K-NN
Frequent Pattern Mining
Data Visulization and Interpretation
Partitioning Methods
Outlier Detection
100
According to the study guide’s description of distance-based outliers, why does a point with a large k-NN distance often indicate an outlier?
Because it resides far from dense regions of the data, showing sparse local structure.
100
Apriori generates candidates using what principle?
Level-wise search and anti-monotonicity
100
What does this scatter plot suggest about the strength and direction of correlation, and what visual feature supports your conclusion?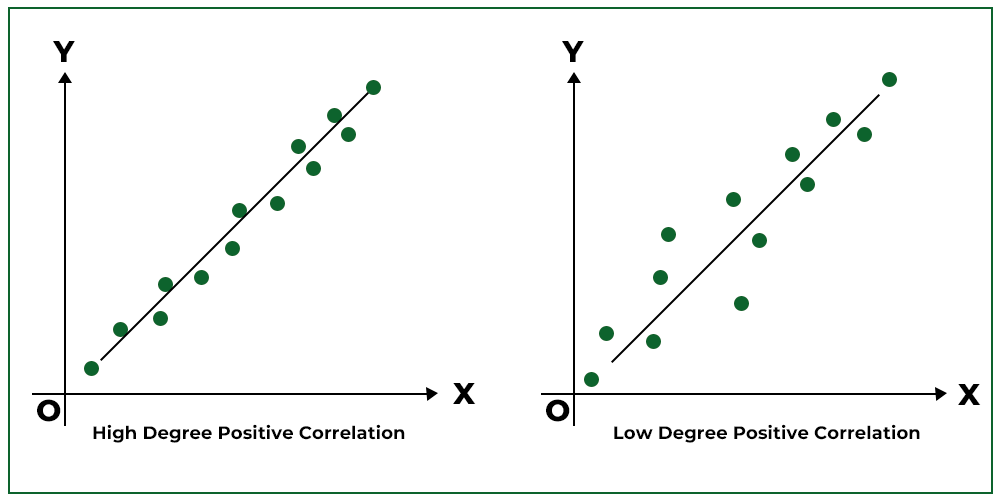
A moderate positive correlation; supported by points trending upward with visible but not tight alignment.
100
According to the study guide, what quantity does k-Means minimize?
Within-cluster sum of squared distances to the centroid.
100
What is an outlier, using the study guide’s definition?
A point that deviates significantly from the expected pattern or distribution.
200
How does increasing the value of k affect the sensitivity of k-NN outlier detection?
Larger k smooths local variation and makes outliers harder to detect because neighborhoods become broader.
200
A frequent itemset must meet which requirement?
Support ≥ minimum support
200
According to box-plot interpretation rules in the study guide, what does the longer upper whisker indicate about the distribution?

Right (positive) skew; the upper tail contains more dispersed values.
200
Why does k-Means perform poorly on datasets with clusters of different densities or non-spherical shapes?
It assumes convex, similarly shaped clusters based on Euclidean distance.
200
In DBSCAN, why is ε important for outlier detection?
It defines the neighborhood radius used to determine if a point has enough neighbors to be a core point.
300
What major challenge does k-NN face when detecting outliers in datasets with uneven density?
Points in naturally sparse regions may be incorrectly flagged as outliers even when they belong to legitimate low-density clusters.
300
Define closed itemset, and why is it valuable for analysis.
A closed itemset has no superset with the same support; it preserves all support information without redundancy.
300
How would the presence of this outlier affect interpretation of the overall correlation, based solely on study-guide concepts?

It weakens the perceived trend by pulling the correlation away from the main pattern.
300
How does the study guide define a closed itemset, and why is it valuable for analysis?
A closed itemset has no superset with the same support; it preserves all support information without redundancy.
300
Why might a border point be considered "non-noise" even if it does not satisfy the core condition?
Because it lies within the ε-neighborhood of a core point.
400
Why is k-NN sensitive to feature scaling when used for outlier detection?
Because distance calculations dominate the method; features with larger numeric ranges disproportionately affect distance.
400
What distinguishes a maximal frequent itemset from a merely closed itemset?
A maximal itemset has no frequent supersets; closed itemsets may still have frequent supersets but with different support
400
Using the study guide’s definitions of central tendency and dispersion, what can be concluded about the relationship between these two groups?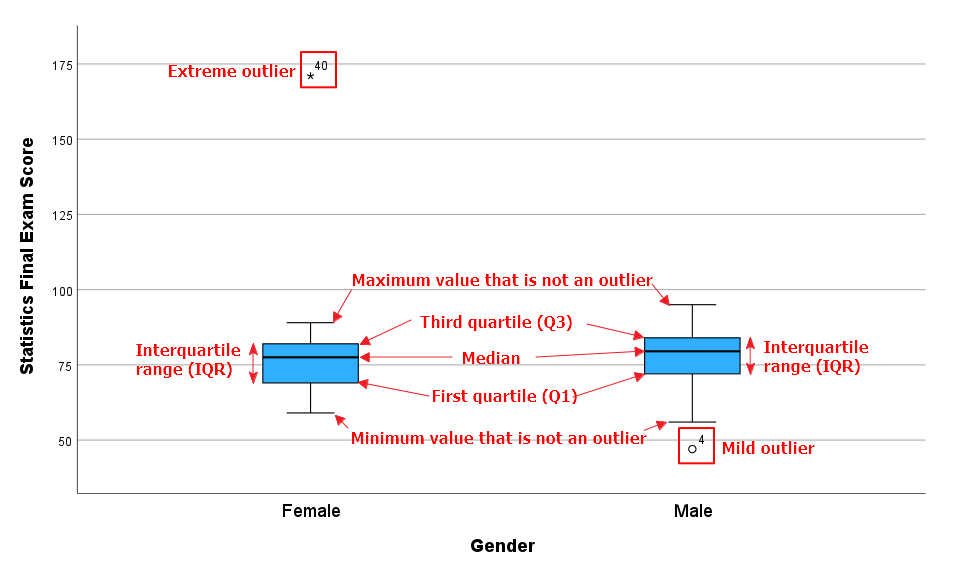
They differ in central tendency (different medians) but show similar variability (similar IQRs).
400
What distinguishes a maximal frequent itemset from a merely closed itemset?
A maximal itemset has no frequent supersets; closed itemsets may still have frequent supersets but with different support.
400
What outlier-detection challenge is highlighted by the study guide when using box-plots?
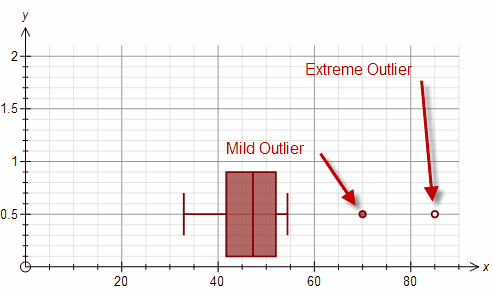

Outliers may appear in varying degrees, and box-plots do not reveal whether outliers arise from meaningful structure or noise.
500
What is a fundamental difference between DBSCAN and k-NN for outlier detection, based on the study guide?
DBSCAN uses density thresholds, while k-NN uses relative distances; thus DBSCAN can adapt to shape, while k-NN cannot distinguish natural sparse structure from anomalies.
500
Two itemsets have identical support, but one contains more items. What does this imply about possible closure or generator relationships?
The larger itemset may be closed; the smaller may be a generator with the same support but fewer items.
500
The study guide lists “cluster tendency” as a key evaluative concept. What does this scatter plot suggest about cluster tendency?

It demonstrates strong cluster tendency because the points naturally form two separable groups.
500
Two itemsets have identical support, but one contains more items. What does this imply about possible closure or generator relationships?
The larger itemset may be closed; the smaller may be a generator with the same support but fewer items.
500
Why does DBSCAN outperform distance-based methods in detecting outliers within datasets containing clusters of varying shapes?
Because it identifies outliers based on density, not global distance thresholds.