Árboles de Decisión y Bosques Aleatorios
K-Vecinos Cercanos y Redes Neuronales
Regresión Lineal y Logística
Evaluación de Modelos
Optimización de Modelos
Actúa la Película
100
¿Qué significa el término "pureza" en un árbol de decisión?
Indica qué tan separados están los datos que se quiere clasificar.
100
En palabras simples, ¿cómo "aprende" una red neuronal?
"Aprende" equivocándose muchas veces, haciendo pequeñas correcciones en cada repetición.
100
¿Para qué se usa una regresión lineal y para qué una regresión logística?
La regresión lineal predice (calcula) números, mientras que la logística clasifica.
100
¿Qué significa evaluar un algoritmo de ML o IA?
Significa calificar los errores y aciertos que cometería en una muestra de datos.
100
¿Qué significa correlación?
Es un número que indica la relación entre dos variables.
100
Comedia
Son como niños
200
¿Cómo funciona un árbol de decisión?
Va separando un grupo de datos en ramas, donde cada rama es cada vez más "pura", es decir, va separando los datos en sus diferentes clases.
200
Empleando el algoritmo de 3-Vecinos Cercanos, indica de qué colores tendrían que pintarse los círculos blancos.
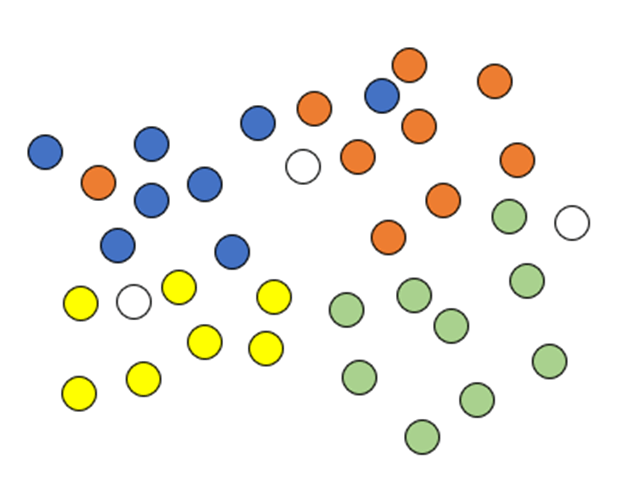
De izquierda a derecha: amarillo, naranja, verde
200
En una regresión lineal, ¿qué significa el valor de la intercepción y?
Es la constante de la "humildad". Es como un valor promedio de todos los datos que es difícil considerar.
200
Explica por qué es importante el tipo de error cuando se evalúa un modelo de ML o IA.
Porque algunos errores son más importantes que otros dependiendo el problema.
200
¿Qué significa optimizar los hiperparámetros de un modelo?
Buscar los valores que dan la máxima precisión (los mejores resultados).
200
Superhéroes
Spider-Man Home Coming
300
¿Cuál es la diferencia entre un árbol de decisión y un bosque aletaorio?
Un bosque aleatorio está conformado de múltiples árboles de decisión.
300
¿Cómo funciona el método de "Vecinos Cercanos" en un problema de clasificación?
El algoritmo revisa los "vecinos" que matemáticamente son más cercanos (parecidos) a lo que se quiere predecir y se clasifica según estos vecinos.
"Dime con quién andas y te diré quién eres"
300
¿Por qué a la regresión logística también se le llama "sigmoide"?
Por la forma de "S" que forma al graficarse
300
¿Cuáles son los dos tipos de errores y los dos tipos de aciertos que puede haber en un algoritmo de decisión binaria (dos clases)?
Aciertos: Verdadero Positivo y Verdadero Negativo
Errores: Falso Positivo y Falso Negativo
300
¿Cómo puedo utilizar la correlación para hacer un "filtro" de variables?
Se puede calcular la correlación entre cada variable predictora y la objetivo para ahcer un ranking y quedarnos con las más importantes.
300
Animada
Kung Fu Panda
400
¿Cómo hace un bosque aleatorio para tomar la decisión final en un problema de clasificación?
Toma los resultados de cada árbol que lo conforma y mediante una "votación" da como reusltado el más votado.
400
¿Cuáles son los tres tipos de capas que hay en una red neuronal MLP?
Entrada, Ocultas, Salida
400
En comparación con otros algoritmos de clasificación, menciona una desventaja de la regresión logística:
Sólo puede hacer clasificaciones binarias (dos grupos)
400
Da un ejemplo donde un falso positivo sea más importante que un falso negativo.
-
400
¿Cómo funciona el método de RFE (eliminación recursiva de variables) cuando buscamos obtener la selección óptima de variables?
Consiste en empezar con todas las variables disponibles y eliminar la menos importante (una por una) hasta obtener la máxima precisión.
400
Animada
Mi Villano Favorito
500
¿Cuál es la ventaja de un Bosque Aleatorio sobre un Árbol de Decisión?
Los árboles pueden sesgarse, los bosques podrían tener árboles sesgados pero en conjunto ese sesgo se disipa.
500
¿Por qué se dice que una red neuronal es una caja negra?
Porque los cálculos que hace en cada una de sus neuronas son tan numerosos y complejos que son prácticamente imposibles de entender por una persona.
500
Una de las ventajas más grandes de las regresiones lineal y logística es su "interpretabilidad", especialmente por los valores de sus "coeficientes". Explica a qué se refiere esto:
Los valores de los coeficientes son fáciles de interpretar porque entre mayor sea un coeficiente, significa que mayor es la importancia de la variable asociada a él.
500
Da un ejemplo donde un falso negativo sea más importante que un falso positivo.
-
500
¿Cómo podemos resolver el problema de los datos "desbalanceados" (ej. tener muchos positivos y pocos negativos)?
Se pueden crear más datos (muestras artificiales) o quitar datos del conjunto que tiene exceso (submuestreo).
500
Acción/Fantasía
Piratas del Caribe