Bayes-Watch
Season 2
Season 2
What kind of Neural Network is most appropriate for image processing applications? Why?
Convolutional
What is an activation function?
In artificial neural networks, the activation function of a node defines the output of that node given an input or set of inputs. (Thought of as can be triggered as on or off depending on values)
Explain regularization and why it is important.
What is the difference between supervised and unsupervised learning?
Corgi or Bread?

Corgi
What is P( Red | Truck )?
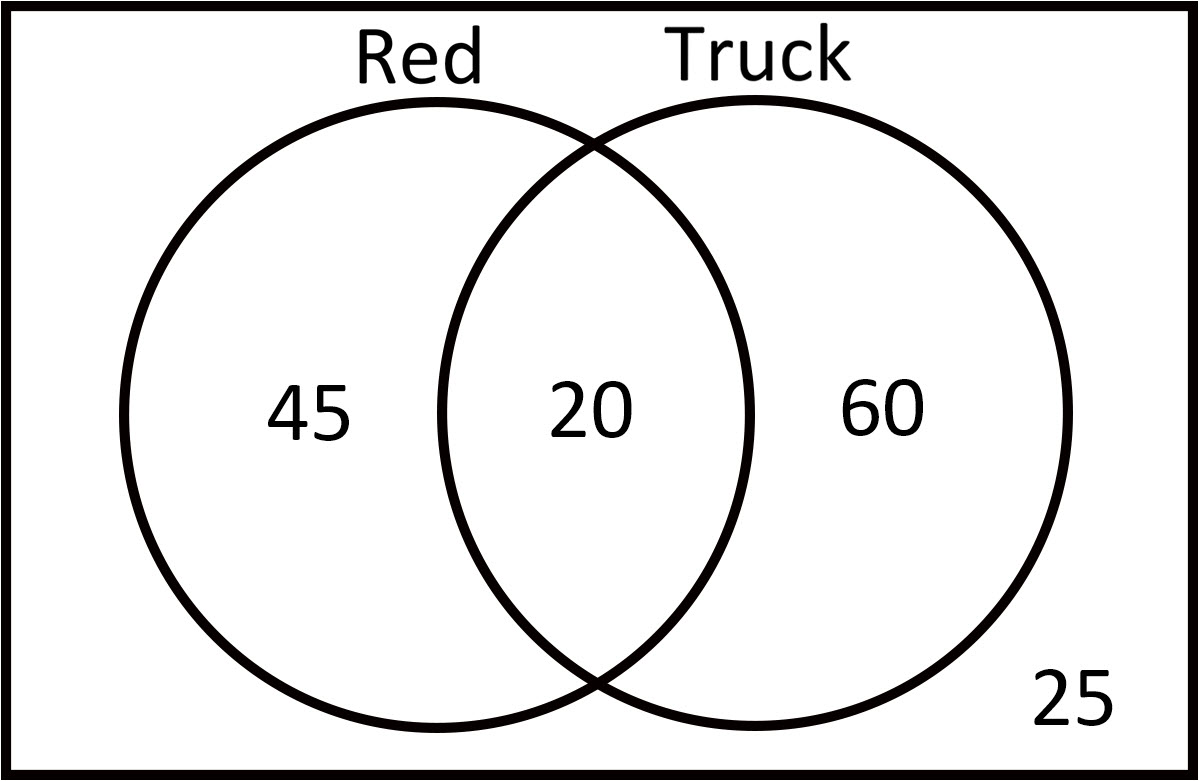
P(Red|Truck) = 20 / 80 = .25
Name and briefly describe 2 of the 3 regularization techniques we discussed to use with neural networks.
l1 & l2: changes the loss function to add a penalty term
Dropout: randomly drop units (nodes) in our neural network during our training phase only. We assign a probability of each node disappearing. Then, we essentially perform a coinflip for every node to turn that node "on" or "off."
Early stopping: stops the training process early. Instead of continuing training through every epoch, once the validation error begins to increase, our algorithm stops because it has (in theory) found the minimum for the validation loss
What is the importance of A/B testing?
What are the two types of supervised learning models and what is the difference?
What book should obviously be your favorite now? (Full name!)
Introduction to Statistical Learning in R (ISLR)
Two production lines produce the same part. Line 1 produces 1,000 parts per week of which 100 are defective. Line 2 produces 2,000 parts per week of which 150 are defective. If you choose a part randomly from the stock what is the probability it is defective? If it is defective what is the probability it was produced by line 1?
P(L1|D)=25
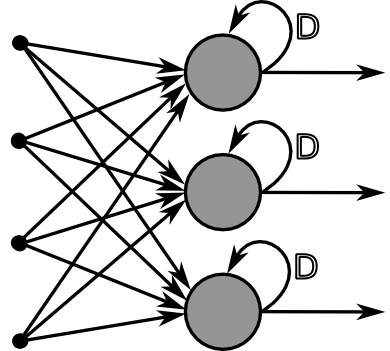
What kind of Neural Network has node layers that get information from the previous layer as well as from itself?
Recurrent Neural Network
When should you scale your data? Why?
When your algorithm will weight each input, e.g. gradient descent used by many neural nets, or use distance metrics, e.g. kNN, model performance can often be improved by normalizing, standardizing, or otherwise scaling your data so that each feature is given relatively equal weight.
It is also important when features are measured in different units, e.g. feature A is measured in inches, feature B is measured in feet, and feature C is measured in dollars, that they are scaled in a way that they are weighted and/or represented equally.
In some cases, efficacy will not change but perceived feature importance may change, e.g. coefficients in a linear regression.
Scaling your data typically does not change performance or feature importance for tree-based models since the split points will simply shift to compensate for the scaled data.
Describe the bias/variance tradeoff. What does it have to do with under- and over-fitting?
Bias refers to an error from an estimator that is too general and does not learn relationships from a data set that would allow it to make better predictions. Variance refers to error from an estimator being too specific and learning relationships that are specific to the training set but will not generalize to new records well. In short, the bias-variance trade-off is a the trade-off between underfitting and overfitting. As you decrease variance, you tend to increase bias. As you decrease bias, you tend to increase variance. Your goal is to create models that minimize the overall error by careful model selection and tuning to ensure sure there is a balance between bias and variance: general enough to make good predictions on new data but specific enough to pick up as much signal as possible.
Who is Matt Brems's professional role model? (hint: fictional is fine)
Miranda Priestly from Devil Wears Prada
What is the probability that a student has a bird given that they have at least two types of pets?
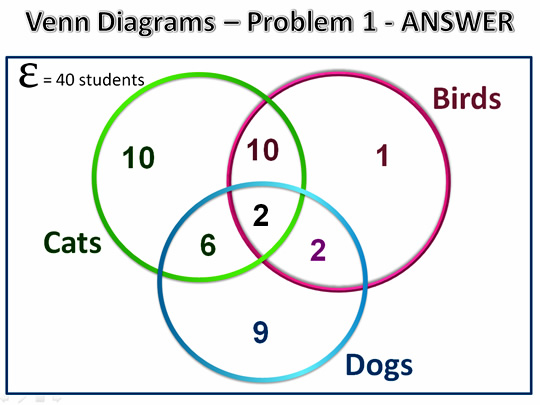
P(Bird | 2 types) = (10+2+2)/(10+2+2+6) = 14 / 20 = .7
Which activation function is typically used in hidden layers? Why?
ReLU because it tends to perform the best. It improves upon the Sigmoid activation function by turning "off" the node (setting to 0) for values below 0, similar to how neurons in the brain remain inactive until they need to be fired.
What are the axes on a ROC curve?
Which one is Riley's last name and which is the city he lives in?
You are interviewing for a data scientist role with Lyft. Your interviewer asks "We want to use an A/B test to determine whether adding a mini-game feature to the app after a user requests a ride will reduce the number of cancellations. Which of the following would you do?"
Select all that apply:
A. Randomly assign users to the control group (no mini-game) and the treatment group (with mini-game)
B. Assign all users who have had been using Lyft for at least 3 years to the mini-game
C. Define your parameter of interest before conducting the experiment
D. Stratify (aka block) on age as well as other important user characteristics that are likely to influence the outcome
A, C, (D)
The problem you are trying to solve has a small amount of data. Fortunately, you have a pre-trained neural network that was trained on a similar problem. Which of the following methodologies would you choose to make use of this pre-trained network?
A. Re-train the model for the new dataset
B. Assess on every layer how the model performs and only select a few of them
C. Fine tune the last couple of layers only
D. Freeze all the layers except the last, re-train the last layer
Describe what principal component analysis is and when you would want to use it?
Walk through how a decision tree works
Can you remember last week? Name all the global instructors' dogs