Bayes for Days
Its me, Mario!
Clustering I
Clustering II
PCA
100
_____ and _____ are the two major interpretations of probability
Frequentist and Bayesian
100
Where can an estimator exist in a pipeline?
As the last element
100
What is the only required hyperparameter of HDBSCAN?
min_samples
100
What should be the best choice of no. of k clusters based on the following results?
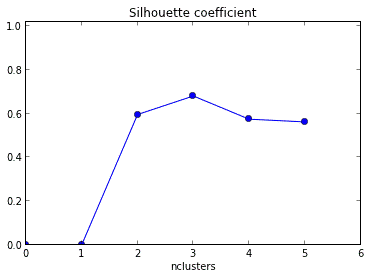
3
100
What is the angle of PC1?
45 degrees
200
These are the two distributions/probabilities of event named in Bayes' Rule.
Prior and posterior
200
The three methods available to a Pipeline
What are .fit(), .predict(), .score()?
200
What is the epsilon hyperparameter of DBSCAN do?
The searching distance (radius of the searching circle) when attempting to build a cluster
200
What is a reasonable choice for k?
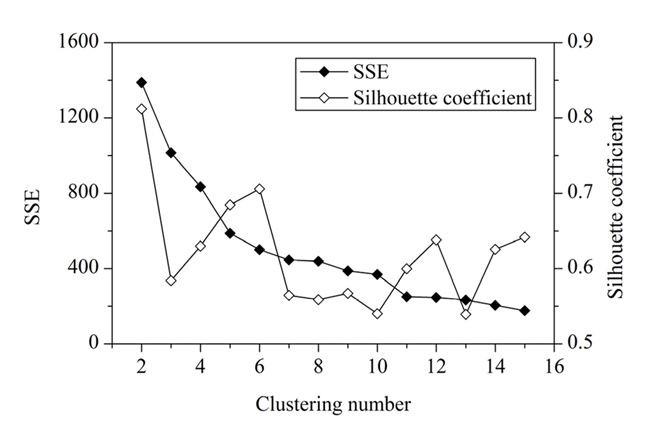
6
200
Which of the above graph shows better performance of PCA?
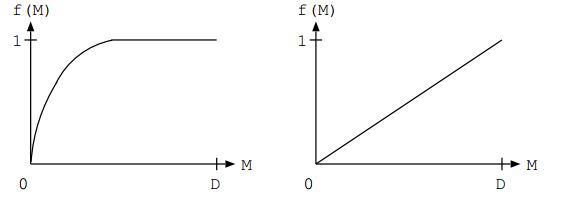
Left
300
the probability of getting a "Diamond 4" card given you know the card you get is a 4
1/4
300
The keyword to specify in GridSearchCV the various configurations to try
What is param_grid?
300
This linkage method measures the distance between two clusters is the minimum distance between the closest points between clusters?
Single Linkage
300
What is the difference between agglomerative hierarchical clustering and divisive hierarchical clustering?
- Agglomerative goes from the bottom-up, starting with single data points and merging them into groups.
- Divisive goes from the top down, starting with all the data points and dividing them.
300
What will happen when eigenvalues are roughly equal?
PCA will perform badly
400
the probability of a "heart 8" given the card is black
0
400
What is the difference between Pipeline and make_pipeline
make_pipeline assigns the step names for you
400
What does DBSCAN fully stand for?
Density-Based Spatial Clustering of Applications with Noise
400
What is optimal in terms of cohesion and separation?
Small cohesion (close to zero)
Large separation
400
What two assumptions does PCA make about the data to work properly?
- Linearity: The data does not hold nonlinear relationships.
- Large variances define importance: The dimensions are constructed to maximize remaining variance.
500
What is the denominator in the formula for the Bayes Theorem?
P(B) or the probability of the actual data
500
Given `pipe = Pipeline([('preprocessing', StandardScaler()), ('classifier', SVC())])` How to specify other models to try on GirdSearchCV in param_grid?
pipe = Pipeline([('preprocessing', StandardScaler()), ('classifier', SVC())])
grid = GridSearchCV(pipe, parameters, scoring = 'neg_mean_absolute_error')
500
Define border points using the terms hyperparameter min_samples and epsilon
Points still within the cluster that do not satisfy min_samples within epsilon
500
This linkage method that measures the distance between two clusters as the maximum distance between an observation in one cluster and an observation in the other cluster?
Complete Linkage
500
What should we always do before PCA?
Standardization