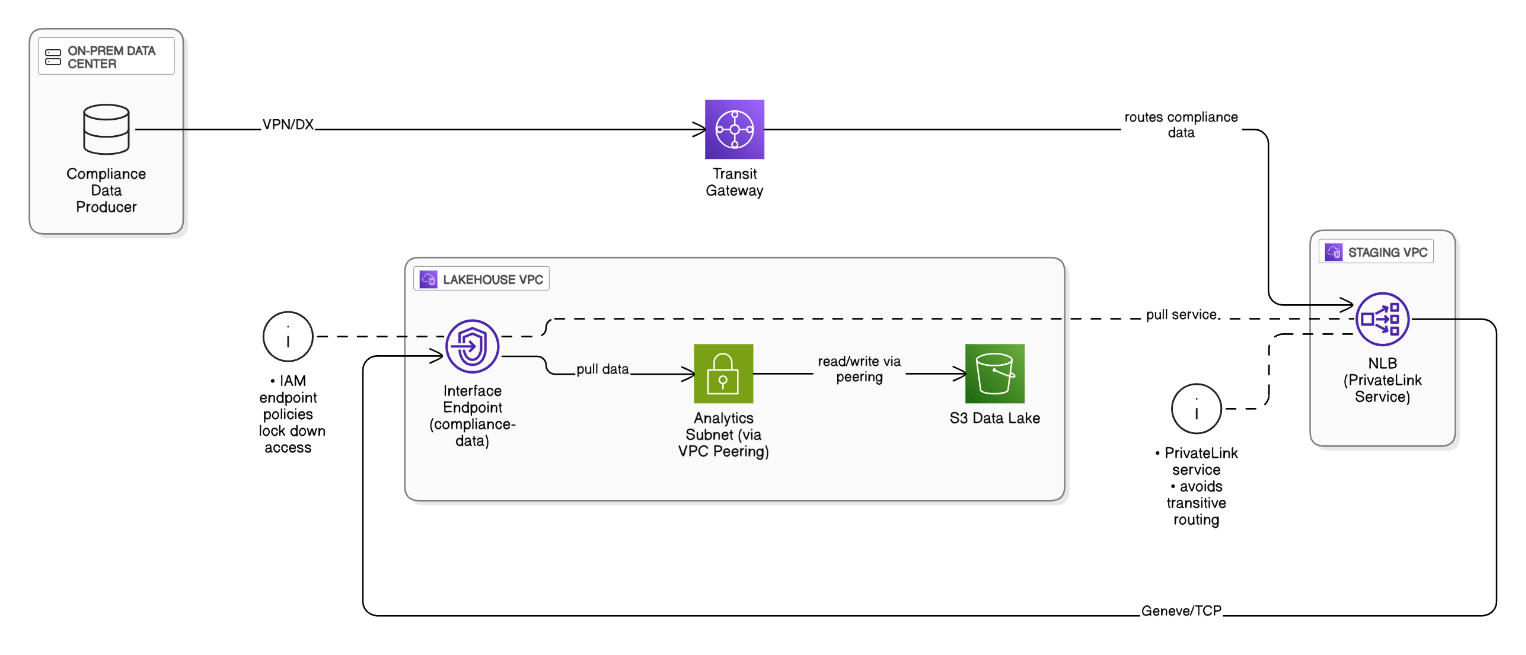
How did you design VPC peering and PrivateLink to pull compliance data securely from on‑prem into your AWS Lakehouse?
On‑prem data lands in a staging VPC via TGW; a producer NLB exposes PrivateLink service; consumer Lakehouse VPC uses interface endpoints, avoiding transitive routing; VPC Peering handles intra‑account analytics traffic, IAM endpoint policies lock down access.
1100
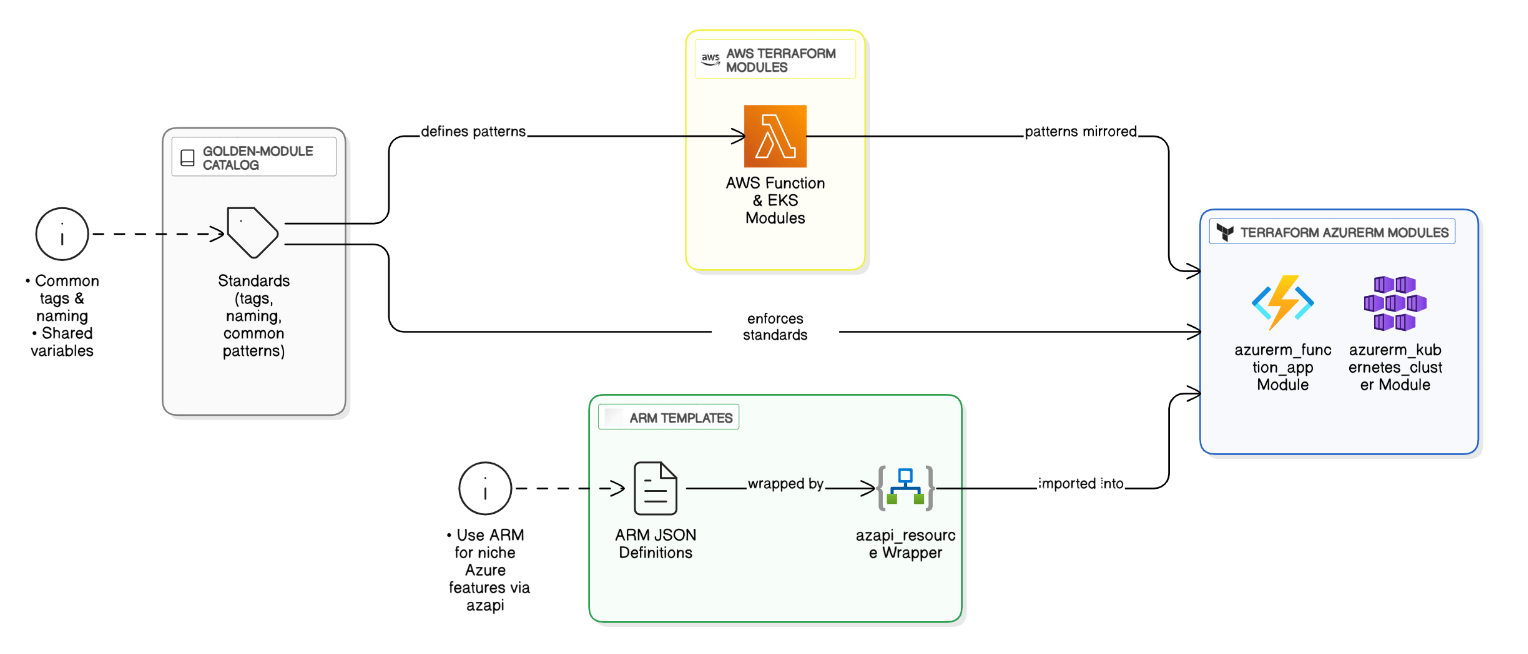
Compare Terraform modules versus ARM templates for deploying Azure Functions and AKS—how do you keep patterns consistent across clouds?
Use Terraform AzureRM provider modules mirroring AWS patterns (tags, naming), wrap ARM templates for niche Azure features via `azapi`. A golden‑module catalog enforces standards across both clouds.
1100
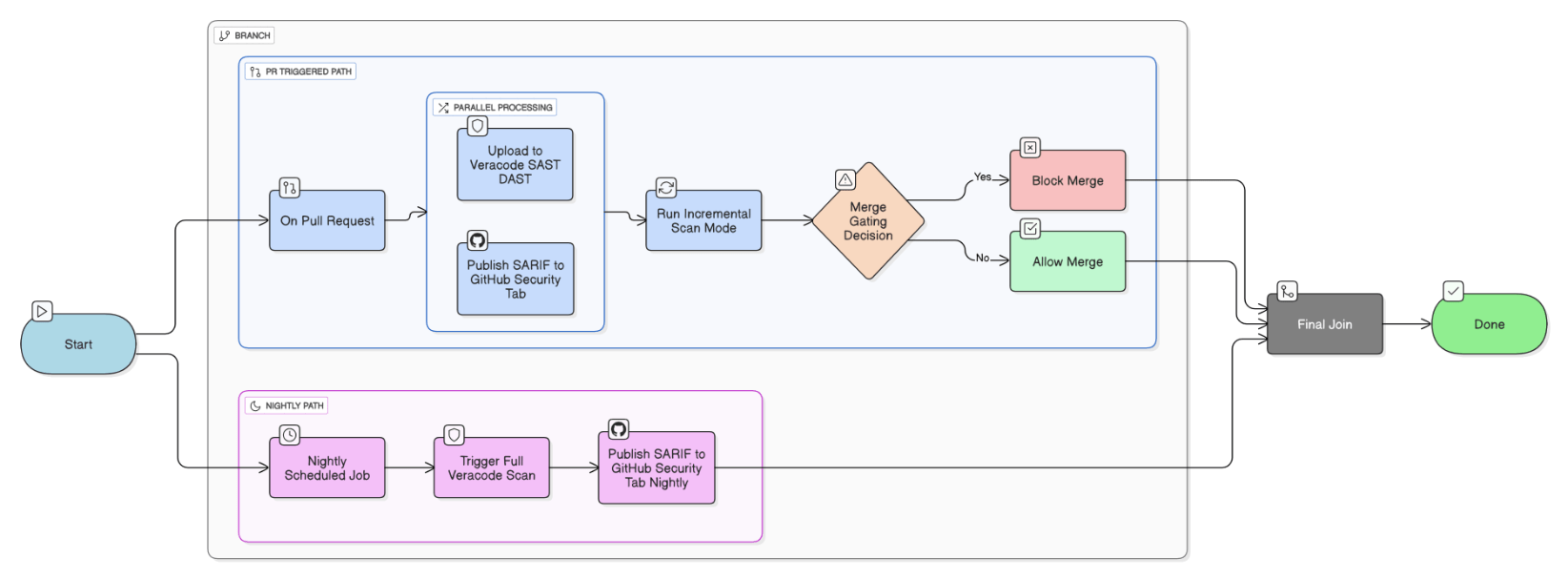
Detail how you wired Veracode SAST/DAST scans into Jenkins, GitHub Actions, and Azure Pipelines without slowing feedback loops.
Parallelize upload in CI workers, set incremental scan mode for PRs, full scans nightly, publish SARIF to GH security tab, and gate merges only on new critical findings.
1100
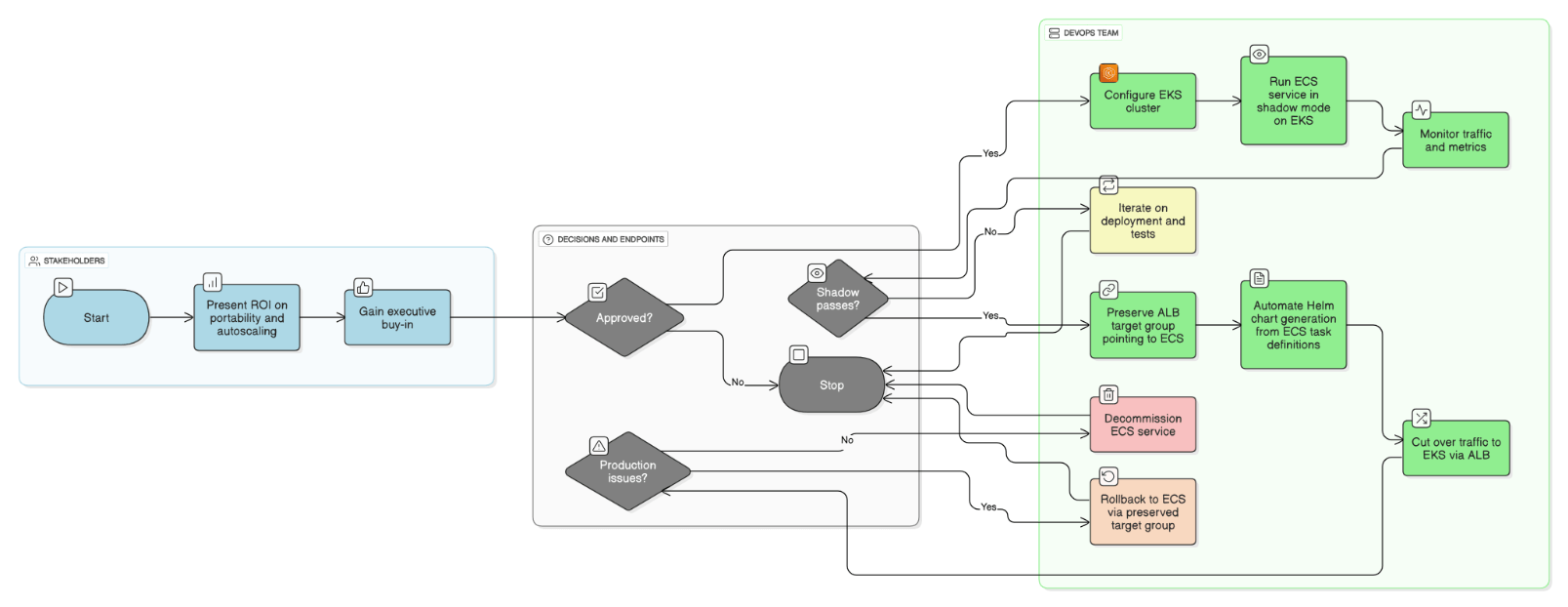
Outline the migration path you managed from ECS to Kubernetes—what won executive buy‑in and how did you mitigate rollback risk?
Presented ROI on portability and autoscaling, ran shadow traffic in EKS, preserved ALB target group for instant rollback to ECS, and automated Helm chart generation from task definitions.
1100
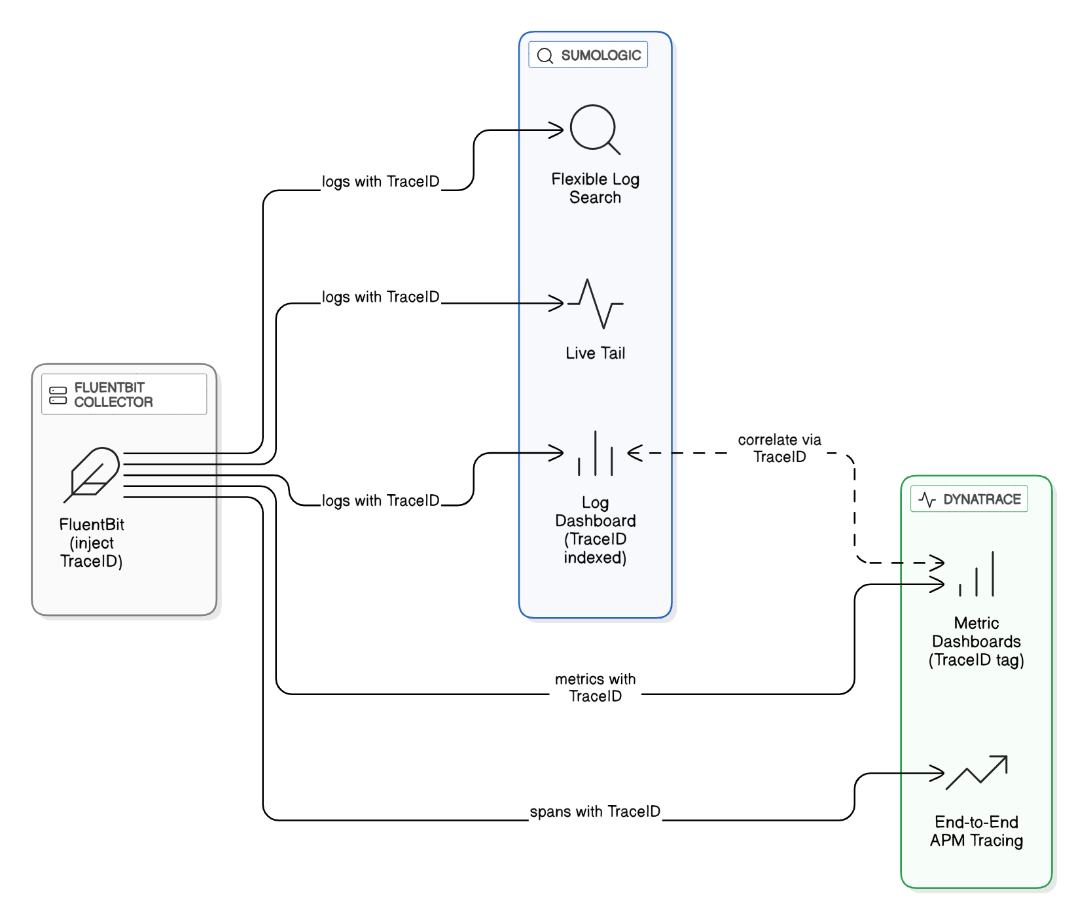
Compare Sumologic and Dynatrace dashboards you built: what gaps did each fill, and how did you correlate logs with metrics?
Sumologic handled flexible log search and live tail; Dynatrace provided end‑to‑end APM traces. Correlated via shared TraceID field injected by FluentBit.
1100
How did you design and test pilot‑light vs. warm‑standby DR strategies for critical AWS workloads?
Pilot‑light replicates minimal core DB/AMI, IaC scales infra on failover (RTO hours); warm‑standby runs downsized stack behind Route 53 failover (RTO minutes). Load‑tested quarterly.
1100
How did you organize role‑based training for privileged‑access users, and what metrics proved its effectiveness?
Deployed LMS modules, tracked completion, reduced privilege‑escalation incidents by 60 %, and surveyed NPS at 65.
1200
How would you extend that Lakehouse to ingest Azure and on‑prem compliance data while preserving lineage?
DataSync over VPN lands on‑prem CSV/JSON into an S3 raw bucket; Azure Data Factory streams to Event Hub, then Kinesis Firehose. Glue ETL harmonizes schemas, applies Lake Formation tags, and stores provenance in the Glue Data Catalog.
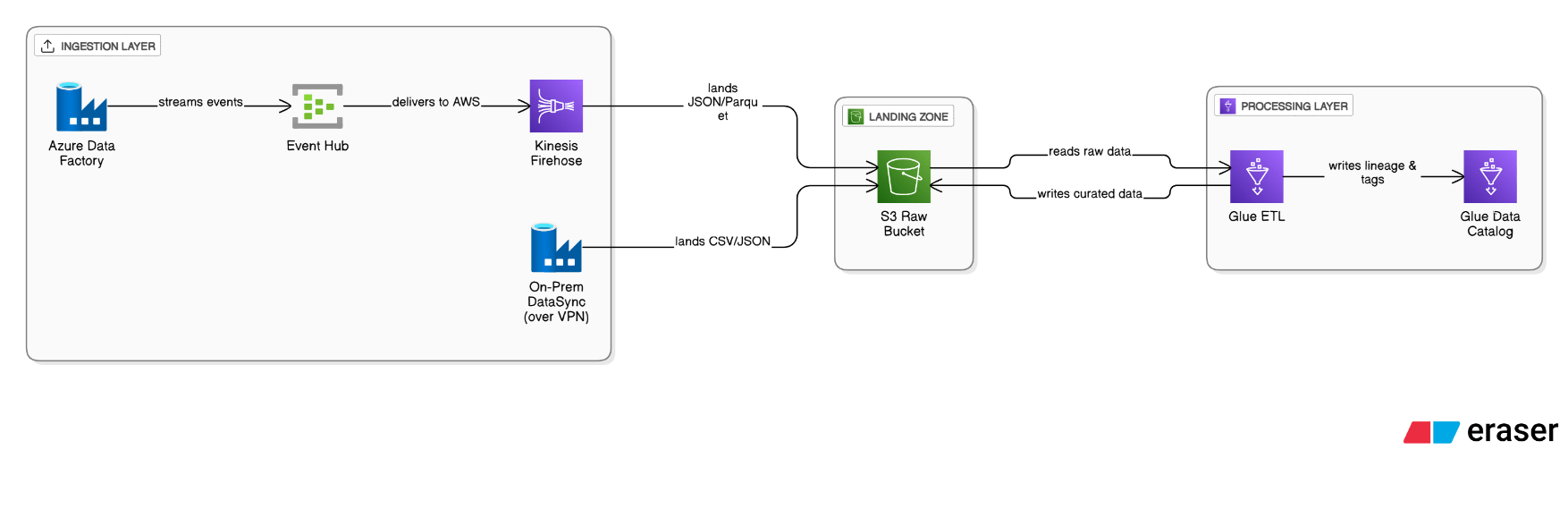
1200
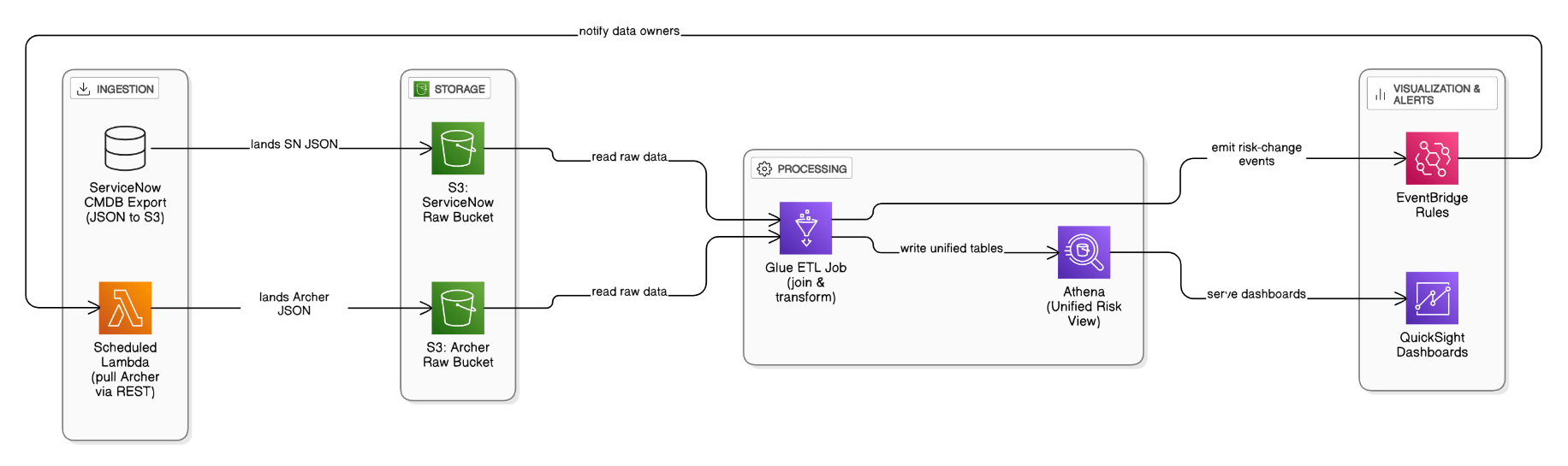
How did you integrate Archer TPRM findings and ServiceNow risk data into your governance pipeline?
A scheduled Lambda pulls Archer scores via REST, lands JSON into S3, Glue ETL joins with ServiceNow CMDB exports, Athena exposes a unified risk view, and QuickSight dashboards visualize trends while EventBridge notifies owners.
1200
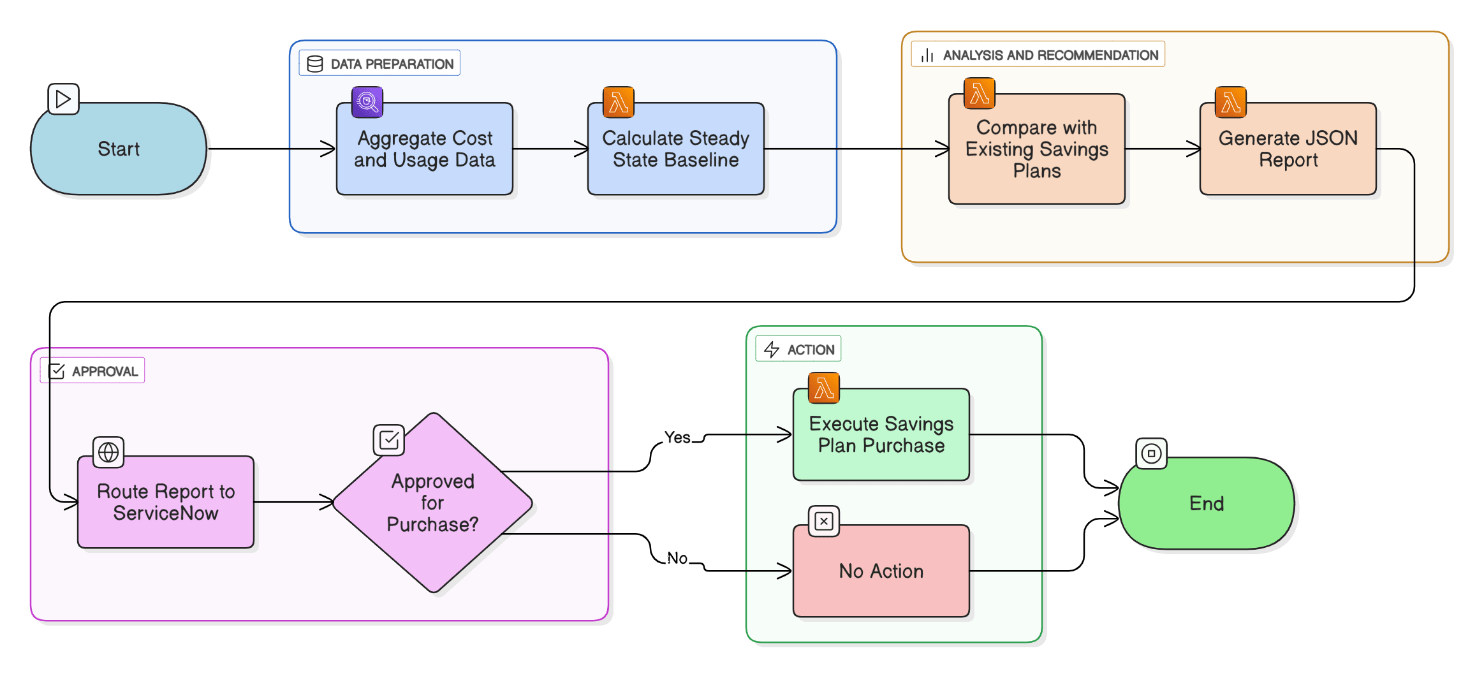
Describe your workflow for recommending Savings Plan purchases based on 30‑, 60‑, and 90‑day spend trends.
Athena aggregates CUR across periods, Lambda calculates steady‑state baseline, compares against existing SPs with Pricing API, generates JSON report, routed to ServiceNow for approval and one‑click purchase via Boto3.
1200
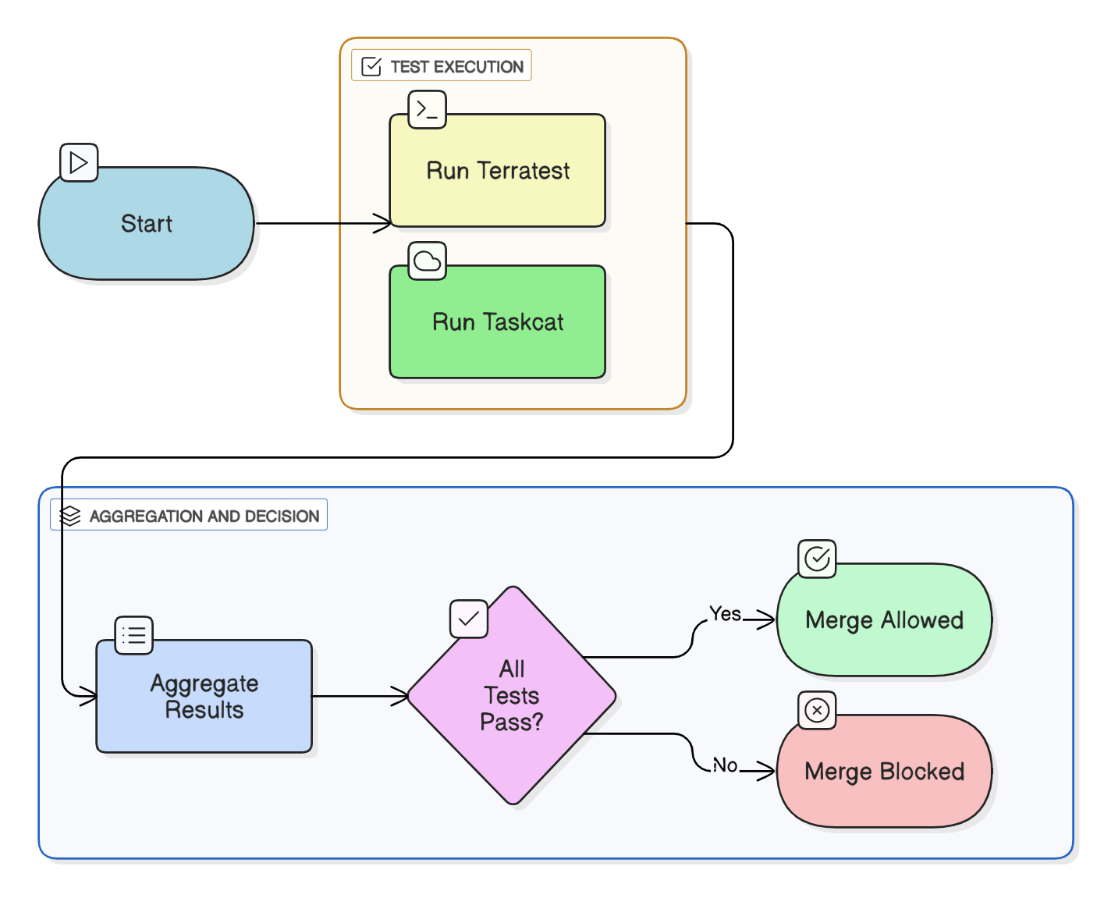
Describe how you implemented automated compliance unit tests for Terraform/CloudFormation before merge.
Terratest spins LocalStack mocks, asserts bucket encryption and logging; Taskcat validates CloudFormation in a sandbox account; both run in CI, blocking merge on failure.
1200
Describe the multi‑cloud deployment strategy you used to push artifacts to EKS, AKS, and on‑prem OpenShift from a single pipeline.
Build once, push image to ECR and replicate to ACR; Spinnaker triggers Argo CD on EKS, Flux on AKS, and OpenShift Git Ops; manifest versions stored in Git tags.
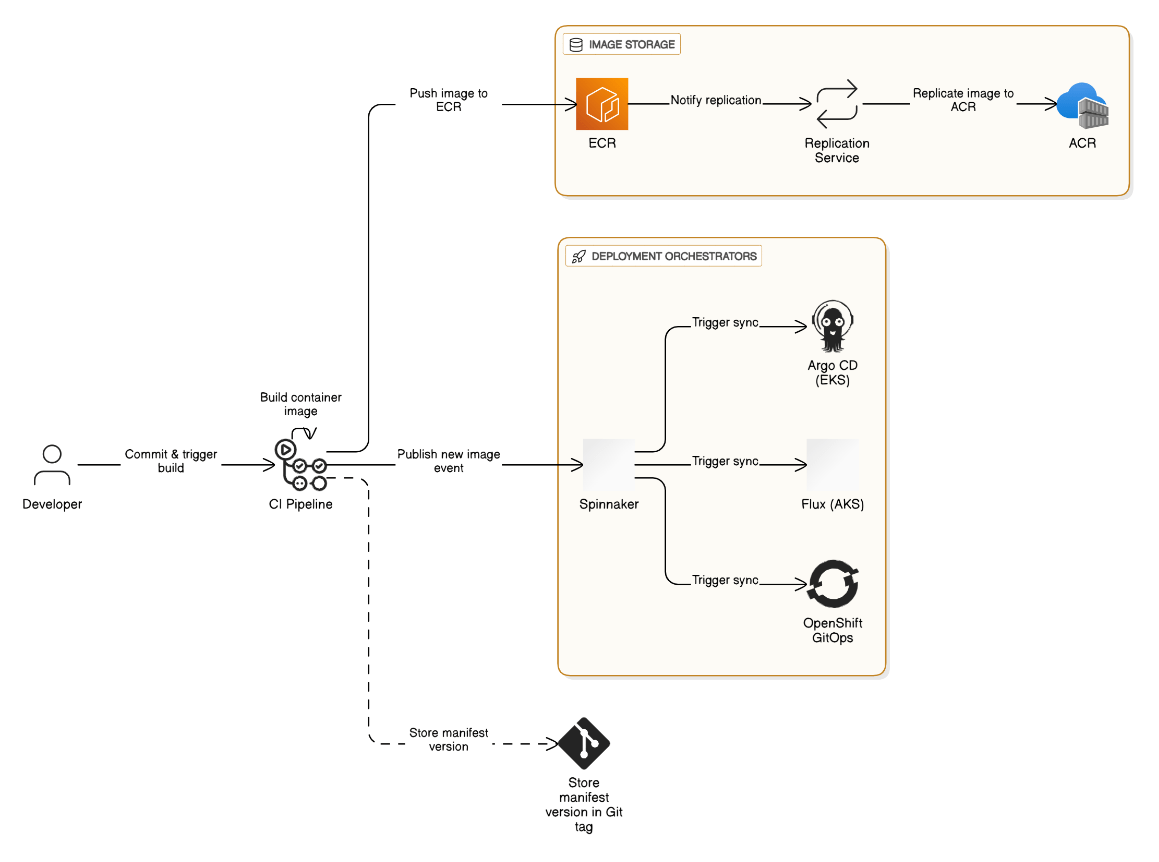
1200
Compare RBAC and Network Policies in OpenShift vs. vanilla Kubernetes; how did you enforce them across dev, stage, and prod?
OpenShift’s SCCs add stricter defaults; we created custom SCC, aligned RBAC roles, used OPA templates, and GitOps promotion to replicate across environments.
1200
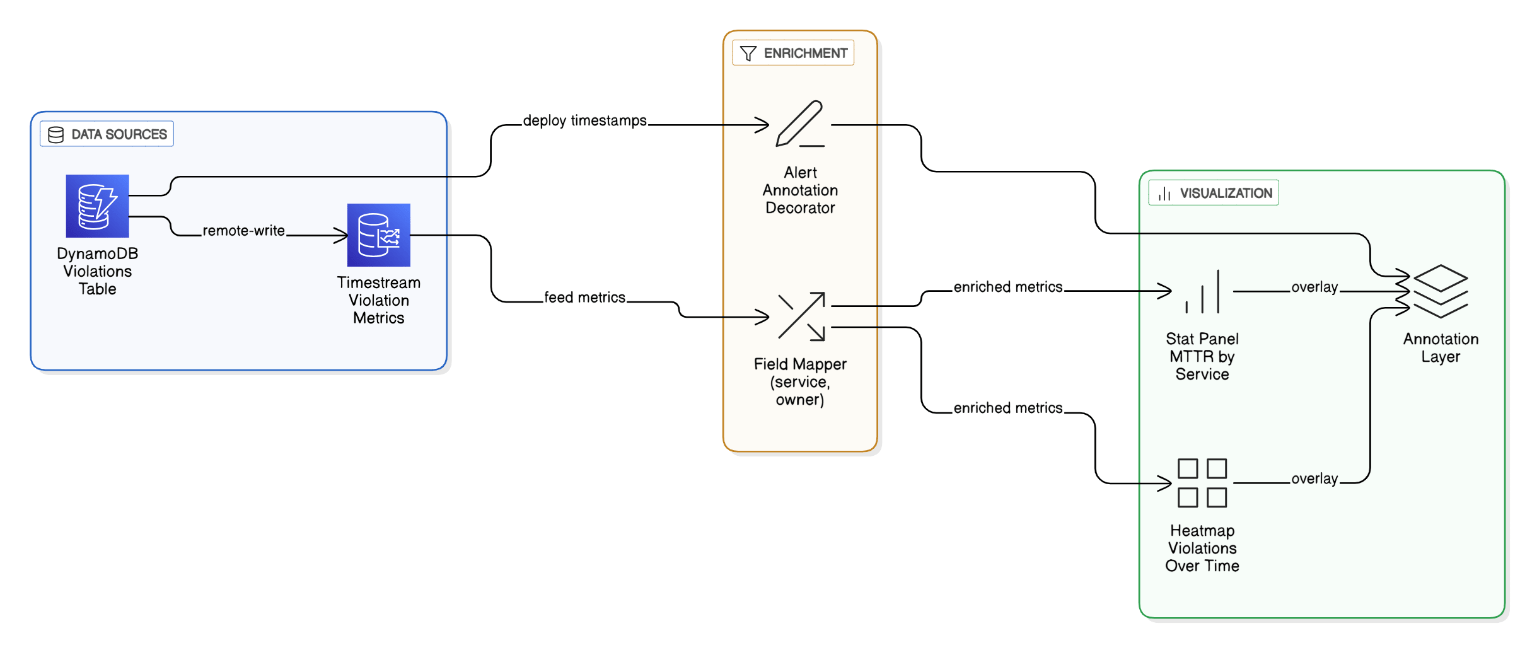
Describe the Grafana board that surfaces policy‑violation MTTR—how did you source, enrich, and visualize the data?
Data pulled from DynamoDB violations table via Timestream, field‑mapped to service/owner, visualized with Stat panels and heatmaps; annotations mark remediation deploys.
1200
Explain your experience tuning Veritas/Red Hat clustering in on‑prem hybrids—how would you replicate that reliability posture in Kubernetes?
Replaced shared storage fencing with Kubernetes PodDisruptionBudgets, anti‑affinity across AZs, multi‑AZ nodegroups, and NLB static IPs as virtual IP analog.
1200
Describe the stakeholder communication plan that won VP‑level sponsorship for your governance messaging capability.
Two‑slide exec summary tying compliance MTTR to regulatory fines, defined OKRs, set bi‑weekly steering meetings, and delivered early MVP demos.
1300
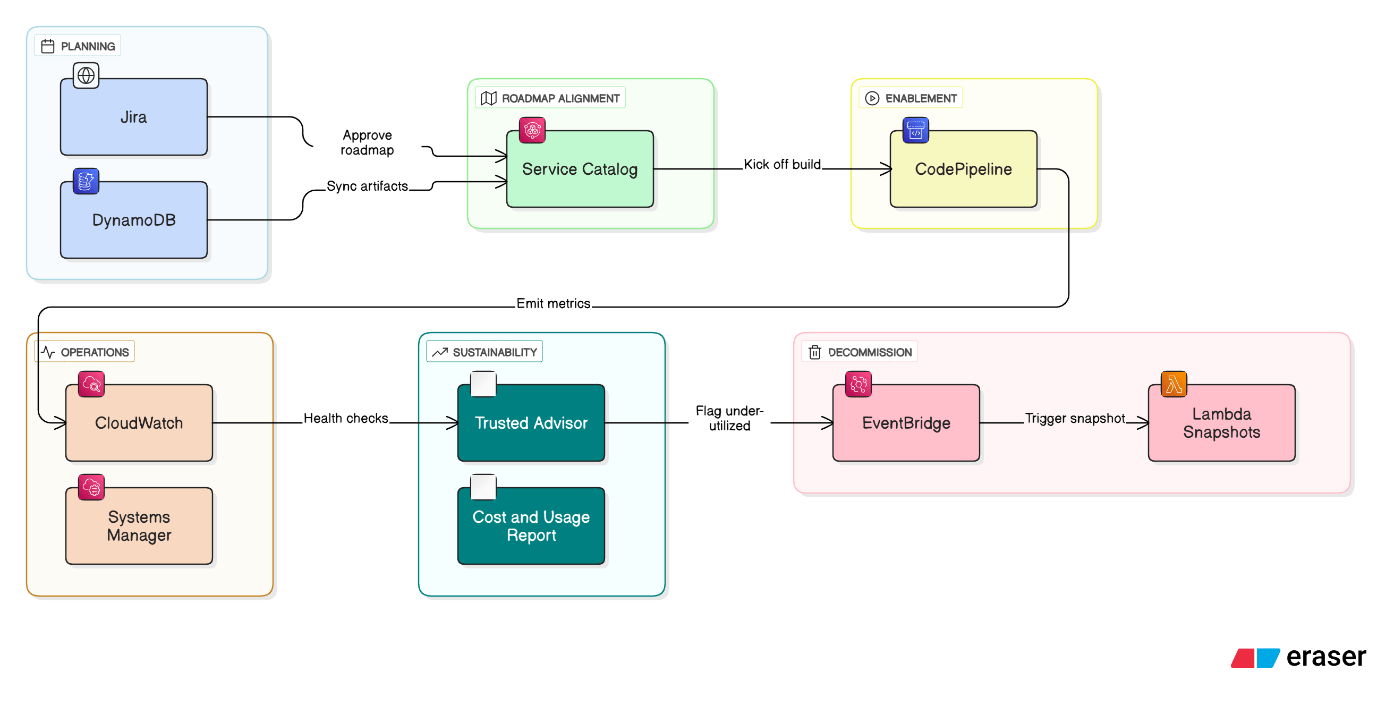
Describe how you mapped the six Technology Lifecycle Management (TLM) phases onto AWS services and pipelines.
Planning artifacts live in Jira/DynamoDB; roadmap alignment tracked via Service Catalog; enablement delivered by CodePipeline; operations monitored with CloudWatch and Systems Manager; sustainability measured by Trusted Advisor + CUR; decommission tasks scheduled via EventBridge + Lambda snapshots.
1300
Describe the end‑to‑end flow of a policy violation—from CloudTrail event to automated SNS notification and ServiceNow ticket closure.
CloudTrail logs to S3 → EventBridge pattern matches non‑compliant action → Step Function calls Custodian auto‑tag → Lambda remediates, then hits ServiceNow REST to open/close incident; SNS + Slack broadcast updates, and closure metrics feed Grafana.
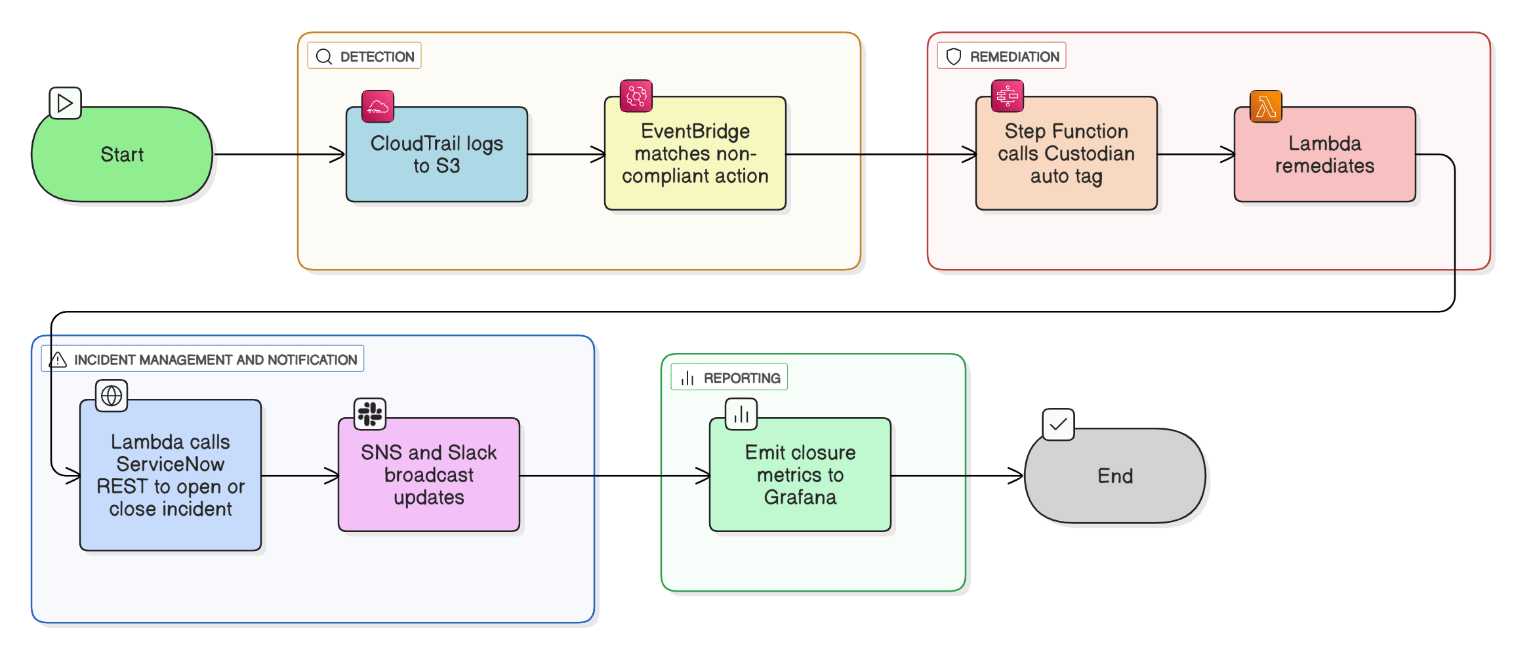
1300
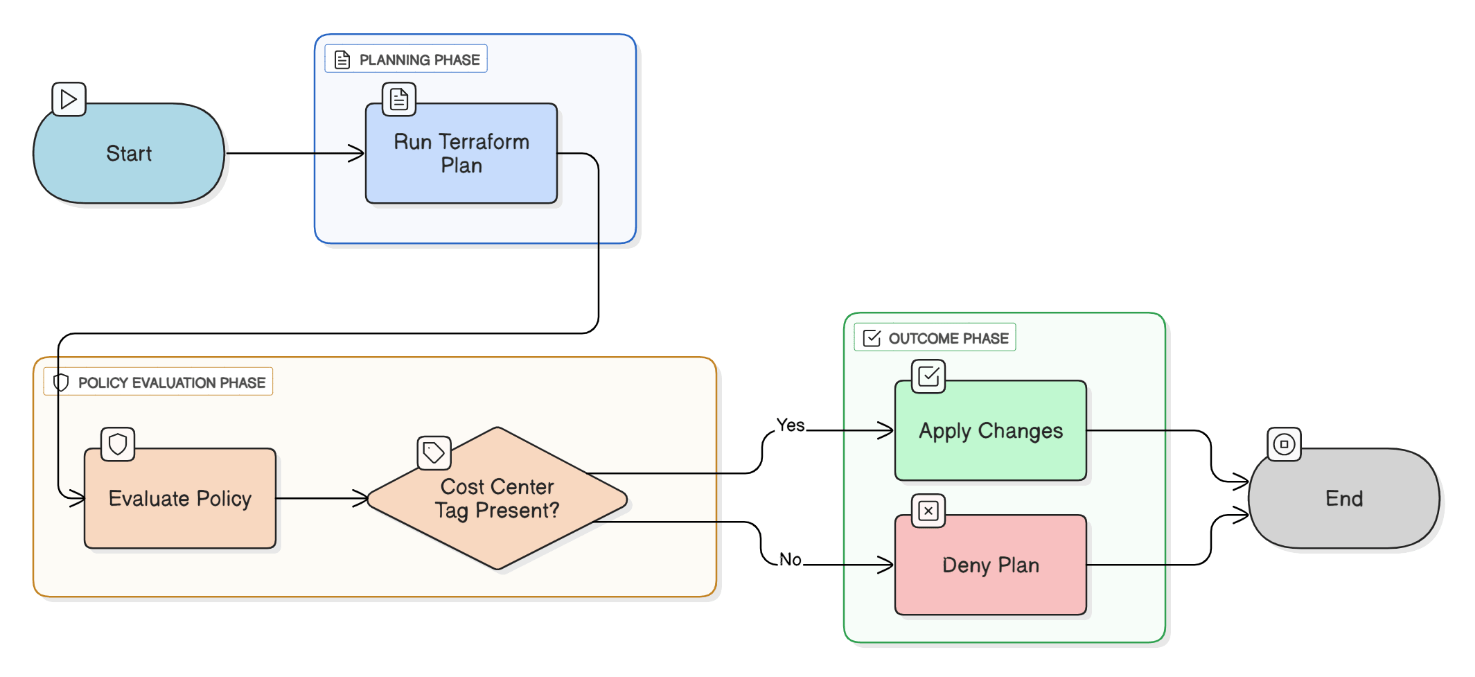
How would you implement FinOps guardrails in Terraform to block resources without required cost‑center tags?
Create TFC Sentinel policies (or OPA with Conftest) that `deny` any plan where `resource.tags["cost_center"] == ""`, enforce in the plan stage so applies cannot proceed.
1300
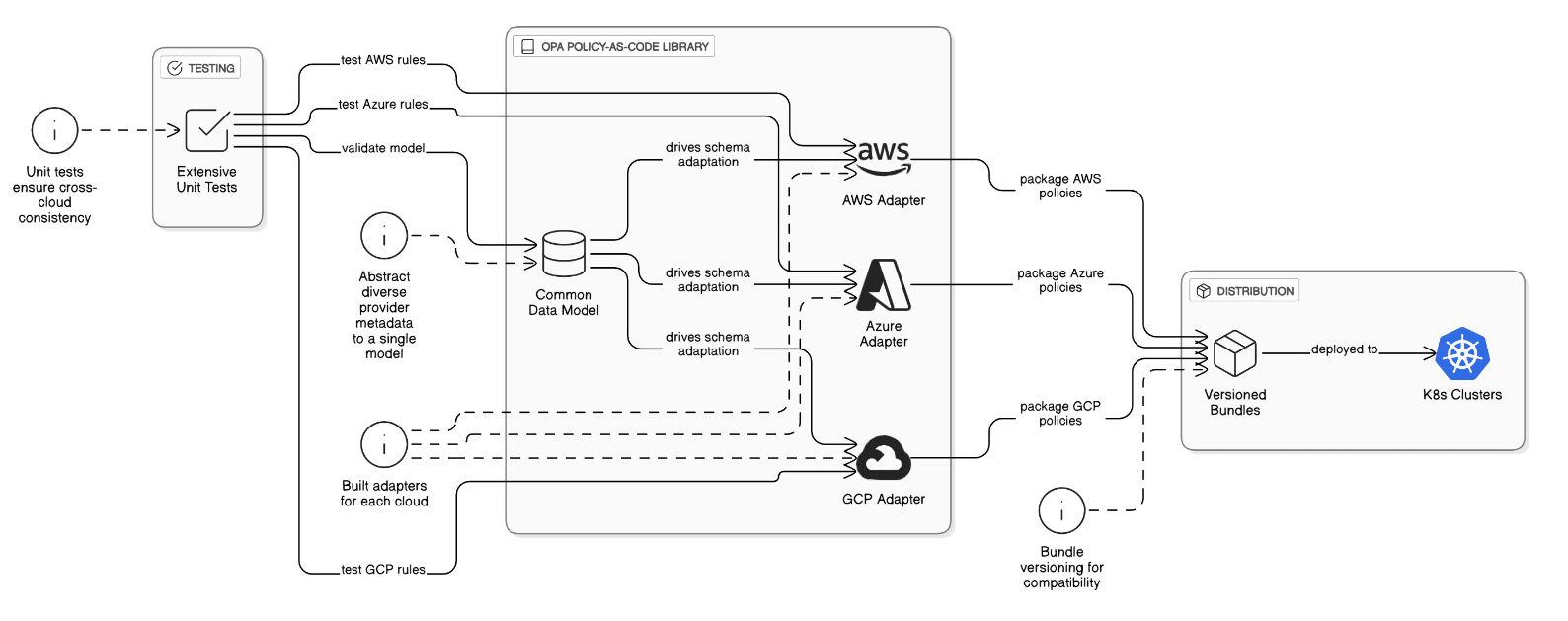
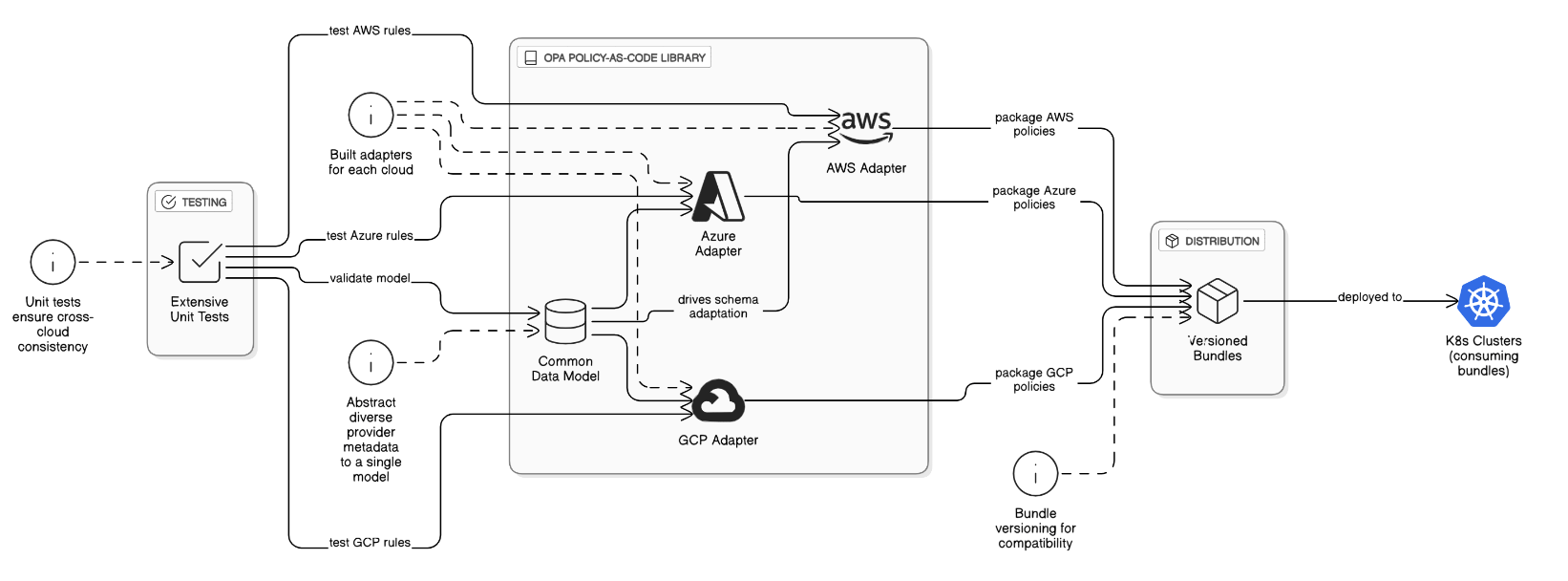
What challenges did you face maintaining a policy‑as‑code library in OPA that spans AWS, Azure, and GCP?
Cloud providers use different metadata schemas; abstracted to a common data model, built provider adapters, used extensive unit tests, and versioned bundles so clusters consume compatible policies.
1300
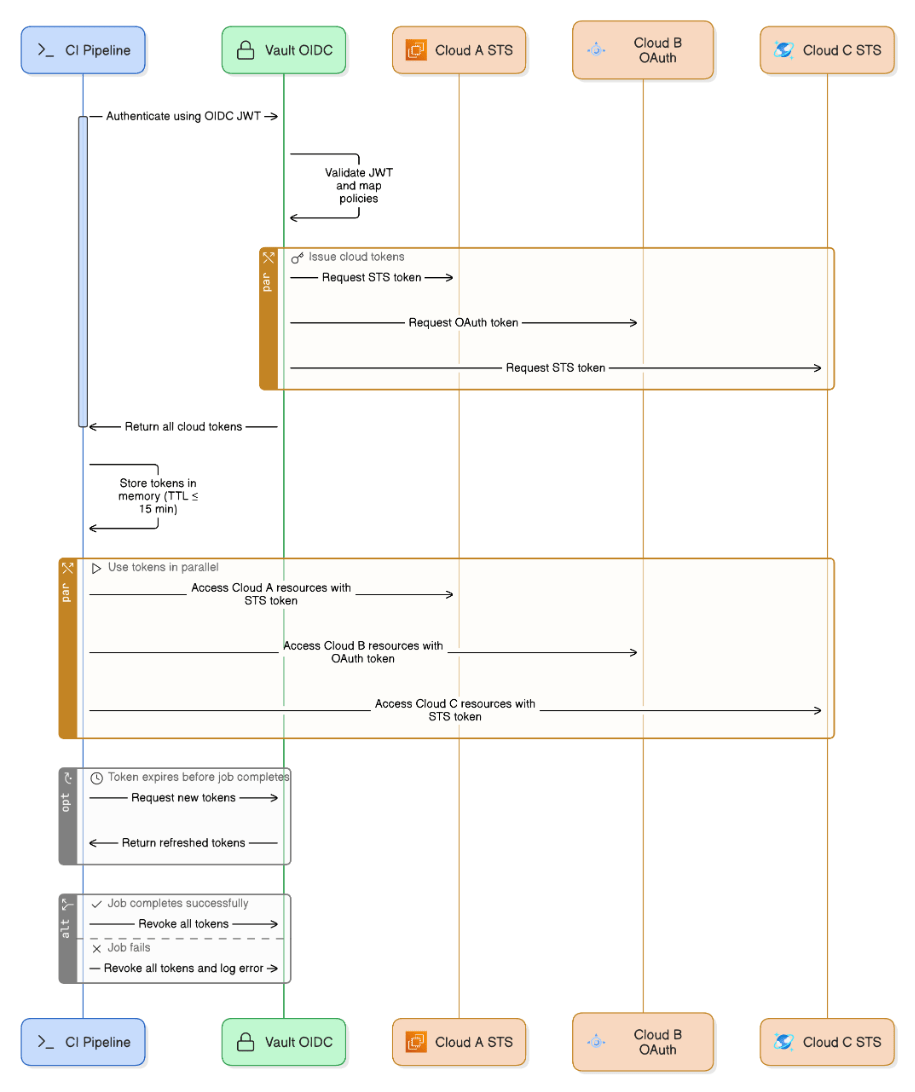
How do you manage secrets and short‑lived credentials across parallel pipeline runs in three different clouds?
Use Vault OIDC auth; CI job gets JWT, Vault issues cloud‑specific STS/OAuth tokens with TTL ≤15 min; tokens stored in memory only, revoked at job end.
1300
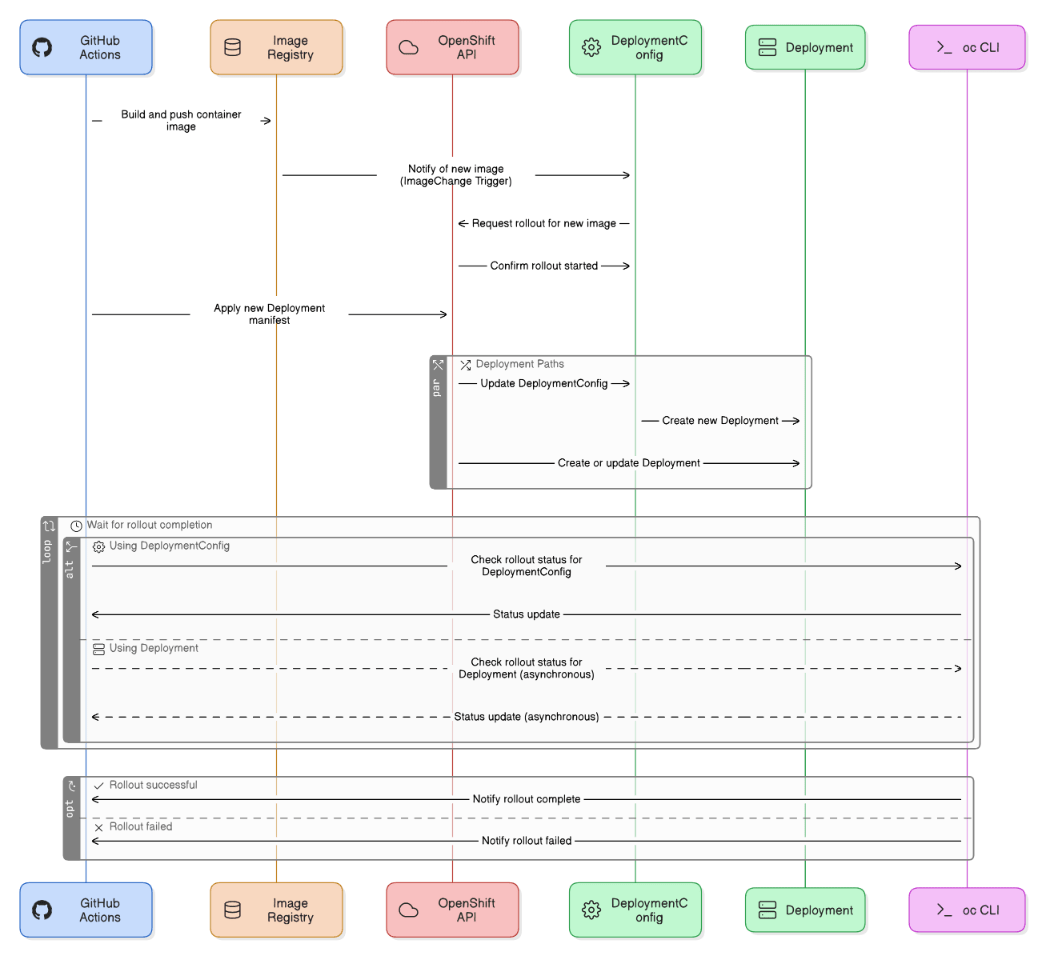
Explain how you optimized OpenShift DeploymentConfigs versus Deployments when integrating with GitHub Actions.
Used DeploymentConfig triggers for image‑change automation, switched stateless services to native Deployment for faster rollout, and leveraged `oc rollout status` in pipeline for gating.
1300
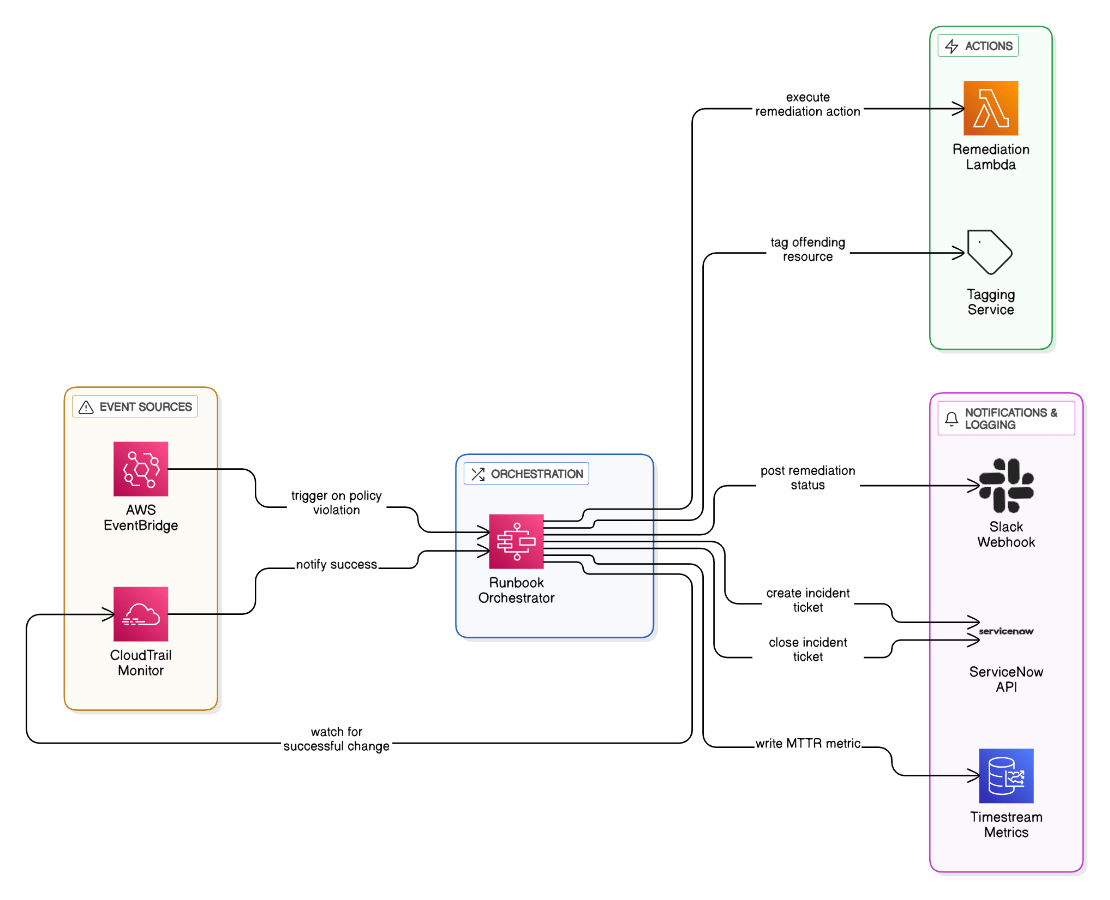
Walk through your automated runbook that shrinks MTTR for policy violations from 7 days to 8 hours.
EventBridge -> Step Functions: tag resource, remediate, post Slack, open ServiceNow, monitor CloudTrail for success, close ticket automatically; metrics captured in Timestream.
1300
How do you coach teams to interpret BPMN/swim‑lane diagrams so they can self‑service future process changes?
Created Confluence primers, ran hands‑on workshops, provided Camunda templates, and added checklist gates to PRs involving process changes.
1400
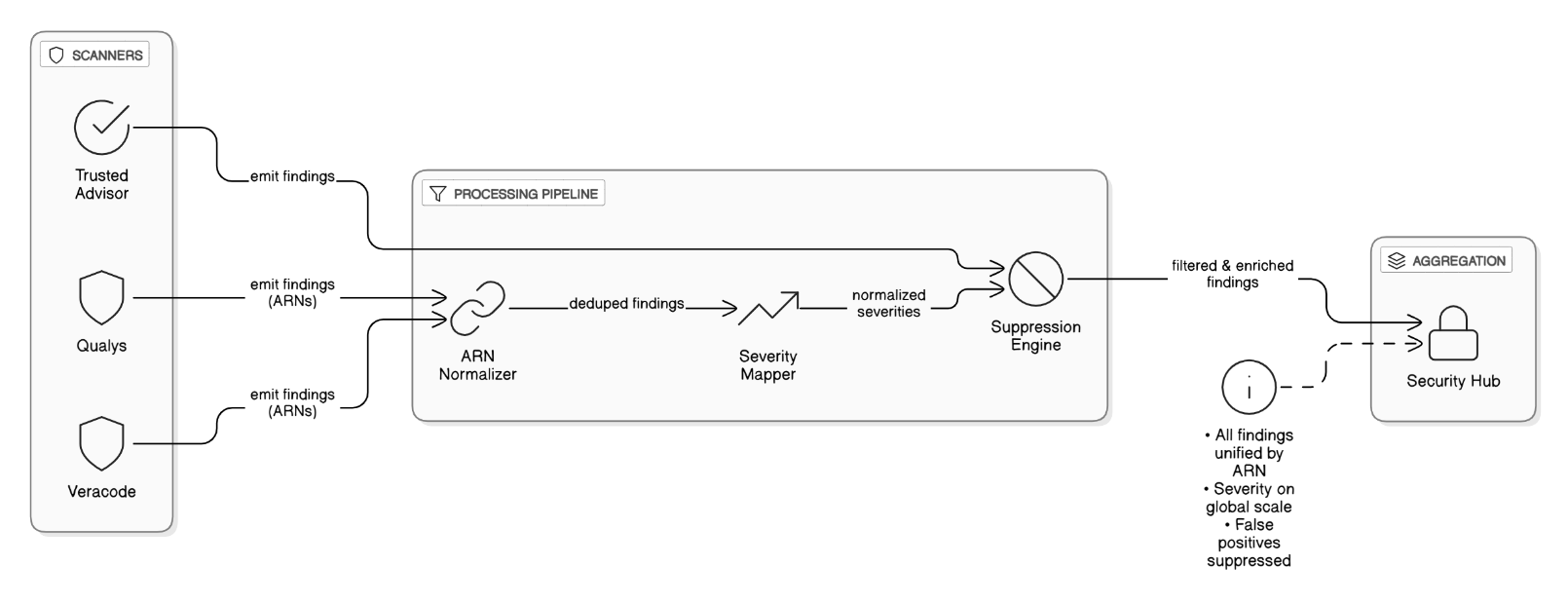
What lessons did you learn using Qualys, Veracode, and Trusted Advisor together to eliminate blind spots?
Normalize all findings into a unified ARN‑based schema to dedupe, map scanner severity to a global scale, suppress noisy false positives in Trusted Advisor, and feed everything into Security Hub for a single pane of glass.